
Imagine you work for a small business that just boomed with that one TikTok or Instagram reel, resulting in the application being flooded with requests, just as your team is preparing to launch new updates to the product.
The single database instance that once ran smoothly comes crashing down as your product catalog and customer base expand. Query response times increase, user experience suffers, and scaling vertically (adding more resources to a single server) proves both unsustainable and costly.
As your data scales, so do the challenges. If you’re a technical decision maker, you need a more efficient way to scale MongoDB that addresses performance bottlenecks and delivers a better user experience.
Horizontal scaling with sharding may be the answer. It transforms the database architecture, increases throughput, improves performance, and enhances high availability.
In this post, we’ll explore how MongoDB’s sharding capabilities can help you overcome bottlenecks, compare horizontal and vertical scaling, and share best practices to help you scale with confidence.
The difference between horizontal and vertical scaling
It’s important to understand how horizontal and vertical scaling differ and why horizontal scaling is often a better long-term strategy.
| Parameter | Horizontal scaling | Vertical scaling |
| Load distribution | Distributes the load across multiple servers | Improves the performance by upgrading the hardware being utilised |
| Example | Adding virtual machines (VMs) in a cluster | Adding memory capacity of existing VM |
| Workload distribution | Distributed across different nodes | A single node handles the workload |
| Concurrency | Since the workload is distributed, it becomes easy to handle concurrent requests | Multi-threading is responsible for concurrency |
| Complexity | High | Low |
| Costs | Optimal over time | Less cost-effective |
| Failure resilience | Lower as other nodes have the backup | Single point of failure |
As you can see, in certain scenarios, vertical scaling is inefficient due to reasons such as:
- When the CPU limit is reached, no further vertical scaling is possible.
- A single point of failure could result in application failure and downtime.
- The interrelation between performance and cost becomes exponentially worse.
- Setting up global users from a single server location introduces latency issues.
Factors like cost, future growth, reliability, flexibility, and the complexity of the application should be considered when deciding between horizontal and vertical approaches.
What is sharding in databases?
Sharding is a way of distributing data across different machines to reduce load and improve performance. Instead of relying on a single machine to store and serve your data, the database administrator (DBA) makes the decision to divide the data into small, manageable pieces called shards. This enables:
- Managing only a subset of reads and writes on each shard, rather than the complete application.
- Parallel operation of queries across different shards.
- Greater scalability and high availability.
MongoDB supports horizontal scaling using sharding in high-growth scenarios, by distributing data across a sharded cluster, making it a practical choice for applications that need to efficiently handle large volumes of data and user requests.
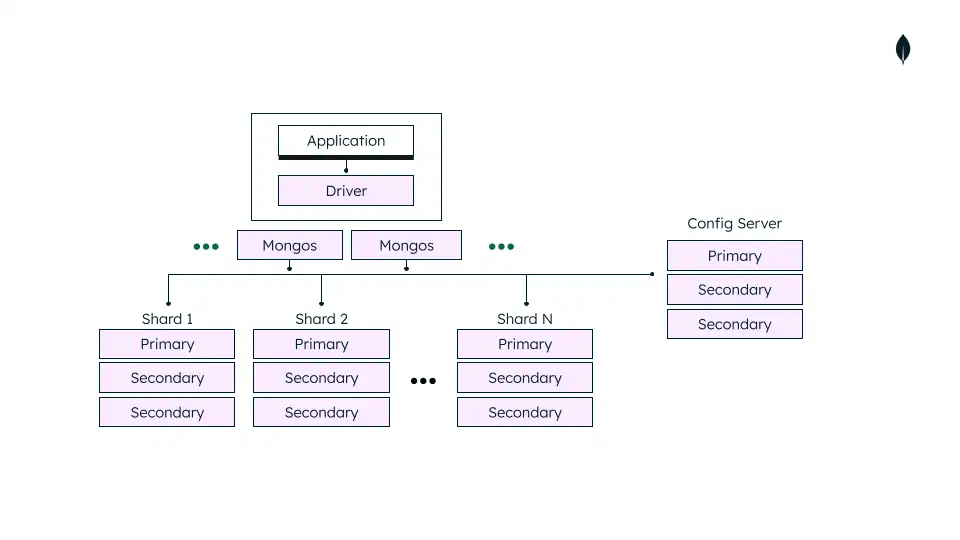
Inside a MongoDB sharded cluster
A sharded cluster includes the following components:
- Chunks: The smaller pieces of the dataset that MongoDB divides and distributes across shards. Shards are the servers (or replica sets) that store these chunks.
- Mongos: The routing service that directs queries to the appropriate shard.
- Config servers: Manage the metadata and configuration settings for the cluster.
- Shard keys: The key parameter to divide the dataset into shards. Choosing the right shard key is crucial for effective sharding.
Visualization tools can provide engineering teams with a clearer view of the data structure to help make more informed decisions when selecting a shard key. These can also be useful if it becomes necessary to refine or even change a shard key (although it isn’t good practice to change these often).
Here’s how sharded cluster architecture looks in production:
How to create a sharded cluster
To create a sharded cluster on a local deployment, follow the steps in the official MongoDB documentation. Maintaining this isn’t as daunting as it seems, and MongoDB Atlas’ fully-managed sharded cluster setup offers a streamlined process.
With MongoDB Atlas, you can deploy a sharded cluster in just a few clicks, and the platform handles all aspects of maintenance, including monitoring, backups, and automatic scaling. This allows you to focus on developing your application without worrying about the underlying infrastructure.
Database management tools such as Studio 3T integrate seamlessly with MongoDB Atlas sharded clusters, allowing development teams to visualize sharded data and build complex queries efficiently.
Monitoring and balancing a sharded cluster
Managing a sharded cluster is essential for achieving optimal application performance. After a collection is sharded, MongoDB distributes data across the available shards based on the chosen shard key.
Selecting the right shard key is crucial, as it directly affects the risk of creating hot shards and jumbo chunks. Poor shard key choices, such as those with low cardinality or monotonically increasing value, can lead to uneven data distribution, causing certain shards to become overloaded while others are underutilized.
To help manage and balance these chunks, the MongoDB Sharded Cluster Balancer continuously monitors the amount of data stored in each shard for every collection and automatically redistributes chunks as needed to maintain an even workload across the cluster.
It’s important to regularly analyze your shards and monitor data distribution, using both the balancer and monitoring tools. This helps ensure an even workload and prevent performance bottlenecks, and validate that the balancer is working as intended.
To shard or not to shard?
When to shard
Ideal scenarios for sharding include:
- Rapid data growth: When your data outgrows the storage capacity of a single server.
- High throughput: When you need to handle high read and write rates that a single replica set cannot support.
- Scalability requirements: If your application is expected to grow significantly in users or traffic, sharding allows you to scale out and manage increased load efficiently.
When not to shard
It’s equally important to understand when sharding is unnecessary or could introduce more problems than it solves. Making the right decision starts with understanding the following points:
- Small database size: If the database is relatively small and fits within the storage of a single server, there is probably no requirement to shard the collection.
- Shard key selection: Choosing the right shard key is critical. A poor choice can result in jumbo chunks and might not help improve application performance.
- Scatter-gather queries: An inappropriate shard key can result in scatter-gather queries, where operations are sent to all shards, negatively impacting performance.
- Operational complexity: Managing the backups and restores in a sharded collection is more complex compared to a non-sharded collection, making maintenance more challenging.
- Multi-cloud latency: Sharding across a multi-cloud environment can result in latency issues between shards.
Data comparison and export tools allow teams to more easily manage and move data, simplifying testing, backup validation, and inter-shard consistency checks.
Sharding best practices
Whether your sharded cluster is deployed locally or on-prem, you should:
- Select the right shard key: Choose a shard key with high cardinality and one that matches your query patterns. This helps with even data distribution and efficient read and write operations.
- Avoid scatter-gather queries: Structure your queries and shard key selection to avoid operations that must query all shards, as these can significantly impact performance.
- Use hash-based sharding when appropriate: Hash-based sharding can help achieve a uniform distribution of reads and writes, minimizing hotspots and jumbo chunks, especially for write-heavy workloads.
- Plan for growth: Add new shards before existing shards become overloaded, to maintain performance and scalability.
It’s worth testing the effects of different sharding strategies by using tools to analyze performance and validate data distribution. This enables you to make smarter, safer scaling decisions as your application, data, and access patterns evolve.
As modern-day applications scale rapidly, it’s vital to ensure the database can keep up. Horizontal sharding in MongoDB offers a powerful way to scale, distribute storage, and balance compute load across multiple machines. As your application scales and your data grows, knowing when to move from a single-node setup to a sharded cluster can make all the difference in performance and reliability.






