
MongoDB provides the aggregate method for aggregating the data in a collection.
You call the MongoDB aggregate method from a collection object, like you saw with the MongoDB find method in the previous section.
The following syntax shows the basic elements that make up an aggregate statement:
db.getCollection(collection).aggregate(pipeline [, options])
To invoke the aggregate method, you start by specifying the db object, which points to the currently active database.
You then provide the target collection, replacing the collection placeholder with the collection name.
This is followed by the aggregate method and its two arguments, as indicated by the pipeline and options placeholders.
The pipeline placeholder
The pipeline placeholder represents the aggregation pipeline, which is where most of the work occurs.
The pipeline is broken into one or more stages, separated by commas, as shown in the following syntax:
pipeline ::= [stage, ...]
The : : = symbol indicates that the element on the left may expand into or be replaced by the elements on the right.
This symbol is commonly used in formal language notations such as the Backus-Naur Form (BNF). The syntax shown here is a variation of that form.
In this case, it means that the pipeline placeholder can be replaced with one or more stages.
Adding MongoDB aggregation stages
The stages are enclosed in square brackets, indicating that they’re part of an array.
Each stage is an element in that array and is made up of an aggregate method and its expression:
stage ::= { aggregate_method: expression }
A stage definition is enclosed in curly braces, just like a document.
You can think of the pipeline as an array of documents, with each document defining a stage in the pipeline. MongoDB runs the stages in the order specified, each one building on the previous one to produce the final results.
To better understand how this work, consider the following example, which calls the MongoDB aggregate method on the customers collection in the sales database:
use sales;
db.getCollection("customers").aggregate(
[
{ "$match": { "prio_support": true } },
{ "$group":
{ "_id": "$package", "totals": { "$sum": "$transactions" } } },
{ "$sort": { "_id": 1 } }
]
);
The aggregate method includes one argument—the pipeline—which is enclosed in the square brackets. The pipeline defines three stages, each enclosed in curly braces.
Stage 1 uses the $match operator to filter the documents in the pipeline.
The expression assigned to the operator first specifies the field name (prio_support), followed by the desired value (true).
In other words, only documents whose prio_support field value equals true will be passed onto the next stage in the pipeline. All other documents will be filtered out.
Stage 2 uses the $group operator to group the documents by the package field.
The expression for this operator is divided into two parts.
The first part (_id": "$package") indicates that the results should be grouped based on the package field. The _id field is a default field that is used to hold the distinct values that are extracted from the target field, which in this case is package.
The second part of this expression ("totals": { "$sum": "$transactions" }) defines a new field named totals.
The field will hold the total number of transactions for each group.
The number is calculated by using the $sum accumulator operator to add together the values in the transactions field, which is represented by the $transactions alias.
When referencing a field in an aggregate expression, you typically precede the field name with a dollar sign and enclose it in quotes.
Stage 3 uses the $sort operator to sort the documents in the pipeline.
The operator’s expression first specifies the field on which to base the sorting operation and then specifies the sort order.
A value of 1 indicates that the documents should be sorted in ascending order, and a value of -1 indicates that they should be sorted in descending order.
If you run the aggregate statement in IntelliShell, you’ll get the results shown in the following figure. The results include the total number of transactions for each distinct value in the package field.
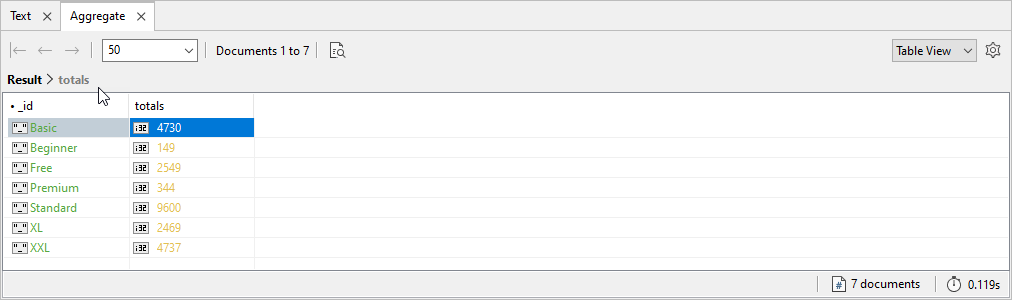
The options placeholder
Up to this point, we’ve focused on the MongoDB aggregate method’s pipeline element, which represents the method’s first argument.
However, you can also add an options argument, which includes one or more options that control statement execution.
For example, you can specify an indexing hint or the initial batch size for a cursor.
The following syntax shows how to specify one or more options:
options ::= { option, ... }
The options are passed to the aggregate method as a document that contains one or more fields, which define the option settings. Each field consists of an option name and its value, as shown in the following syntax:
option ::= option_name: option_value
The format of the option value depends on which option you’re setting. It might be a simple scalar value, such as false, or a more complex expression.
If you include multiple options, you must separate them with commas. The following code includes the same aggregate statement as in the previous example, only now it contains two options, which are added after the pipeline:
use sales;
db.getCollection("customers").aggregate(
[
{ "$match": { "prio_support": true } },
{ "$group":
{ "_id": "$package", "totals": { "$sum": "$transactions" } } },
{ "$sort": { "_id": 1.0 } }
],
{
"allowDiskUse": true ,
"collation":
{ "locale" : "en_US", "strength": 1 }
}
);
The first option sets the allowDiskUse setting to true, which enables the aggregation operations to write data to temporary files on disk.
The second option sets the collation settings, which can take multiple values.
In this case, the locale value is set to en_US (United States English), and the strength value is set to 1, which means collation comparisons are limited to the base characters only.
Overall, this is a relatively simple aggregate statement, but such statements can get quite complex. Fortunately, Studio 3T provides the Aggregation Editor for simplifying this process.
The Aggregation Editor walks you through the steps necessary to create aggregations. Not only does this simplify the process of defining aggregations, but it also serves as a tool for learning how to construct aggregate statements so you have a better sense of how they work.

