
Q: I’ve been given an old dataset to tidy up for new applications, but where do I start?
Welcome to the latest Studio 3T Ask Manatees Anything – #Studio3T_AMA. Want to know how to use Studio 3T to make your MongoDB life better? Just tweet and use #Studio3T_AMA or email [email protected].
A: Well, you’re in the right place; Studio 3T is built to help you modernize your data. As we don’t have your dataset, we’ll dig up a small one of our own. You can download it here and import it to follow along. This has documents of various shapes with different sets of fields attached to it.
Exploring the Schema
Now, the obvious starting point is to understand what is and isn’t there. For that, we can use Studio 3T’s Schema Explorer to investigate. Select the collection and click on the Schema toolbar button. Studio 3T will display the Schema analysis page where you get to pick how deeply the tool examines the database.
For most work, the Random sample should give you a good idea, but if you are looking for outliers and rare differences, set that to All to not miss a thing. There’s a few more settings we can adjust, but let’s move on and click Run Analysis.
And here’s our own “scruffy” schema named customers. On the left, all the fields that were found and their types. On the right, a pie chart of the distribution of those types.
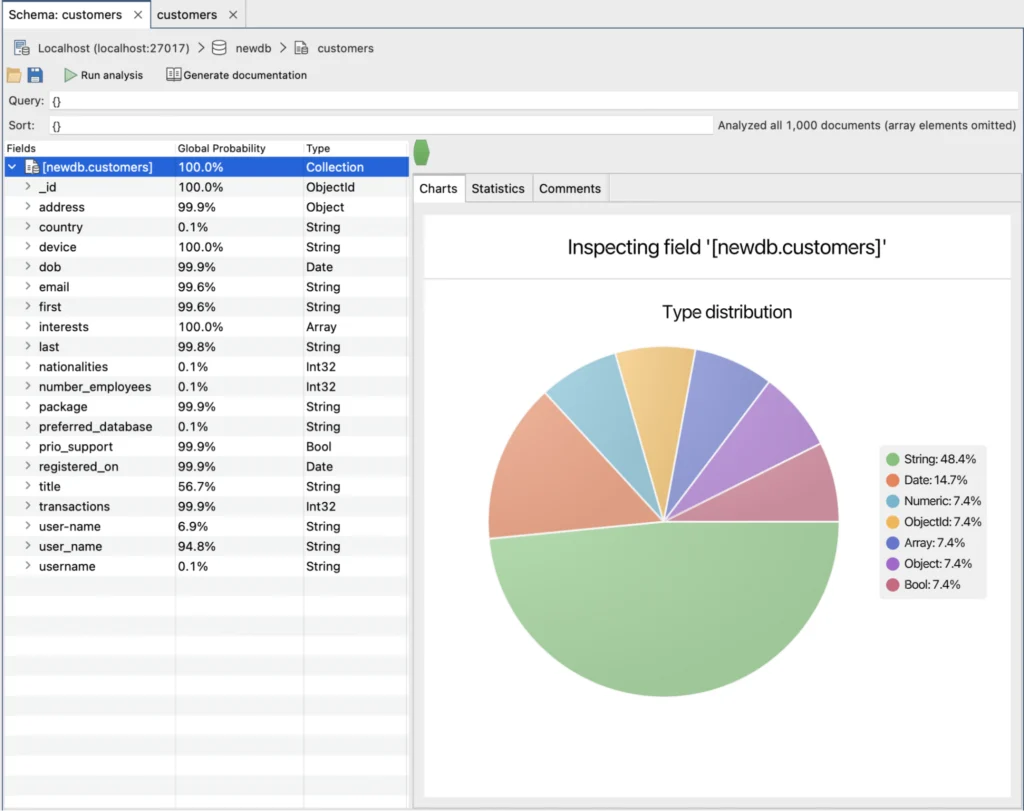
Now, if we look on the left we can see the global probabilities of particular fields and types existing in our collection. Where that probability is 100%, we can be sure that the field exists in all records and when we’re writing an application, we can rely on it being there. So we already know our schema looks like this
Customer {
_id: ObjectId,
device: String,
interests: Array,
}
Finding Bad Documents
There are, though, a lot of fields at 99.9%. Hmmm… this sounds like some bad data that’s distorting the schema. Let’s bring up the right click menu on the first of them: address. We’re interested in records which don’t have the address field, so select Explore documents not containing selected field.
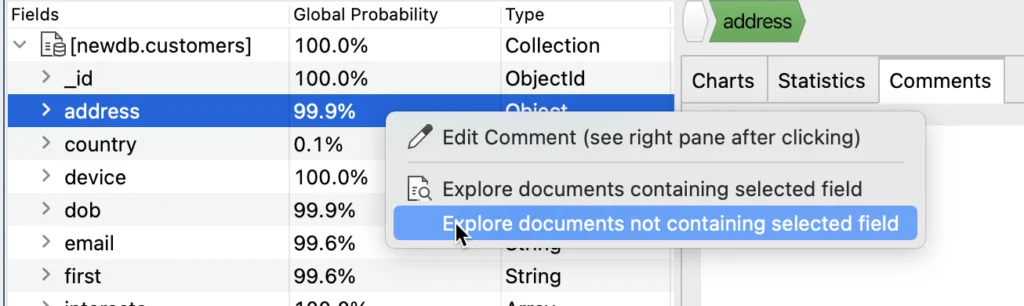
And a new tab will open with an { “address”: { $exists: false } } query. This reveals the awful truth:
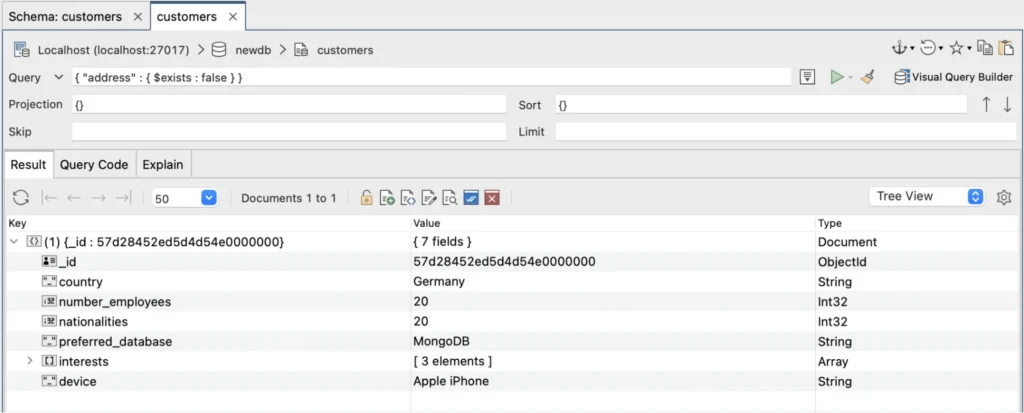
It’s all down to a single, very malformed document, almost as if it was meant for another collection. It is also responsible for most of the fields showing up as those 0.1% probabilities – nationalities, number_employees, preferred_database and country. It’s obviously an error, so let’s delete it (right menu, Document -> Remove Document). Now we go back to the Schema Tab and click Run Analysis again:
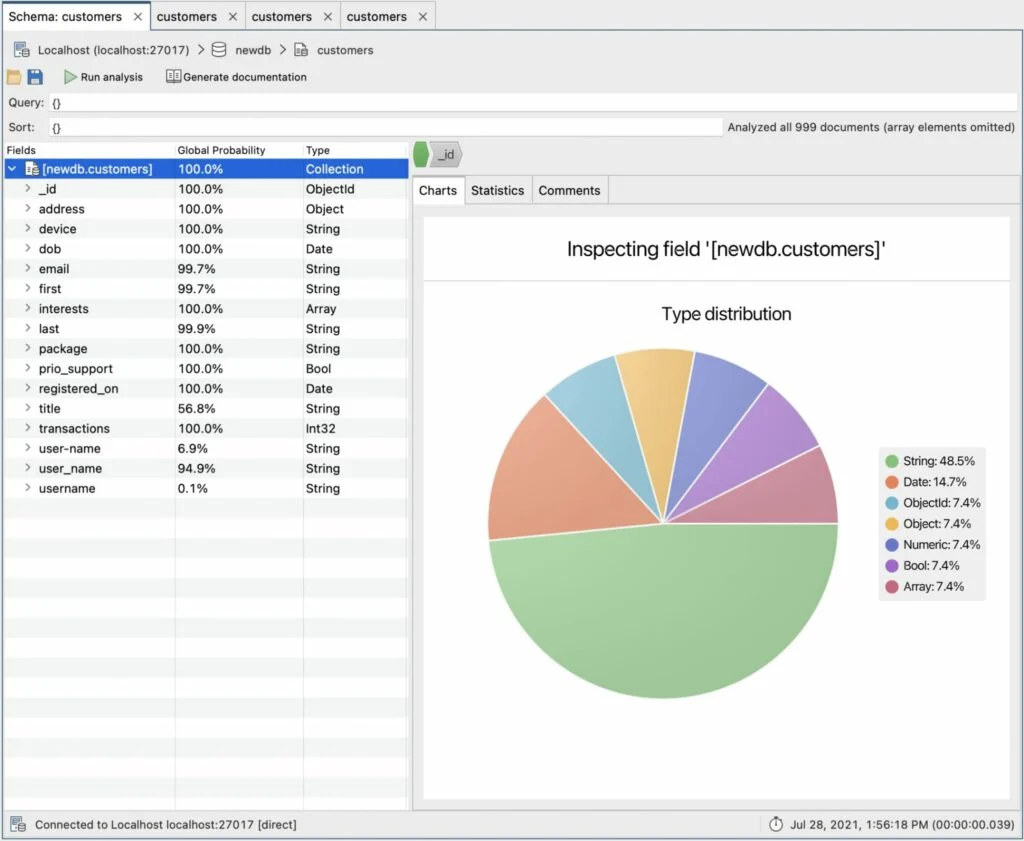
That’s much better. More 100% probabilities all over.
Customer {
_id: ObjectId,
address: Object,
device: String,
dob: Date,
interests: Array,
package: String,
prio_support: Bool,
registered_on: Date,
transactions: Int32
}
There’s still plenty more to do cleaning up this schema. In the next AMA, we’ll show you tips and tricks for giving your data a deep clean.