In the past five years, the relational ‘big beasts’ such as SQL Server, MySQL, PostgreSQL, and Informix have mostly added JSON as a data transfer medium.
This doesn’t just mean that the relational database will import tables, views, or queries in JSON format, but also that it will, if necessary, accept and shred JSON as parameters to procedures and functions, and pass back results as JSON.

Document databases, such as MongoDB, CouchDB, and ElasticSearch, that use a binary extension to JSON as storage are rather different because they avoid the inherent complexity of normalized tabular storage by compromising the principle of holding data in one place only.
Where data is high in volume but ephemeral and fairly unstructured, this type of database will always be faster to ingest and store data.
For the JavaScript full-stack programmer, there is an obvious advantage in having all the layers of an application using the same language and conventions. This is a great attraction of the MEAN stack (MongoDB, Express.js, AngularJS (or Angular), and Node.js), and this sort of compatibility is the obvious choice to get a self-contained application up and running because the programmer can concentrate on the logic without having to cross a cultural border such as the object-relational divide.
As applications mature and become more essential to the organization or community that uses it, so the data has to contribute to the data flows, analysis, and reporting requirements of that organization. Increasingly, the data handlers of organizations are using different types of databases that suit the requirements, such as relational, OLAP, document, KeyValue, Column-Oriented, and graph databases, so long as they can coexist.
JSON Growth Pains
JSON was initially devised as a reaction to the intimidating complexity of XML.
At first, JSON seemed to be more of a satirical statement. It had no standard for representing some of the most essential data types such as dates, locations, byte-arrays, or BLOBs.
JSON objects are inherently unordered with no way of representing ordered attributes or lists. There was originally no standard for representing schemas or constraints.
You could use it for transferring data in the same way as you would use CSV for tables: both ends had to know the schema and constraints. There was no way of querying the contents of the document other than by rolling your own conventions using JavaScript.
Several initiatives are sorting out this problem. MongoDB uses Extended JSON in strict mode or shell mode in order to represent such datatypes as dates, binary data, timestamps, Regex expressions, IDs, long integers, and decimal numbers (see Extended JSON spec).
Whereas this is essential for unstructured data, and fine for transfer between MongoDB systems, the use of a JSON schema is much more effective for general use where the schema is pre-defined, because it also allows constraints and checks as well as specifying the data type. With JSON Schema, JSON doesn’t need all the extra datatype extensions.

There is, sadly, no defined standard for any extended JSON, and even within MongoDB, it exists in several different confusing dialects.
MongoDB’s BSON isn’t text-based at all but represents a binary parsed form of the extended JSON.
The truth is that anyone using the mongo shell or mongoimport finds no easy way of importing JSON from a ‘foreign’ (non-MongoDB) source in a way that preserves even dates as binary values rather than strings.
This is important, as you will soon find if you are expecting to be able to find documents in a collection between two dates. Studio 3T gets around this problem with SQL RDBMSs (Relational Databases) by importing directly from a relational database (MySQL, Oracle, PostgreSQL, or SQL Server) and creating the correct ‘extended JSON’ equivalent.
SQL Migration
Attempts to bridge the difference via ORM middleware have been ingenious but with rather muted success, because any attempt to represent a relational model in terms of hierarchical object models is bound to be a compromise that is difficult to optimize.
Exchange of data between heterogeneous databases via Node.js has a better chance of success, but only where relational databases can accept JSON data as a parameter as well as singleton data, and where they can make authenticated REST calls.
The implementation of microservice architectures has proved that this can be made to work successfully.
A more recent alternative approach is to use Studio 3T SQL Migration. This feature not only transfers the data in either direction but simultaneously bundles up the relevant schema change-script.
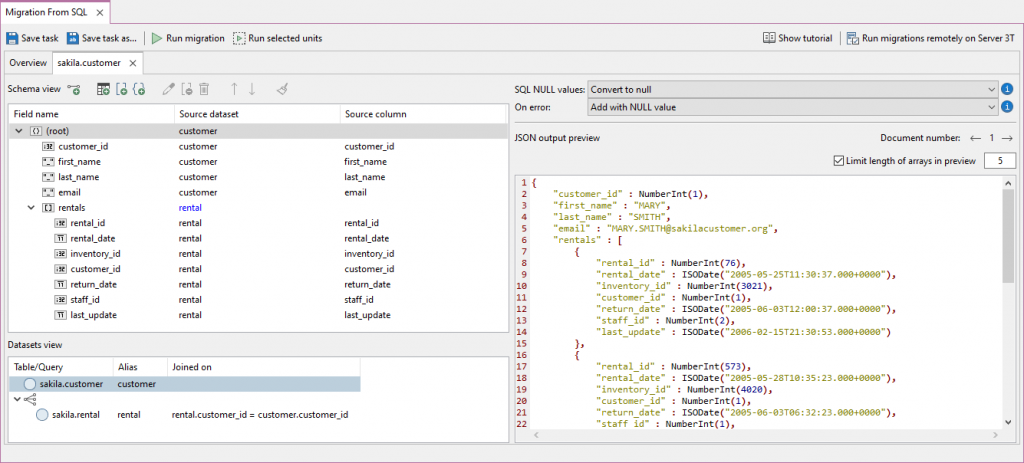
When importing, it can convert the relational tables into document-based schemas, using a mapping that can be added, stored, and edited within the application. It is now able to migrate data both ways so that a collection can be scripted as a SQL table creation, followed by the insertion of data.
One can, via mappings, create a number of linked tables to represent the collection. This allows us to sidestep the use of JSON altogether as a transport medium when exporting data from MongoDB to SQL Server.