With Query Profiler, instantly find slow queries using the MongoDB database profiler, visually check for missing indexes, and fix query code, so you can speed up response times in your application. Comprehensive diagnostics show you query execution times, frequency, and query code, so you can tune MongoDB performance issues fast.
Watch the video below to learn how to troubleshoot slow queries and improve query speed:
What is the MongoDB Database Profiler?
The MongoDB Database Profiler captures and logs data about operations, for example:
- operation type, such as find and aggregate queries, updates, inserts, deletes, or administration commands
- execution time
- namespace (a combination of the database name and collection name)
- query code (the query document)
The Query Profiler uses this data to identify slow queries, so that you can optimize MongoDB performance by improving query code, and adding indexes or changing the fields in existing indexes.
The MongoDB Database Profiler stores the data in the system.profile collection. You can view the system.profile data in Studio 3T, just like any other MongoDB collection, but it’s not easy to extract collection, filter, and option data for find and aggregate queries in a meaningful way. Studio 3T’s Query Profiler extracts and analyzes the profiling data so that you can understand why your queries are running slowly and shows you the query code for find and aggregation queries so that you can fix them and improve MongoDB performance.
Opening the Query Profiler
To open the Query Profiler and start monitoring MongoDB performance:
- Global Toolbar – Locate the database you want to profile in the connection tree and click the Query Profiler button
- Right-click – In the connection tree, right-click the database you want to profile, and then select Query Profiler.
- Right-click – In the connection tree, right-click a collection, and then select Query Profiler. This does not mean that you’ll be profiling data at collection level. You’ll be working with the entire database.
The Query Profiler opens in a new tab. By default, the profiler is switched off. To switch it on and start profiling MongoDB queries, click the Profiler switch.
Using the Profiler switch enables the MongoDB Database Profiler and sets the profiling level to 1.
The profiling levels are as follows:
- Level 0 – The Profiler is off and is not collecting data. You can continue to work with the profiling data that has already been collected.
- Level 1 – The Profiler collects data for find and aggregation queries that take longer than 100 milliseconds.
- Level 2 – The Profiler collects data for all operations. You can’t set the profiling level to 2 in the Query Profiler but you can use IntelliShell or the MongoDB Shell to do this.
The MongoDB Database Profiler logs slow operations with:
- a slow operation threshold of 100 milliseconds
- a filter for find queries and aggregation queries
The Query Profiler does not allow you to change the profiling level, for information about how to do this in mongosh, see Configuring the MongoDB profiler.
Switching off the Query Profiler
Remember to switch off the profiler when you’re not monitoring MongoDB database performance to prevent unnecessary overhead, especially in production environments.
When the profiler is switched off, you’ll still be able to view the profiling data that has already been collected.
To switch off the profiler, click the Profiler switch.
Viewing slow queries in MongoDB
The Query Profiler shows the slow queries identified by the MongoDB Database Profiler.
By default, the items in the list are sorted by Most recent occurrence, so if you’re investigating MongoDB performance issues in real-time on a live database, the slow queries that you need to troubleshoot are shown at the top of the list.
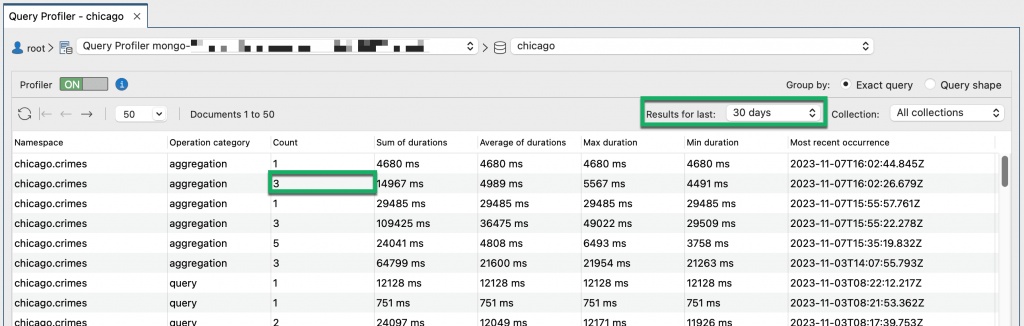
Count shows how often the query ran for the timeframe that is selected in the drop-down list. In the screenshot above, the query ran 3 times in the last 30 days.
You can group the slow queries by Exact query or Query shape. We’ll use the simple queries below to explain these groupings:
Exact query shows unique queries based on field names and field values. In the simple queries above, the queries have different values, so the Query Profiler interprets them as different queries and does not group them.
Query shape shows groups of queries with the same logical structure but ignoring field values. In the simple queries above, MongoDB maintains a single query shape for each of the 3 queries, for example db.customers.find({"firstname": <String>}), and generates a hash for the query shape. MongoDB writes the hash values to the queryHash field in the system.profile collection. In the Query Profiler, you can see the hash value in the Query hash column when you group by Query shape.
When you group by Exact query, you can see if a query is a find query or an aggregation query in the Operation category column.
To filter the list:
- for a particular collection in the database, select the Collection from the list
- by when the slow queries ran, select a timeframe from the Results for last list. When Query Profiler does not show any slow queries, you may find that going further back in time and selecting a broader timeframe retrieves profiling data.
Drilling down and interpreting the profiling results
You can drill down and see the profiling data for each slow query in a group. So if a query ran 6 times, as indicated by a value of 6 in the Count field in the top panel, the bottom left section of the Query Profiler shows 6 items.

You can see how long each query took to run and when each query ran by looking at the Duration and Timestamp fields.
Keys Examined shows the number of index entries that have been scanned. If Keys Examined is zero, select the query and click the View Full JSON button to check the planSummary key value. If the planSummary value is COLLSCAN, MongoDB has performed a full collection scan and this confirms you need to create indexes on your collection to improve MongoDB performance. Or, a faster way of checking index usage is to click the Explain plan tab to see if MongoDB performed a collection scan or an index scan.
Viewing the full JSON format
The Query Profiler shows only the most useful profiling data captured by the MongoDB Database Profiler, so that you can see potential performance problems at a glance. If you need to investigate further, you can view all the profiling data that is stored in system.profile for a query, by clicking the View Full JSON button.
Query Code
The Query Code tab shows the query in MongoDB Shell language and it’s from here that you can debug and fix the slow query.
You can debug the code in Intellishell, by clicking Open in IntelliShell.
For find queries, you can debug the query in the Collection Tab, by clicking Open in Collection Tab.
For aggregation queries, you can debug the query in the Aggregation Editor, by clicking Open in Aggregation Editor. The Aggregation Editor makes it easier to troubleshoot the slow query by showing you the input data and output data for each stage in turn.
Explain plan
Explain plan is a visual representation of the performance of a MongoDB find query. It shows the query plan and the steps MongoDB took to run a query, with runtime statistics for each step.

Explain plan is useful for checking if a query is using an index. If it is not using one because MongoDB has performed a collection scan, and you want to create an index, locate the collection in the connection tree, right-click, and select Add Index. To find out more, see Adding an index.
If the query is already using an index, check that the query is filtering as much data as possible first of all. For a detailed explanation, see Optimize queries by applying relevant filters.
FAQs about MongoDB performance tuning with Query Profiler
Learn more about optimizing MongoDB queries
Watch Roman Right demonstrate practical tips to make queries faster, diagnose slow queries, and how to write a focused aggregation query. Find the series of videos on our blog.
Learn more in our Knowledge Base:
- How to speed up MongoDB queries with Studio 3T’s performance tools for tips on improving MongoDB query performance
- MongoDB Indexes | A Complete Guide and Tutorial to boost MongoDB performance by creating indexes with Studio 3T’s Index Manager
- Visual Explain | MongoDB Explain, Visualized to help you understand the execution plan and analyze query performance