Why transfer databases?
When assessing the value of a database system for your server environment, one important objective is to get your existing databases into it, and out of it. This article is all about getting databases from SQL Server to MongoDB – and vice versa.
Whenever I’ve had to introduce changes in database strategy in a large organisation by introducing a database system, the question always comes up:
“How easy is it to move our databases to the new platform, and back again if things don’t work out?”
Many other questions come up too, but there is always that underlying anxiety that any new proprietary system could be one that is difficult to extricate ourselves from.
Data represents the most precious jewels that can get accidentally lost in a swamp. Procedures generally resist being ported because there is so little standardisation in database procedure code, but data is easier to move.
It is always slightly unfair to judge different database systems on their data interchange, especially when there are such fundamental differences between a document and relational database. However, it is always reassuring when you find out that it is possible.
Import from SQL Server to MongoDB
There are a number of approaches to importing data from SQL Server.
You can use a coding approach with the mongodb.net library, together with SQLClient or SMO. You can use Node JS, with the Express plugins, you can use a MongoDB tool like Studio 3T, you can do a file-based transfer, or you can use a commercial ODBC driver.
There may be other techniques that I haven’t tried. In this article, we’ll focus on the versatile file-based transfer, because for me that gets the quickest results.
File-based database transfer
MongoDB is a bit coy about importing and exporting data between systems. The story is that you just import JSON documents into a collection, and export data the same way. This is certainly partly true, but there are snags. The first one is ensuring the right data type.
The data type issues
Whereas one can be fairly relaxed when throwing data at the table of an RDBMS from JSON, the same isn’t true of a BSON collection. Why?
A relational table contains all the rules that govern the type of data that can be inserted. It has defined data types for each column, and constraints that define whether NULLs are allowed, whether values are unique, or whether the values conform to the rules of the data in the table. You can, for example, check the rules of identification or geographic codes as the data is inserted.
MongoDB has two devices for ensuring data integrity with a JSON import. It has adopted the JSON Schema system for checking the data, and it has adopted Extended JSON as its standard for importing and exporting BSON data with data types.
JSON Schema is only useful where a collection is organised enough to enable you to have some sort of idea of what sort of data is there and what keys you are using. The closer it gets to being a table, the simpler and more valuable it gets.
Extended JSON defines the data type along with every value that isn’t obvious. It can add another third to the size of the data, but it is safe for relatively unstructured data. Its main advantage is that it can be read by any system that can read standard JSON, because the data type information is recorded in JSON.
Are we being fussy here about data types? Well, I don’t think so. If you import a JSON collection that includes a date, it is interpreted as a string because JSON has no standard way of representing a date. This is OK until you want to sort documents according to date, and then it is tricky.
If you want to index by date, you are lost. There are many differences between a decimal number and a floating-point number, as you will soon find out if you try using floating point for financial calculations! If you store binary information, you need to retain the encoding information with it. Data types really matter.
If the data that you are importing is tabular, then there is a simple way of doing it. You can use CSV or TSV with the –columnsHaveTypes switch and provide field specifications.
In PowerShell we can demonstrate this easily:
Actually, mongoimport is a bit broken, in that it sends verbose content and error messages to unusual places, and will so not work properly in PowerShell. (By ‘properly’, I mean that it fires spurious errors in PowerShell, and it is easy to end up not seeing the real errors).
It is probably easier to use the old Windows command line to try this out:
You wouldn’t want to add a header line to a large pre-existing CSV file, so you can instead specify a file for these headers.
The main problem we have with CSV is that MongoDB sticks sensibly to Common Format and MIME Type for Comma-Separated Values (CSV) Files (RFC4180) and SQL Server doesn’t.
Theirs may or may not work, but where it doesn’t, it messes up without errors. In other words: Don’t! TAB-separated files are fine until you have a tab character in your column values (the IANA standard for TSV simply forbids tabs).
If you want to import data from MongoDB into SQL Server, all you need to do is to use a JSON export because of all the checking that is done at the receiving end.
To import into MongoDB using mongoimport, the safest approach is Extended JSON.
The MongoDB GUI Studio 3T allows a variety of import methods, including to and from SQL, using a SQL connection that can read two million records in three minutes, but this is another, and swiftly moving, topic.
The primary key issue
Generally speaking, relational database tables have either a primary key or a unique constraint. Without them, you can’t easily retrieve a unique row.
MongoDB collections are built with a clustered index. By default, this is just a random object_id.
This loses a wonderful indexing opportunity, because a clustered index is usually an ideal candidate for a primary key. If you import a tabular database into MongoDB, it will work surprisingly well if you index the database properly, and by creating meaningful clustered indexes, you create a free and appropriate index for every table.
I test to see if the primary key is compound or represented by a single column and I use that for the _id field. I also keep the key as-is so whoever used the database has both options.
Here is an example of AdventureWorks, the classic SQL Server sample database, ported to MongoDB.
Using Studio 3T, I’ve done the classic NAD (Name And aDdress) view of employees in the SQL Query tab.
You’ll see that, where possible, I’ve managed to make use of the MongoDB _id clustered index.
The way that this database is designed, the primary keys are often wasted, so it isn’t always possible, so indexes are created where necessary. It takes under half a second on my test machine, which isn’t fast but not unreasonable.
To solve both these problems, data types and primary keys use Extended JSON.
Using Extended JSON
Extended JSON is readable JSON that conforms to the JSON RFC, but which introduces extra key/value pairs to each value that defines the data type.
This format can be read by any process that can consume JSON data, but can be understood only by the MongoDB REST interface, mongoimport, Compass, and the mongo shell.
The important common data types are all there, but there are also several data types that are only relevant to MongoDB and are used for transfer between MongoDB databases. It has a lot in common with the data type specifications in the headers of CSV files.
The standard comes with a strict ‘canonical’ mode and ‘relaxed’ mode. MongoDB unfortunately parses the strict mode. There is a third dialect in MongoDB, mongo shell mode, which has ‘helper’ functions to describe the BSON data type. Both types can be used by mongoimport, but mongo shell mode is not recognized by standard JSON parsers.
SQL Server exports in standard JSON though it can have problems with CLR and deprecated data types. It has to be shown how to write Extended JSON. We therefore hide that complexity in a stored procedure.
At its simplest, it produces code like this in each file (I show just the first few documents). I’ve chosen to check whether there is a primary key based on one column and if so, I use that as the MongoDB key which is indicated by using the reserved label ‘_id’.
I map the SQL Server data type to the equivalent MongoDB BSON data type which, in this case, is a 32-bit integer.
Export JSON files through PowerShell
JSON files can be exported from SQL Server as Extended JSON using a modified JSON export, contained in a temporary stored procedure. This can be done from PowerShell or from SQL.
By using PowerShell, you can avoid having to open up SQL Server’s ‘surface area’ allowing it to run DOS commands that write data to a file. I show the simpler technique of using SQL in another article.
Here is a PowerShell version that saves every table in a database to an Extended JSON file. OK, it looks a bit complicated but in essence it just connects to a database and, for every table, it runs the stored procedure to convert the data to JSON. It then saves this to the directory you specify.
Once you have exported the Extended JSON files, it is the work of a moment to get them in place with Studio 3T.
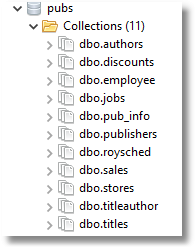
And the next thing you know, there is the old Pubs database in your MongoDB database, from back in the old Sybase Days:
The problem is, we don’t always want to rely on doing this interactively. Sometimes, you’ve just got to script things out.
Usually, I advocate PowerShell, but the mongoimport utility is quirky and is best done from the command prompt or from a batch file. Here is the batch file. It is slightly cryptic but works!
Export from MongoDB to SQL Server
The mongoexport utility exports in Extended JSON, rather than plain standard JSON.
In order to get plain JSON export, you’ll need a third-party utility such as Studio 3T.
SQL Server can read Extended JSON but only if you provide an explicit schema for each collection that you are putting in a table. This isn’t entirely satisfactory because it is tricky to automate.
Here is an example using just a sample of the output from mongoexport to illustrate.
Notice that the path to the actual data has double-quotes around the key field. This is because the dollars sign isn’t legal in the path expression in the WITH explicit schema statement.
Conclusions
We can transfer the data of databases between SQL Server and MongoDB remarkably easily, but normally the actual tables are the least of our problems. There are also the most important indexes, the views, the procedural logic, scheduled tasks, and a mass of code to consider.
I wouldn’t even want to consider porting a relational system to MongoDB unless it was just an initial staging phase. In this case, I’d create the collections on SQL Server, on the source database from their constituent tables, making a judgement on the best design for a hierarchical document database.
My conclusions from this article are that the use of Extended JSON provides the best way of transferring data between the two database systems, especially as it solves two problems, and can be automated. However, a third-party tool such as Studio 3T makes aspects of the job a great deal easier, especially the import and export of a large collection of Extended JSON files in MongoDB!