The ability to aggregate data is essential to mining valuable information from a dataset.
Aggregation can help you better understand the data, uncover patterns and trends that might not be readily apparent, and make strategic business decisions based on your findings.
For this reason, most database management systems provide mechanisms for aggregating data. MongoDB is no exception.
When you aggregate a collection in MongoDB, the storage engine groups the data by the values in one or more fields and then performs calculations that provide insights into each group.
For example, if you have a collection that contains data about automobile sales in the United States, you might want to determine the total amount of sales for each car model in each state. The MongoDB aggregation pipeline lets you do just that.
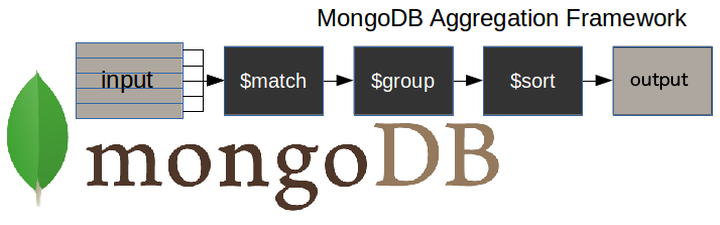
In this section of the course, you’ll learn how to build mongo shell statements that incorporate the aggregate method—one of the most important tools you have for aggregating MongoDB data.
The exercises in this section are based on the customers collection, which you imported in the first section of this course.
To help you understand how the aggregate method works, you’ll use the Studio 3T Aggregation Editor to build your MongoDB aggregation pipeline, which lies at the heart of aggregations.
By the end of this section, you will learn how to:
- Filter the documents in the aggregation pipeline
- Group the documents in the aggregation pipeline
- Add and remove fields in the aggregation pipeline
- Change the field order in the aggregation pipeline
- Sort the documents in the aggregation pipeline
What you will need:
- Access to a MongoDB Atlas cluster
- Access to the
customerscollection in thesalesdatabase

