Why might you need to know about masking? The answer is that it is one of the ways that you can anonymize data so that you can then responsibly test with, or develop with data that contains sensitive or personal information.
Even if you are responsible for a database that has full access-control and security in place, you may also need several data masking techniques to support an application.
You might, for example need dynamic masking to ensure that applications do not unnecessarily expose sensitive information.
Alternatively, you might need to mask the actual data if you need to run tests or development work on the actual production data and it includes personal or sensitive data.
You also need masking techniques that pseudonymize data if you are required to “push production data to a lower environment” – to distribute your data for reporting or analysis and the underlying data needed for the report must be preserved.
For the purposes of training or user-acceptance tests, it is more usual to generate fake data that looks like the real data. This is a rather different process, requiring a different skill-set.
Why mask data?
The various rules about data apply to any database, flat file, or spreadsheet. From the legal perspective, it doesn’t so much matter how and where you hold the data.
If you are part of an organisation, you should be able to access only that information that is appropriate for your role within it. If you have no legitimate reason to access that data, it must be inaccessible to you.
To summarise:
All data has to be curated responsibly, wherever it is held.
The law doesn’t care what method you use to store the data responsibly, as long as it is done so.
It must have access control at all times if it includes data that can identify an individual (PII Data) Also, the legislation avoids giving directive advice about how you anonymize or pseudonymize data. It just demands that is done whenever appropriate.
The legislation requires that it is impossible to identify any individuals or groups in anonymized data, even if it is combined with other data sources. How you actually achieve that for your data is your concern, and the technology to do so is wisely not defined in the current legislation.
If it is possible to identify individuals via re-identification or de-anonymization, then the data isn’t properly anonymized. This re-identification technology has been used for years by law-enforcement agencies and intelligence services to crack criminal networks, and one can be sure that the dark web has the same technology.
Masking and MongoDB
Because the way that you hold and process your data is irrelevant to the law, MongoDB presents the same challenges as any other data format.
Because MongoDB does not enable access control by default, the first, and obvious, step is to provide role-based access control and security of both the database and its server.
However any data document, whether unstructured text, YAML, JSON or XML has particular problems for anyone tasked with anonymizing it. Unless you include a schema, and a disciplined approach, the sensitive data can be anywhere and it can be repeated in several places.
You can get the same problems in relational data that has ‘denormalization’ or includes an XML or JSON column. If you check, you can often find that the same data is in several places, and where you have two of these with the same name, and neglect to mask them, you have a potential breach.
MongoDB is based on the concept of collections. A collection, like a relational database table, contains one or more documents. Each document is a set of key-value pairs.
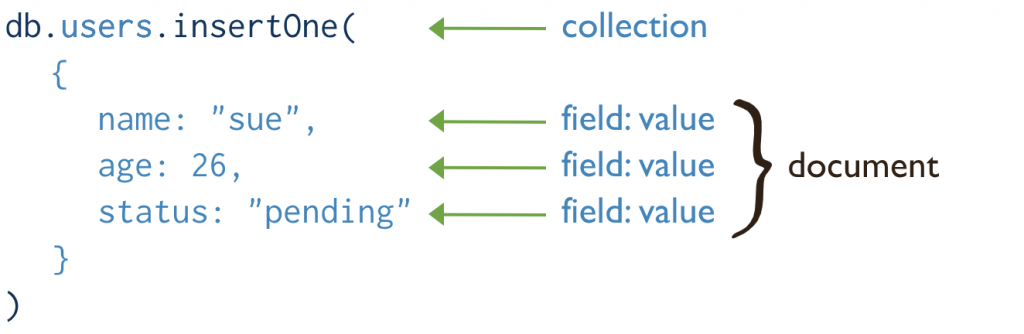
Documents in the same collection do not need to have the same set of fields or structure, so fields with the same name in a collection’s documents may hold different types of data. They can hold arrays which can contain all manner of data.
Basically, schemas are very rarely enforced in MongoDB. This makes it more difficult to produce a systematic automated masking procedure. In fact, where there is no consistent schema, the process of defining the mask can become remarkably tedious.
To achieve masking, it is possible to use MongoDB’s read-only non-materialized views, field-level redaction or field-level encryption.
Views are the simplest way of doing it because they are based on the aggregation pipeline and so it is possible to create quite elaborate filters of a collection. You would need to host these on the production database and use them to export the redacted data.
However, although these can achieve pseudonymization, they require quite a lot of programming, assume a reasonable enforcement of a schema, and don’t meet all the requirements.
Pseudonymization, anonymization, aggregation, masking and data generation
There is a whole spectrum of techniques for making data anonymous. The most suitable choice depends on the reason you need to anonymize the data.
- If data is required for development work, then any identifying data must be masked.
- For training or user-acceptance testing, the data must also be realistic.
- For testing the resilience and scalability of data, data generation is the most sensible approach to providing the necessary data.
Aggregation
If the data is for reporting, then a great deal can be achieved merely by providing an aggregation at the lowest level required for the report.
If, for example, it is for reporting on a trading, and the most detailed report is for a day’s trading, then the data can be provided merely for every day.
Aggregated personal data can be re-identified if some of the groups have low counts. This has happened with open data medical information and crime records.
Masking
Dynamic masking is different from static masking in that it is done to the result of a data query. It is only effective where the destination has access controls that prevent ad-hoc lookups/joins.
Different database systems do dynamic masking in different ways, but MongoDB uses the view and the redact projection.
The advantage of dynamic masking is that it avoids upsetting the application logic that constrains the data.
If you were to put *** in the actual numeric data, it can fail a constraint in the JSON Schema because it no longer looks like a number.
It gets even more complicated if you have a phone number, zip code or card number because validation of a number masked with digits could fail if the checksum or special validation rules are broken.
Pseudonymization
Pseudonymization is a data masking technique where individuals might need to be re-identified.
If, for example, a hospital needs to have an analysis done of the likelihood of certain pathology, or optimal treatment, based on medical history, the report must have personal details masked in a way that they can be re-identified.
The most obvious was would be to leave a ‘surrogate’ key in the necessary medical information in the place of the personal (PII) information which can then be used to re-identify the individual patients from the subsequent report.
This security can be defeated if personal information ‘leaks’ into the medical information and it is not considered in law to be equivalent to anonymization.
Data generation
Data generation is used for application testing and training: Where an application is not yet released, it is the only way of doing so.
It may seem simple, and it would be except that information in fields are likely to be related. Customers will have information that is logically-consistent and probably gender-related, dates may need to be before or after other dates and will need a realistic span.
Data masking in Studio 3T
Data Masking in Studio 3T is an obvious extension to its ability to edit and manipulate MongoDB data, and it is usefully combined with its “Reschema” facility. This will tell you a great deal about the location of the data.
Data masking is done by a “task” in the same manner as any other repeatable job, and can be saved, scheduled and edited.
To access the data masking, you right-click on the collection you wish to mask and click on “Mask Collection” in the context menu that appears.
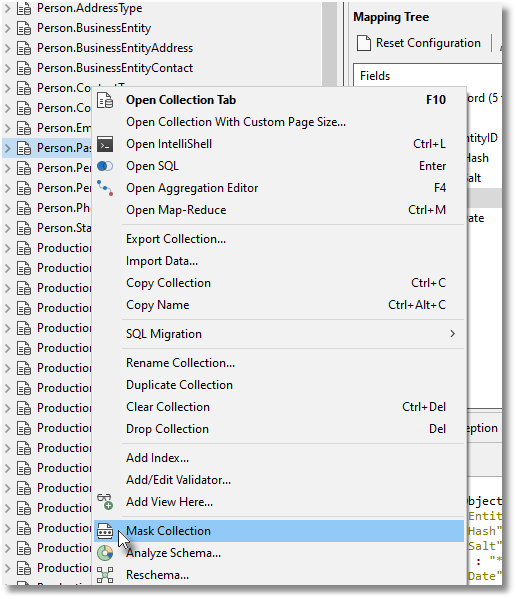
A task consists of one or more “units”, each of which manages the masking of a collection.
A “unit” allows you to mask entire collections and decide which fields should be obfuscated. You can either mask the original collection or save it as a new collection.
In its first incarnation, it concentrates on “masking-out” techniques that are commonly used with dynamic data masking. You can’t yet do Shuffling, Synchronization or Substitution. The type of masking depends on the datatype of the field.
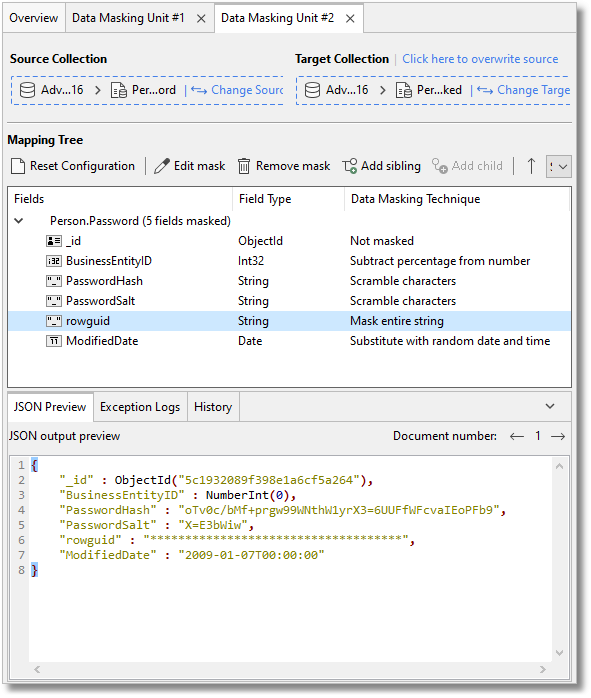
One of twenty different data types can be selected and the type of masking or obfuscation depends on the data type.
Arrays can, for example, be excluded, nulled or emptied.
Strings are either partly or wholly replaced with a character such as the hash (#) or star(*) character.
Integers can be varied from the original value as either a varying or fixed percentage of the original value, or they can, instead, be replaced with a fixed value.
Dates can be given a random value between a range you can define.
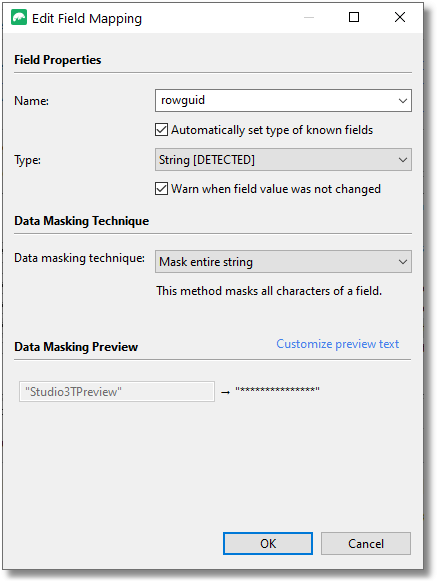
This is straightforward for a database with just a few collections that conform to a schema, but because each field is done entirely separately, and there aren’t user-definable defaults for the values you need to give for the method you choose, (for example, the variance of an integer) it isn’t quick with a large database.
This first iteration of masking is sufficient for most purposes, but if it is done effectively, your data won’t look so pretty and it isn’t likely to have the same distribution. However, it is effective.
Those of us who take an interest in data obfuscation take some pride in obfuscating text in such a way that it will seem like the real data, and even pass constraints and schema-validation rules. This is, actually, only required for training, user-acceptance, or performance testing.
The masking provided by Studio 3T provides enough, in its first iteration, to allow data to be masked for ordinary development work and for ‘downstream’ reporting.
Conclusions
When you are developing, maintaining or testing a data-driven application, it is so much easier if there is an abundance of data. Many issues, particularly performance, only surface when there is plenty of data.
Application design is quickly honed by trying ideas out on large datasets. If you have an existing application, It is always tempting, and sometimes necessary, to use the live data for all this.
The facility for masking data must be part of the toolkit of any developer who is dealing with data. It is a great help in ensuring that you are dealing responsibly with live data. However, it is just one essential tool in the database developer’s armoury for meeting the requirements of an organisation whose business depends on data.
To meet the demands of society, it must be used along with data generation, encryption, aggregation, and access control in order to protect sensitive and personal data.