
Q: I’ve started cleaning up my dataset, but how do I make it more consistent?
Welcome to the latest Studio 3T Ask Manatees Anything – #Studio3T_AMA. Want to know how to use Studio 3T to make your MongoDB life better? Just tweet and use #Studio3T_AMA or email [email protected].
A: In the previous Ask Manatees Anything, we made a start cleaning up using the Studio 3T Schema Explorer on a simple dataset.
Tidying up schemas (and data) requires its own set of skills. Let’s dig deeper and look at ways to make schemas consistent. That means with the same fields throughout. And how to handle overlapping fields and functionality.
Making A Consistent Schema
At the end of the last article, our dataset is looking a lot more like the coherent document we are hoping to get.
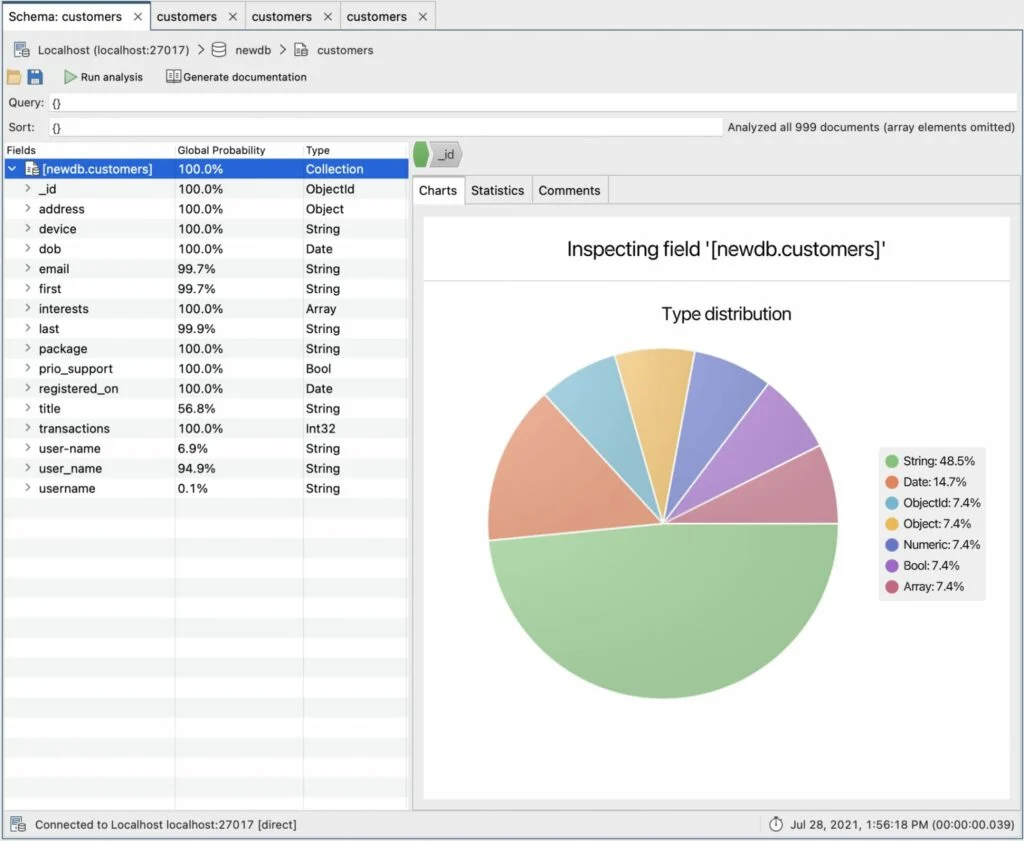
Our schema looks like this:
Customer {
_id: ObjectId,
address: Object,
device: String,
dob: Date,
interests: Array,
package: String,
prio_support: Bool,
registered_on: Date,
transactions: Int32
}
Let’s look at the fields which aren’t 100% again – email, first, last, title. This seems to be down to some variations in how names and email have been collected. Omitting fields is a legitimate way of handling a lack of a first name. But if you want a consistent schema (and storage isn’t severely limited), it is better to represent it as an empty string.
Filling In Missing Fields
If we go and select first in the schema view, then bring up the menu to Explore documents not containing selected field. We can see the documents lacking a first field. To remedy that, bring up the right button menu over the id of the first document:

The Add Field/Value dialog should appear. We want it to add the field “first” of type string and no value. Most importantly, we want to set it to Add this field to Documents matching query criteria.
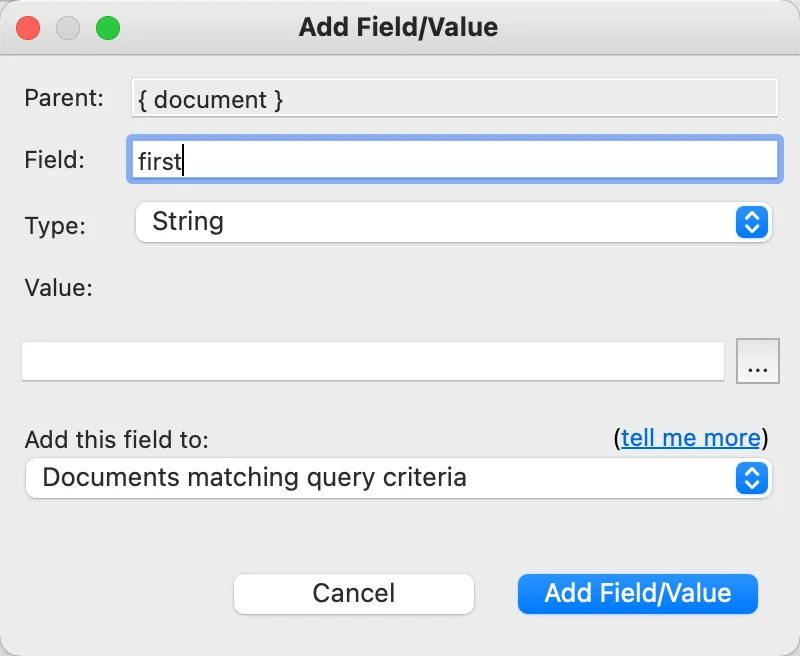
Clicking Add Field/Value will add that empty field. We’ll repeat the process with email, last and title, close the query window and rerun the analysis:
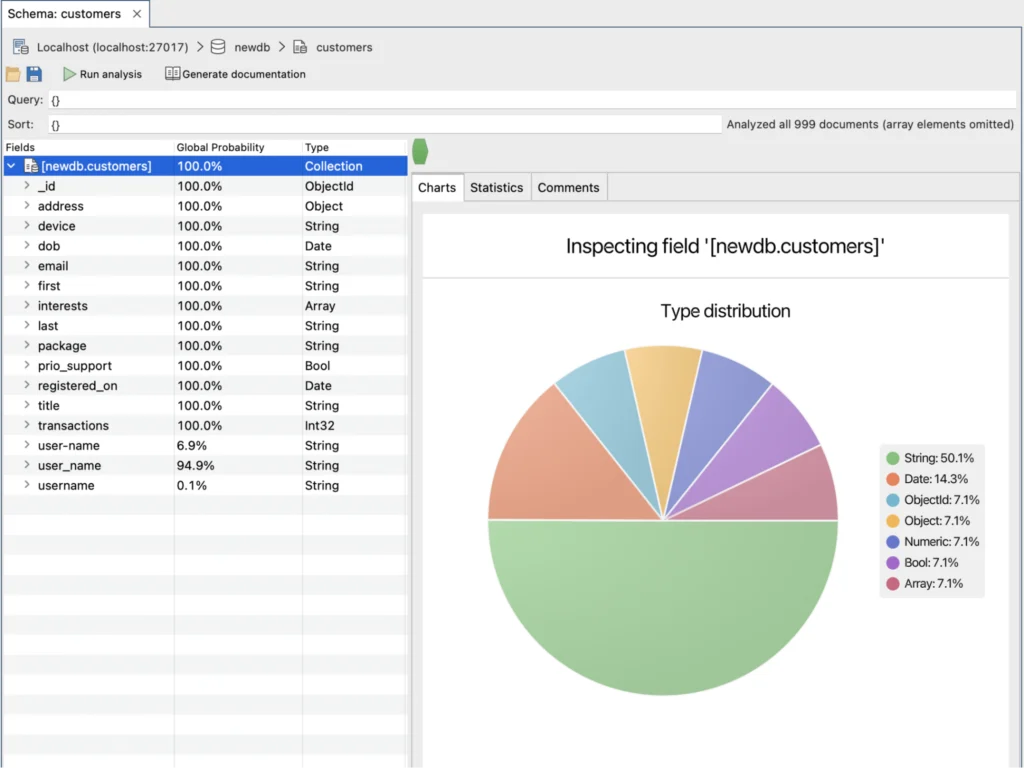
This is looking a lot better. Only user-name, user_name or username seem to be off kilter. Your first impulse might be to make them all the same name, say user_name.
Watch Out For Overlaps
But look closely and add the percentages: 6.9%+94.9% is 101.8%. That can only mean that there’s some documents with both. If we’d just gone and renamed user-name to user_name, we’d have lost the values in the user_name field.
The username field is less of a problem. If we use Explore documents containing selected field on the field in the Schema view, we can see it’s only in one document in the entire collection. Select that one document and, through the right-click menu, choose Field -> Rename Field. Rename the field to user_name.
Now, back to user-name and user_name. At this stage, in real life, you need to find out what is being stored in the two different fields. If there’s only a user-name field, you can make a reasonable assumption. This really should be the user_name and it’s just mis-named. To identify those fields, we will again use Explore documents containing selected field on the user-name field. Then we will bring up the Visual Query Builder and drag user_name from the view into the query. Now change the condition to doesn’t exist.
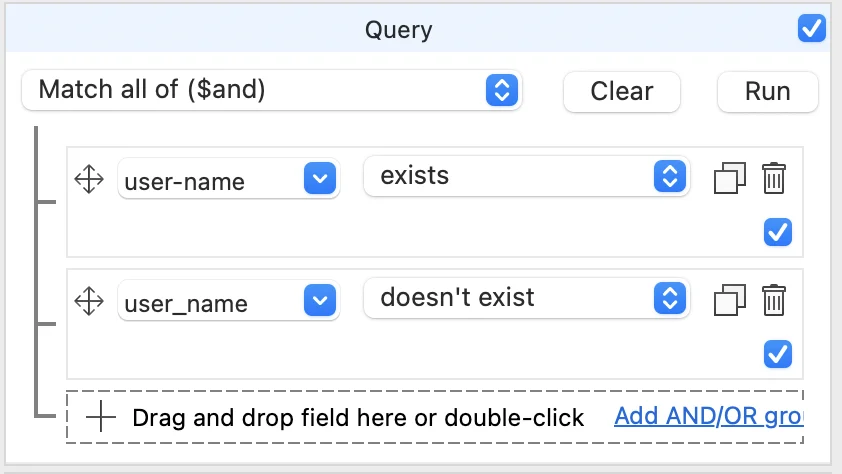
Click Run and our view updates to the 50 fields which don’t have both fields. We can now select the user-name field and rename it to user_name for everything that matches our query. We then select user-name in the tree, right-click for the menu and choose Field->Rename Field. In the dialog, we put user_name in as the new name and set it to rename for all Documents matching query criteria.
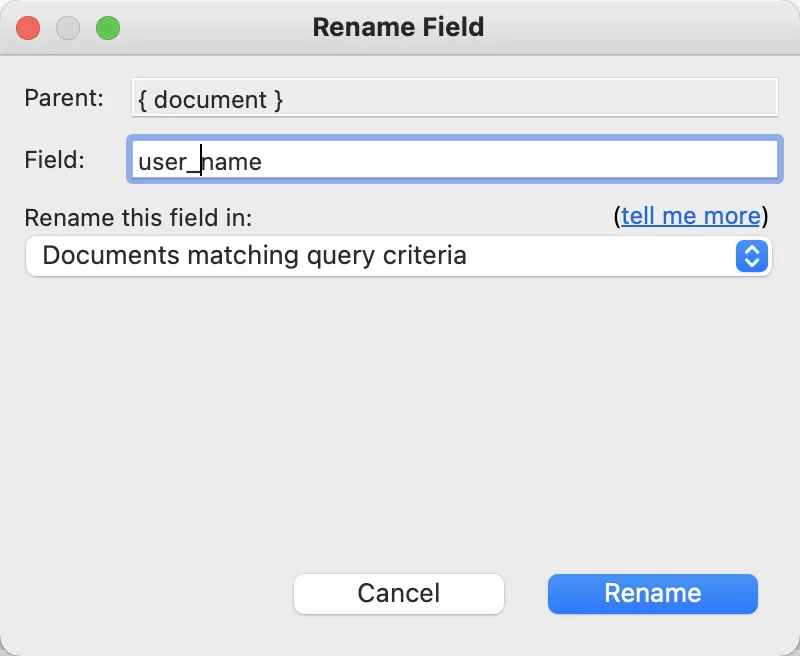
Clicking Rename will bring up a warning about the possibility of overwriting existing data, but we’ve already handled that possibility by ensuring that user_name doesn’t exist in all these documents. When that’s done, we can return to the Schema view and re-run the analysis. We can now see user_name is 100%, but there’s 1.9% that still have user-name.
For that 1.9%, you may be facing a situation where there are in fact one or more user names for users which you might want to store in an array. Or as an alternate field (that isn’t confusingly named). If you switched to an array and have applications accessing the data, they’d need to change how they treat the user name values. There’s also the other alternative that the data in the user-name field in these cases is bogus and will need to be pruned.
Fixing The Overlap
Some decisions can’t be taken automatically, but Studio 3T can help you when you’ve decided. In this case, we’re going to make a user_name_alias field out of user-name, and have that new field on all documents.
The first step is to create the field itself, so we go to our collection’s tree view and select Field->Add Field and create a user_name_alias field for every document in the collection.
Now we can rename the user-name field into user_name_alias. Start by selecting user-name from the Schema view and double clicking into the collection’s tree view. There we can select the user-name field in any one of the documents and use Field->Field Rename to rename it to user_name_alias for all Documents matching query criteria. When it warns about overwriting data in the user_name_alias field, don’t worry as that’s exactly what we want to do. The value for the field is currently empty.
Now we return to the Schema view and rerun the analysis. Every field shows as 100% consistently typed and present. A shinier, cleaner dataset thanks to Studio 3T. Our final schema is:
Customer {
_id: ObjectId,
address: Object,
device: String,
dob: Date,
email: String,
first: String,
interests: Array,
last: String,
package: String,
prio_support: Bool,
registered_on: Date,
transactions: Int32,
user_name: String,
user_name_alias: String
}