MongoDB has been wise to adopt the JSON Schema standard for validating changes in the data. It is a standard that allows document data to be checked with a variety of tools before it is even imported into the database.
At first glance, it seems strange to want to enforce the schema of a database in a database system that prides itself on being schema-less.
However, it makes a lot of sense at the point in time that database applications move from the informal to the industrial grade, mainly because it helps to protect against bad data, but also because it goes some way to define where data is and isn’t held, for the purposes of regulatory compliance.
With MongoDB, you don’t have to define a fixed schema for a collection. That is great for getting up and running quickly but there are many advantages to doing so with a more mature system.
Take the problem of ‘bad data’. You don’t have to ensure that your data is checked on entry, but if you can prevent bad data getting into a database, you save a lot of time later on. Bless you if you’ve never suffered data that has vanished because someone named the key value slightly differently, or, gasp, altered the case.
Seasoned database people will wince at the thought of dates entered as strings that can’t be coerced into dates, or numbers with spurious symbols such as currency.
Data in a busy multi-user system goes bad as surely as over-ripe fruit unless it has constraints, and it always seems to happen in ways that take the application developers by surprise.
The importance of JSON Schema validation
With real applications, especially those doing important work in a commercial setting, you will soon find that JSON documents must conform to a fixed schema and validation rules, for at least some of their data, in some collections and documents.
You will, for example, require that some properties must be there, and that they conform to particular rules.
MongoDB’s advantage over RDBMSs is that it is easier to do this mixing of the formal and informal. You already have a requirement for a primary key, and there will be other properties that need to be of a certain type or that are mandatory for the collection.
A customer collection, for example, must have the basic data such as first-name or last-name even if it doesn’t often need a suffix and can leave out the title.
Schemas are designed to maintain and check some or all of the structure of a document, allowing you to be more precise about what is going into the database, and keeping both the data and code clean.
Once you have a defined schema, it becomes possible to provide up-to-date “intellisense” for data entry. You can provide input forms that check the validity of the data being entered, to the current definition.
Traditionally, MongoDB developers have had to implement their own schema validation routines in their applications, but the arrival of JSON schema standards, the many JSON Schema validators, and an excellent .NET validation library by NewtonSoft allowed this to be done in a standard way.
From Version 3.6, MongoDB supports this standard and provides a JSON Schema Validator from within the application that runs like a trigger to check any changes to the data via inserts or alterations.
Because it is an industry-standard, you can opt to validate your data from within MongoDB so that you can check data on entry or change, or you can export it as standard JSON, and validate it outside the database. Ideally, with bulk entry of data, you can validate it before import.
What JSON Schema checks for
The JSON Schema firstly determines how the data is stored. It is designed to check a JSON document, not a MongoDB collection, so we need to convert a ‘collection’ of documents into an array of documents.
However, if you provide a JSON Schema to a mongo collection, then it will work as if it is checking an array of objects, but you can configure the level of validation (validationLevel) and the action taken when an error is found (validationAction).
Out of the box, it will only check individual documents when they are altered or inserted.
The schema can do nothing if you want it to. The first thing it can check is the way that the data is structured within the document.
Normally, data is stored as arrays of objects, though tabular data can be stored as arrays of arrays.
It can then check on whether:
- The object has all the required properties
- Additional properties are allowed
- There is at least a minimum number of properties
- It is less than the maximum
You can define the data type of each property and how it should be validated to check for the range of values.
MongoDB schema validation example
We already have a sample database that I introduced in my article, MongoDB, A Database with Porpoise. It is a taxonomy of marine mammals, some of the most interesting and engaging of creatures.
Adding the schema validation
We were very privileged to be given part of the WORMS (World Register of Marine Species) database to do this. It changes very little, so we are safe in being lavish in extracting just what we want.
We’ll add schema validation to it. Studio 3T, a third-party MongoDB IDE, has a simple way of doing this.
Right-click on the collection and then click on the ‘Add/Edit Validator’ menu item in the context menu that appears.
With the validation screen that appears we enter a ‘null’ JSON Schema.
{
"$jsonSchema" : {
"bsonType" : "object"
}
}
This is just a very simple validator that does nothing.
Before we start, there is a big bad fault with the Schema validation with version 3.6 and 4.0. If a record fails validation, MongoDB doesn’t tell you what failed.
You just get:
This means that, in order to check your validation, you need to take baby steps, and to do debugging in a high-quality JSON Schema Validator such as Newtonsoft’s browser-based validator that highlights the broken line and even explains why it failed.
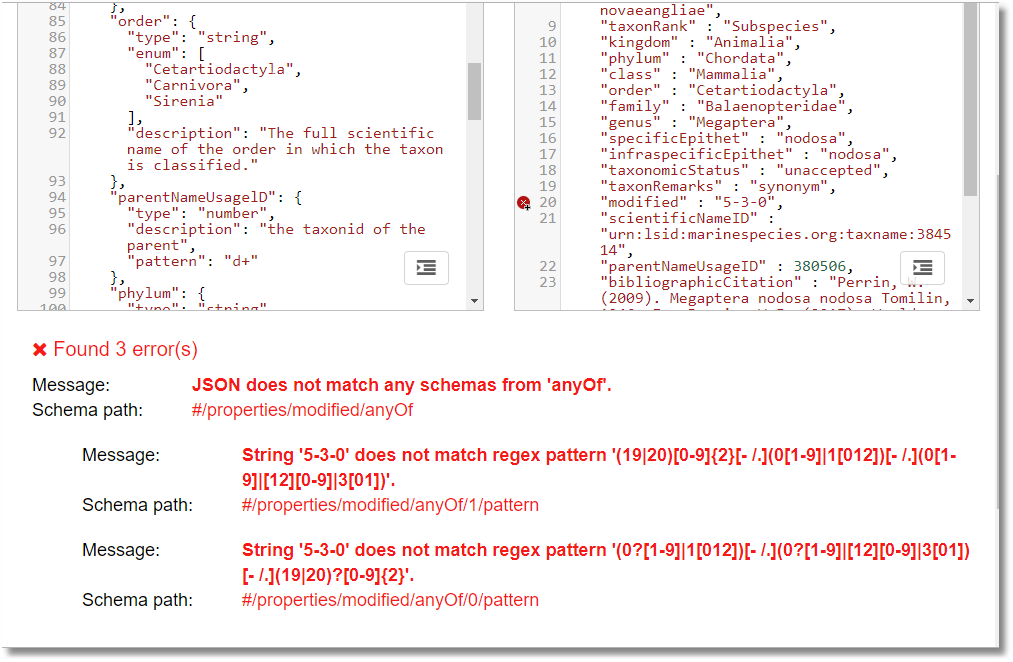
This is great, except for the fact that you can’t use MongoDB’s extensions to the standard such as bsonType, because you can’t test it properly.
‘Aha!’, You say. Why not have the bsonType as well, since you are allowed other properties that are not reserved words in the standard.
Oops, if you try it, you get this:
This is a special condition put on the schema that isn’t in the standard.
Specifying the required schema properties
We can start by specifying all the properties that are required.
We can do this by clicking on Schema on Studio 3T’s global toolbar, which opens up Schema Explorer. This will list all those properties that are in 100% of the records.
When we do this with the MarineMammalSpecies database, we get this:
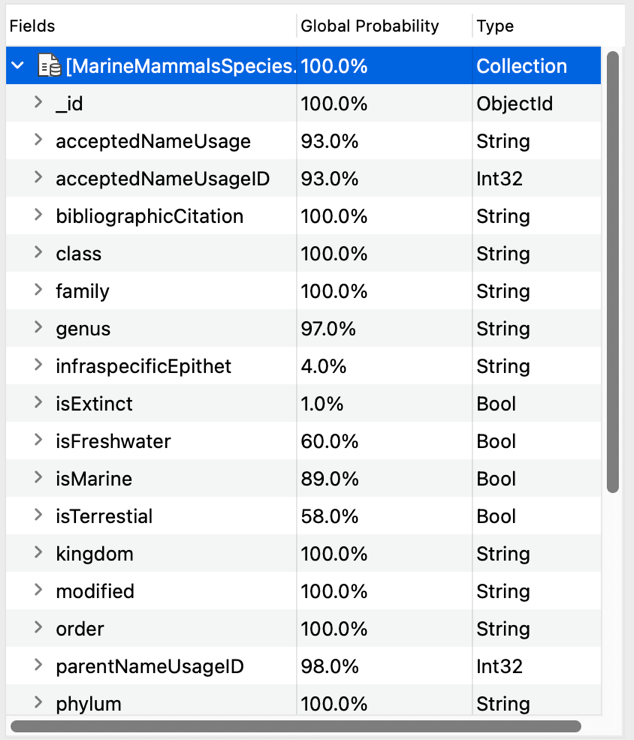
This tells us that the following properties are in all the records so would seem to be required: acceptedNameUsagelD, bibliographicCitation, class, kingdom, modified, order, phylum, scientificName, scientificNameID, taxonID, taxonRank and taxonomicStatus.
The required keyword specifies that the object’s property set must contain all the specified elements in the array:
{
"$jsonSchema" : {
"bsonType" : "object",
"required" : [
"acceptedNameUsagelD",
"bibliographicCitation",
"class",
"kingdom",
"modified",
"order",
"phylum",
"scientificName",
"scientificNameID",
"taxonID",
"taxonRank",
"taxonomicStatus"
]
}
}
In our case, we allow additional properties, there is a keyword additionalProperties that you can set to true or false, or you can supply a JSON Schema object to specify a rule for additional objects.
You can set the minimum and maximum number of properties with a maxProperties or minProperties keyword.
First, we set up a test harness, taking a small sample of documents from the collection and turning them into an array of objects by means of adding commas between the documents and adding the array wrapper ‘[‘ and ‘]’.
Then we take the value of the $jsonSchema key (the following {} and its contents) and paste that into the schema window of the validator.
Works first time? Lucky!

When you are satisfied that it is working, try pasting it into the Studio 3T validation editor. (You can validate the schema itself from this screen, not the database!).
With luck, it will accept the schema when you hit Save. If there is something it doesn’t like, it will refuse to save it and if you didn’t copy the text before you did it, it will be lost.
Fortunately the NewtonSoft Schema Validator allows you to edit and assiduously preserve your content, so you can still make progress.

If it accepts your schema, it means that, now, we cannot alter a document in the collection that misses out any one of these fields.
Try doing it in the collection screen! You will get that non-specific error again.
Defining the JSON types
Next, we need to document all the properties to give their JSON type, and a description so that, in an enlightened age, the display of the record will be able to provide “intellisense” and the entry form will prompt you with the description.
We insert these into fields (actually, they are JSON Schema objects) within a properties property. If we were describing items in a JSON array, we might choose to specify them with an item array.
"properties" : {
"acceptedNameUsage" : {
"type" : "string",
"description" : "The full name, with authorship and date information if known, of the currently valid (zoological) or accepted (botanical) taxon."
},
"acceptedNameUsageID" : {
"type" : "number",
"description" : "An identifier for the name usage (documented meaning of the name according to a source) of the currently valid (zoological) or accepted (botanical) taxon."
},
"bibliographicCitation" : {
"type" : "string",
"description" : "required and must be a string"
},
"class" : {
"type" : "string",
"description" : "The full scientific name of the class in which the taxon is classified."
},
"family" : {
"type" : "string",
"description" : "The full scientific name of the family in which the taxon is classified"
},
"genus" : {
"type" : "string",
"description" : " The full scientific name of the genus in which the taxon is classified."
},
"infraspecificEpithet" : {
"type" : "string",
"description" : "The infraspecificEpithet should only be the terminal name part - the part of the name with the lowest or most specific rank."
},
"isExtinct" : {
"type" : "boolean",
"description" : "is the species extinct?"
},
"isFreshwater" : {
"type" : "boolean",
"description" : "Does it live in freshwater?"
},
"isMarine" : {
"type" : "boolean",
"description" : "Is it a marine species"
},
"isTerrestial" : {
"type" : "boolean",
"description" : "Is it a terrestrial species?"
},
"kingdom" : {
"type" : "string",
"description" : "The full scientific name of the kingdom in which the taxon is classified."
},
"modified" : {
"type" : "string",
"description" : "When the record was last modified (e.g. 2009=03-20)"
},
"order" : {
"type" : "string",
"description" : "The full scientific name of the order in which the taxon is classified."
},
"parentNameUsagelD" : {
"type" : "number",
"description" : "the taxonid of the parent
},
"phylum" : {
"type" : "string",
"description" : "The full scientific name of the phylum or division in which the taxon is classified."
},
"scientificName" : {
"type" : "string",
"description" : "The full scientific name, with authorship and date information if known. When forming part of an Identification, this should be the name in lowest level taxonomic rank that can be determined. This term should not contain identification qualifications"
},
"scientificNameAuthorship" : {
"type" : "string",
"description" : "The authorship information for the scientificName formatted according to the conventions of the applicable nomenclaturalCode."
},
"scientificNamelD" : {
"type" : "string",
"description" : " An identifier for the nomenclatural (not taxonomic) details of a scientific name."
},
"specificEpithet" : {
"type" : "string",
"description" : "The name of the first or species epithet of the scientificName."
},
"subgenus" : {
"type" : "string",
"description" : "The full scientific name of the subgenus in which the taxon is classified. Values should include the genus to avoid homonym confusion."
},
"taxonID" : {
"type" : "number",
"description" : "An identifier for the set of taxon information (data associated with the Taxon class). May be a global unique identifier or an identifier specific to the data set."
},
"taxonRank" : {
"type" : "string",
"description" : "The taxonomic rank of the most specific name in the scientificName. Recommended best practice is to use a controlled vocabulary."
},
"taxonRemarks" : {
"type" : "string",
"description" : "Comments or notes about the taxon or name."
},
"taxonomicStatus" : {
"type" : "string",
"description" : "The status of the use of the scientificName as a label for a taxon"
}
It is looking better. We sigh, and paste it into the Schema validator. Then we test it out by saving an edited document.
Using regex to transform types
Next, we need to get over the problem that we have a ‘modified’ property that actually needs a date but the database has it stored as a string. That date ought to be validated.
This turns out to be extraordinarily easy. We add a regex to do the job.
"modified" : {
"type" : "string",
"description" : "When the record was last modified (e.g. 2009=03-20)",
"pattern" : "(19|20)[0-9]{2}[- /.](0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])"
},
Again, we test this out to ensure that we can save a document with a good date, and we can’t save a document with a bad date.
Now, all those integers that we could only specify as a number JSON data type can be dealt with even easier by adding a
"pattern" : "d+"
…to every property of ‘number’ type in the ‘properties’ object that should be an integer.
You do a similar regex (javascript flavor) to types such as ….
- Email addresses
((?=[A-Z0-9][A-Z0-9@._%+-]{5,253}$)[A-Z0-9._%+-]{1,64}@(?:[A-Z0-9-]{1,63}\.)+[A-Z]{2,63}) - Domain names
((?=[a-z0-9-]{1,63}\.)(xn--)?[a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,63} - National Insurance numbers
[abceghj-prstw-z][abceghj-nprstw-z] ?[0-9]{2} ?[0-9]{2} ?[0-9]{2} ?[a-dfm]? - UK Postcodes
[A-Z]{1,2}[0-9][A-Z0-9]? [0-9][ABD-HJLNP-UW-Z]{2}
…and so on.
Now we turn our attention to any field that has a limited number of legitimate values. As this database only applies to aquatic mammals, the class is always ‘Mammalia’ …
"class" : {
"type" : "string",
"enum" : [
"Mammalia"
],
"description" : "The full scientific name of the class in which the taxon is classified."
},
… and the kingdom is always ‘Animalia’.
"kingdom" : {
"type" : "string",
"enum" : [
"Animalia"
],
"description" : "The full scientific name of the kingdom in which the taxon is classified."
},
These properties must be there to allow this database to be combined with others of wider scope and conform with the scientific standards for taxonomy.
One day, hopefully, MongoDB will add this key/value pair to the document if it is missing, seeing that it can only be one value. An enum with only one value is an edge case. You are more likely to get a list of possible values.
Taxonomic status can be one of only a certain number of legitimate values. The WORMS database actually doesn’t use the categories defined by the GBIF-TDWG Vocabulary standard, so we’ll opt to combine in our list those and the ones they’ve chosen in this database, despite the overlaps.
"taxonomicStatus" : {
"type" : "string",
"enum" : [
"accepted",
"valid",
"synonym",
"unaccepted",
"homotypic synonym",
"heterotypic synonym",
"proParteSynonym",
"misapplied",
"alternate representation",
"nomen nudum",
"nomen dubium",
"temporary name"
],
"description" : "The status of the use of the scientificName as a label for a taxon"
}
Only one of these alternatives can be chosen as a value for this property. Normally, they would be presented in a list within a GUI.
There are plenty of ways that one can validate a property value. One concept that quickly comes up is that of a subschema. This can be as little as a JSON Schema empty object ‘{}’, but is normally a little more picky.
If you need to check a value against several RegExs, for example you might want to use this, which allows you to use two different date formats..
"taxonomicStatus" : {
"type" : "string",
"enum" : [
"accepted",
"valid",
"synonym",
"unaccepted",
"homotypic synonym",
"heterotypic synonym",
"proParteSynonym",
"misapplied",
"alternate representation",
"nomen nudum",
"nomen dubium",
"temporary name"
],
"description" : "The status of the use of the scientificName as a label for a taxon"
}
>
The anyOf, oneOf, or allOf and not keywords take an array of JSON Schema objects.
Numeric values can have a maximum and minimum specified, or you can specify that they must be a multipleOf a number. You can specify a maxLength or minLength of string.
Conclusions
Any database is somewhere on a spectrum between the schema-less to the tightly-nailed-down and constrained schema.
It is rare to find a database that is entirely schema-less, and most databases cluster around the white light area of the spectrum.
Relational databases get around the problem of data that is poorly structured by adding XML columns, JSON columns, or by using sparse tables. Document databases can accommodate the need for structure and constraints by using a document schema.
MongoDB has been wise to adopt the standard JSON schema, which is easy enough for ordinary mortals to understand. JSON Schema allows document data to be checked with a variety of tools before it is even imported into the database. We’re looking forward to a version of MongoDB that provides the precision of data error reporting that we’re used to getting from JSON Schema validators.
As well as defining the core and optional properties of an object, a document collection, or array, providing documentation and constraining the data values, JSON Schema allows you to provide information that is helpful when publishing data, or consuming data from external sources.
I can create a JSON document containing the contents of a MongoDB collection, along with its schema, that can be so easily exported to a SQL database that it can create the table to insert the data into it.
Once you go through the pain of creating a JSON Schema, it becomes a solution to all sorts of database problems. Data Masking? Oh yes. GDPR auditing? Certainly helps!
References
- Implementations | JSON Schema
- draft-zyp-json-schema-04 – JSON Schema: core definitions and terminology
- Schema Validation — MongoDB Manual
- JSON Schema Validator – NewtonSoft
- WoRMS – World Register of Marine Species
Related articles
Read our Knowledge Base article Schema Validator to find out more about applying MongoDB schema validation in Studio 3T.