Do you ever dream of being able to take the output of a SQL Server query and be able to paste it straight into a MongoDB collection?
I don’t mean just a table, of course; it is unlikely that you would ever, in practice, want to transfer a whole lot of relational tables into MongoDB.
It is very important to be able to do so, of course, because this proves the technology. SQL Server and any other relational database is a very useful tool for producing what we would call ‘a report’.
A report is not a relational table but is any text-based output that can easily be read and processed by a system beyond the relational sphere. We can create a report in JSON that represents a collection, complete with fields containing embedded objects and arrays.
Basically, instead of porting tables to MongoDB, we create JSON-based reports that correspond as closely as we can to the final collection.
This is best illustrated with a simple example.
A simplified example
We’ll start with the antiquated Pubs database from way back in time because it is simple and small. We take the decision to have a collection that represents the titles (books) that are in the database.
It would make sense to show the author(s), publisher, the royalty schedule, and the sales of the book too. We could also include the publisher’s logo and various other data to but this will suffice to prove the point.
In SQL Server, we can produce a hierarchical array of documents, each of which represent a ‘title’ (a book to you or me). We use the FOR JSON keyword. We can do a similar trick in other relational databases (e.g. json_object in MySQL).
This emerges as follows (I show the first document only):
We are doing quite well, but what we have here is JSON, not Extended JSON, which is MongoDB’s preferred option.
Firstly, it is obvious that there is already a unique key that we can reuse for MongoDB. This means that if we can use this as the _id in MongoDB, we can then do lookups based on the title_id.
Our next problem will be the publication_date. It has been properly converted into an ISO Date but MongoDB needs an explicit declaration.
We therefore change the line:
This changes the initial JSON:
This will now use the title_id as the clustered index for the collection, and will recognize the date as a BSON date. Fine, we do the same to the order date.
We are making progress, but there is more to do. We have some money data here that ought to be rendered as NumberDecimal.
To do this we have to change the start of the SQL script slightly more:
Changing the JSON result rather more:
So we now can import this into MongoDB. We can do it from Studio 3T or from the command-line.
MongoDB collections are represented normally without the containing array (‘[‘ & ‘]’) but the import routines I’ll describe can cope with them. If necessary, you can specify whether you include them or not in the FOR JSON clause.
Here is the batch file if you are using Windows:
You will, of course need to fill in the path to your JSON file.
Creating a MongoDB collection by pasting JSON
A strikingly simple way of doing it with Studio 3T is to create a new collection, open the collection tab, and paste in the JSON.
Once it is in, we can use Studio 3T to check that the data received the correct data types.

We can also do a schema analysis through Schema Explorer to double check that the data is being imported consistently.
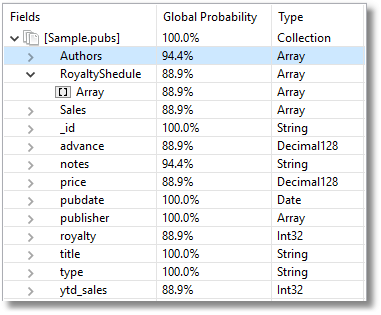
Probably the easiest way of checking an import is to open a collection in JSON View and then bring a single document into the Document JSON Editor.
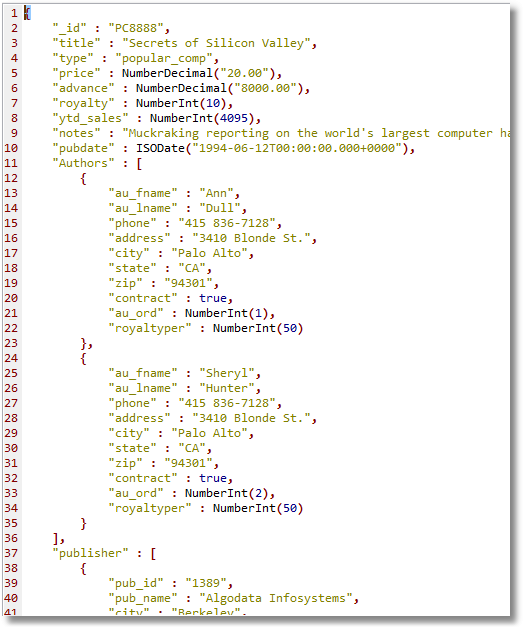
Ensuring the correct data types are transferred
With most SQL Server types, one needs to do nothing special to import them into MongoDB.
Text, ntext, sql_variant, varchar, nvarchar, nchar, char, uniqueidentifier, real, bit and Xml all get handled appropriately.
The hierarchy, geometry and geography types must be coerced into strings.
Varbinary and binary should be converted into binary hex or binary subtype but I haven’t yet fathomed the poor documentation about it.
The image, text and ntext types have to be coerced into their equivalent (MAX) types.
Usually floats and integers are correctly ported without being declared as $numberInt, but BigInts have to be given the extended JSON type of $numberLong. Money, as we’ve seen has to become $numberDecimal and dates have to be represented as $data
Dealing with simple arrays of data
There are some minor snags to deal with. The JSON facilities in SQL Server don’t deal with simple arrays. This doesn’t cause problems because one can use system functions string_Agg(), String_escape() and JSON_query() to make good the deficiencies.
Which gives:
In this case, I’ll just copy the JSON into the clipboard and create a new collection in Studio 3T.
I open up the collection tab (F10) for that collection (or by right-clicking and then choosing the ‘Open Collection Tab’ menu item) then click on the window and paste (Ctrl + V) the clipboard straight into the collection.

Now the hard stuff
So we have the technology in SQL Server to produce a collection that can be pasted straight into a collection. Is this the end of the story? Not really.
Now the work is to design effective collections for MongoDB that are going to optimal for the use of the MongoDB database.
Even with a ridiculously simple database such as the old Pubs, there are a number of different ways of rendering the tables as hierarchical information. We each have our own way of doing it, but it always boils down to understanding the schema of the data, the basic way that the data inter-relates and the nature of the underlying entities. Your data must reflect the way it is searched, and it must avoid duplication of the data. It mustn’t overdo the nesting of the arrays because of the complications of searching.
What’s next?
One of the features of MongoDB that have the potential to be a game-changer once refined is the use of JSON Schema. At the moment it is probably best to check data on the way in.
The problem, of course, is that JSON Schema looks at the ‘markup’ of data types in extended JSON that one has to include, and thinks it is part of the schema.
This means that one would have to create the schema document separately to conform with the imported BSON document. It would then have the BSON data types checked when documents were changed or inserted. I wonder if this could be done automatically somewhere in the process?