In this article, we’ll go through the basics of MongoDB find, the method used to query documents and fetch documents from a MongoDB collection.
We’ll go through a few query examples using Studio 3T and the Customers dataset.
What is MongoDB find?
The find() method in MongoDB selects documents in a collection or view and returns a cursor to the selected documents. It has two parameters: query and projection.
db.collection.find(<query>,<projection>)
- the first ‘query‘ (or filter) parameter specifies the search
- the second optional ‘projection’ parameter specifies what parts of each matching document are returned
Three ways to build find() queries in Studio 3T
For writing and building db.collection.find() queries, we’ll be using Studio 3T’s IntelliShell with query auto-completion in our examples.
If you don’t know the MongoDB Query Language, you can still build find() queries through a drag-and-drop Visual Query Builder. Simply drag the fields, define the value, and hit Run.
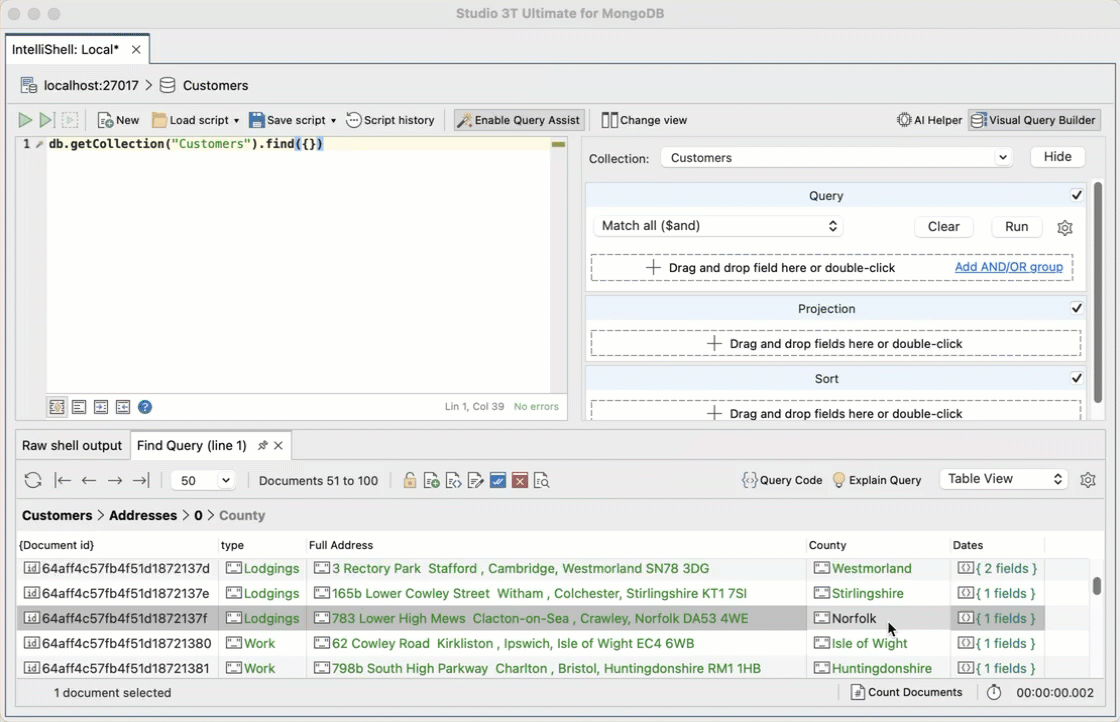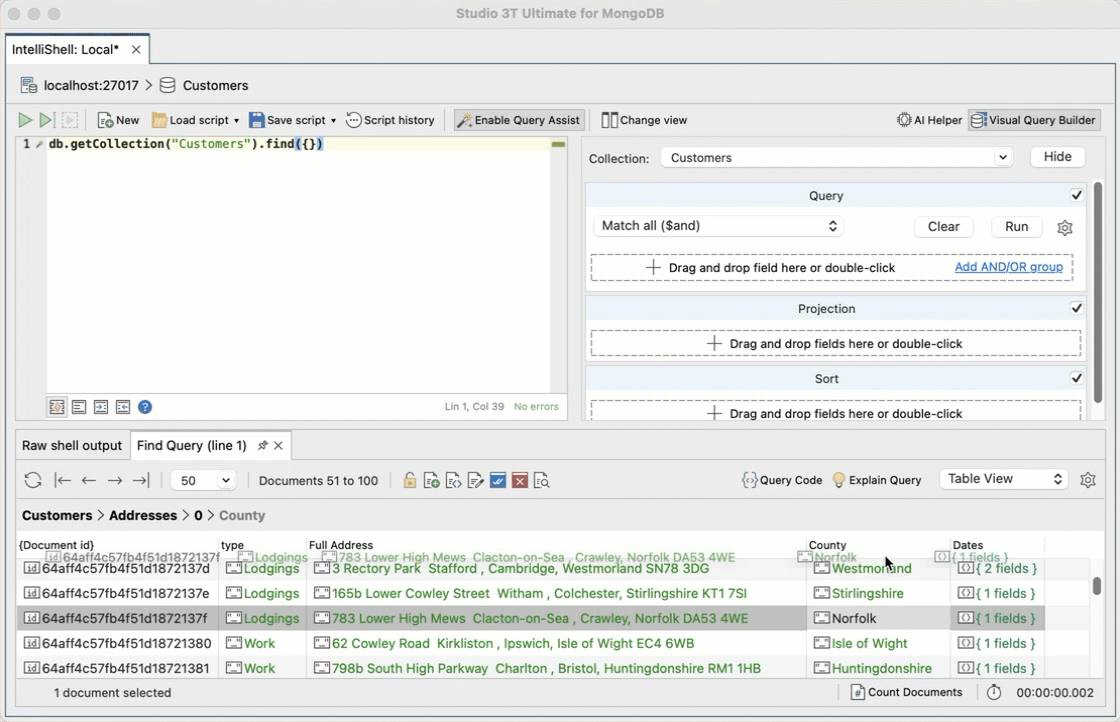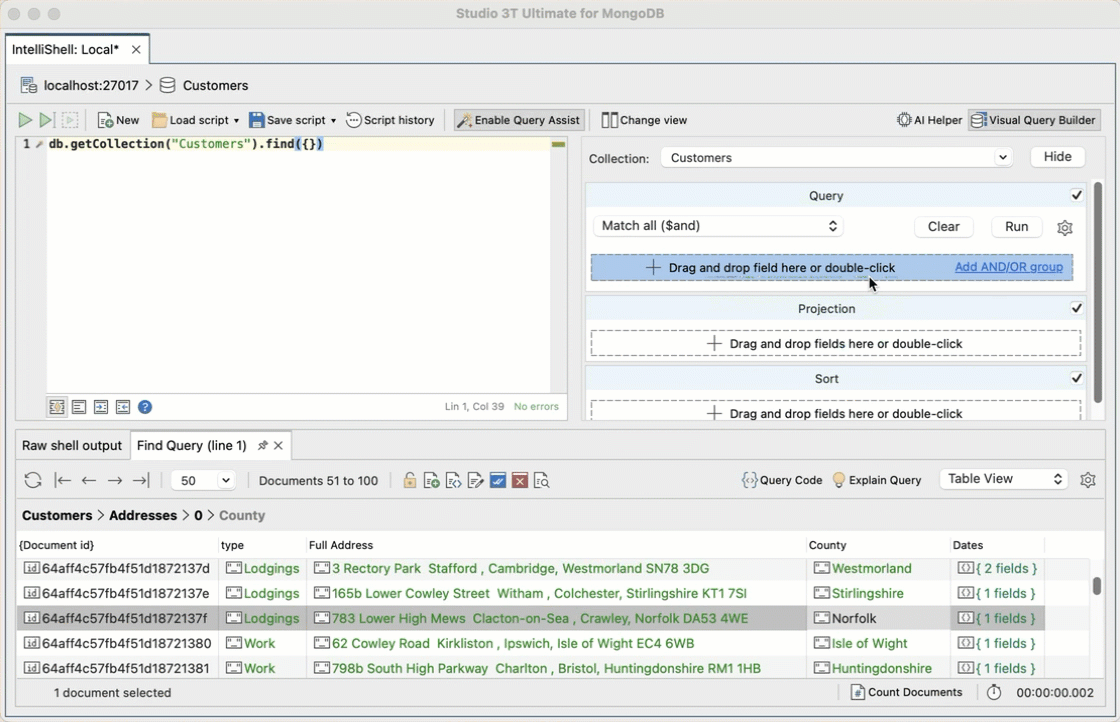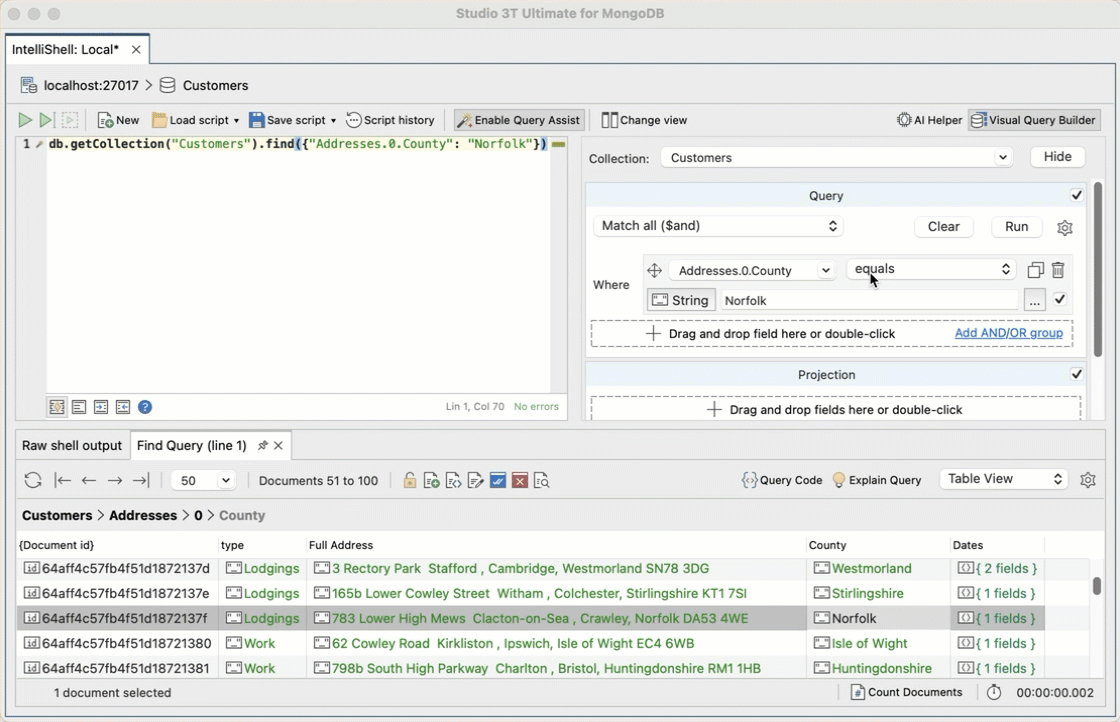
If you’re fluent in SQL and want to save a bit of typing, Studio 3T also has SQL Query, which lets you use SQL to query MongoDB find queries.
Import the Customers collection
Open Studio 3T and connect to your MongoDB database.
Next, open the Import Wizard by clicking the Import button in the toolbar.

On the Import dialog, select JSON as the import format, then click Configure.
Click + Add source to choose the JSON source documents.

Next, we will specify the target database and target collection by double-clicking the cells below the column headers. We are naming ours Customers. Note the capital C!
Under Insertion mode, double-click the cell to choose one of the insertion modes from the drop-down menu.
Click Run to run the import. You should see the new collection in the connection tree, on the left.
Find() method examples
Now we’re ready to try out examples of the find() method that you can type/paste and edit in IntelliShell.
Let’s open IntelliShell by clicking the button in the toolbar.

And try the following queries.
Return all documents in a collection
db.Customers.find() //returns all documents in the collection
When the query and projection parameters are not specified, the find() method returns all documents in the collection.
Return documents that match the given query criteria
db.Customers.find({
'Addresses.County': 'Norfolk'
})
//returns the documents that have an address in the county of Norfolk
This query simply returns the documents that contain an address in the county of Norfolk. There is a filter parameter but no projection is specified so the whole document with all the fields is returned.
Return documents with only the specified fields (projection)
Here we have specified a list of the fields that we want returned as the projection parameter.
db.Customers.find({
'Addresses.County': 'Norfolk'
}, {
'_id': 0,
'Full Name': 1,
'Addresses.
The customer may use several addresses at once (work, home, etc.), and he may move about, so we have chosen to just return the matching address (‘Addresses.$’), along with the name of the customer (‘Full Name’). For this query, that is all the data we need, so why retrieve more than necessary?
Return documents with multiple matching criteria
What if you want to search in more than one county?
db.Customers.find({
'Addresses.County': {
$in: ['Essex', 'Suffolk', 'Norfolk', 'Cambridgeshire']
}
})
//customers whose address is in East Anglia
The filter allows more than simple equality with a value to select documents. In this case we’ve listed several values to check for using the $in comparison query operator.
There are several others with fairly obvious meanings, such as $eq (==), $gt (>), $lt (<), $gte (>=), $lte (<=), $ne (!=) and $nin (not in).
There are also the range of logical operators. There are plenty of other MongoDB query and projection operators that allow you to do quite complex filters, but that’s another topic!
Using the cursor methods
The MongoDB find method doesn’t actually return the data despite the fact that, by default, the mongo shell prints out the first twenty rows when it executes the find() method.
It is a cursor to the documents that gets passed back. It holds a reference to the documents that match the query criteria that you pass to the find() method. This allows you to specify what processing you want on the returned data.
There are a number of these cursor methods.
count()
The count() cursor method is useful for returning the number of documents that meet the criteria.
For example, in our customer database:
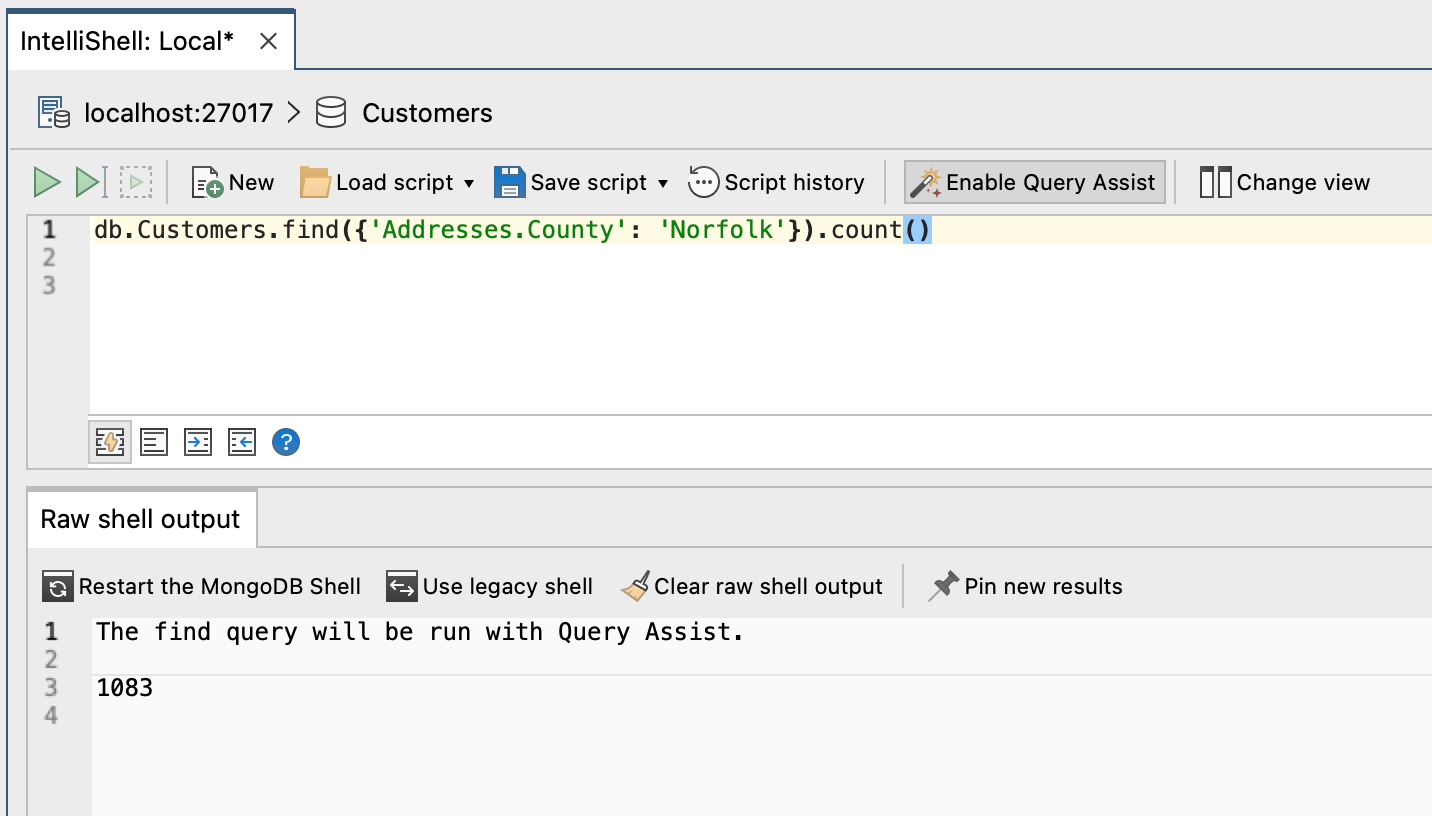
db.Customers.find({'Addresses.County': 'Norfolk'}).count()
shows how many customers have an address in Norfolk County.
limit()
The limit() cursor method limits the number in the result to the value you pass, so that
db.Customers.find({'Addresses.County': 'Norfolk'}).limit(1)
returns just the first customer.
skip()
There is also a skip() method so you can easily implement a scrolling window in the application.
db.Customers.find({
'Addresses.County': 'Norfolk'
}, {
'_id': 0,
'Full Name': 1
}).sort({
'Name.Last Name': 1
}).skip(10).limit(20)
As you’ll have noticed, you can stack these methods up and use pretty()
db.Customers.find({'Addresses.County': 'Norfolk'}).limit(1).pretty()
to return the document in an easy-to-read format.
The skip() and limit() methods make little sense without the sort() method because results are best assumed to be unordered otherwise.
The toArray() method is powerful magic, because it creates a JSON array from all the documents specified by the cursor. It is the easiest way to pass results to the application.
MongoDB find() exercises
Follow step-by-step exercises on how to run find statements on Academy 3T, home of our free MongoDB 101 and MongoDB 201 courses. The lesson on the The MongoDB find method has you covered.