
The first two sections of this course walked you through the process of building an aggregate statement that retrieves data from the customers collection in the sales database. In the first section, you used IntelliShell to create the statement and save it to the states_transactions.js file. In the second section, you imported the file into the Aggregation Editor, where you added two stages to the pipeline. Together, these sections provided you with a foundation for working with aggregate statements in both IntelliShell and the Aggregation Editor.
In this section, you’ll refine the statement even further, again importing it into the Aggregation Editor. This time, you’ll add three more stages and update several existing stages. In one of the new stages, you’ll perform a lookup operation that retrieves data from a second collection in the same database. You’ll then convert values in one of the lookup fields and then add a field that uses those values to calculate ratios. Finally, you’ll limit the results of the aggregate statement to the top five documents with the highest ratios.
By the end of this section, you will learn how to
- Add lookup data to the aggregation pipeline
- Convert string values in one of the lookup fields to integers
- Add a computed ratio field based on the converted lookup field
- Limit the number of returned documents
What you will need
- Access to a MongoDB Atlas cluster
- Access to the states_transactions.js file you updated in the second section
- Ability to download a .json file from the internet
Working with advanced aggregate operators
The key to building an aggregate statement is to ensure that it includes the stages necessary to process the documents in the correct order and return the desired results. To help with these stages, MongoDB provides a set of aggregate operators that carry out different operations on the aggregation pipeline. Each stage within the pipeline is associated with a single aggregate operator that determines how the inputted documents will be processed and outputted to the next pipeline stage.
In the first two sections of this course, you worked with the following operators when building your aggregate statement:
- $match. Filters out all documents from the pipeline except those that match the specified condition.
- $group. Groups documents based on a specified expression and outputs a document for each grouping. The outputted documents typically include one or more computed fields that calculate the accumulated values.
- $project. Restructures each document in the pipeline by adding, retaining, reshaping, or suppressing fields.
- $replaceRoot. Replaces each document in the pipeline with the specified embedded document.
- $sort. Reorders the documents in the pipeline based on the specified sorting logic.
At this point, you should be fairly familiar with these operators, but if you have any questions about them, refer to the first two sections in this course or the MongoDB documentation.
$lookup
In this section of the course, you’ll learn how to use several other aggregate operators. The first of these is the $lookup operator, which joins documents in the primary collection with documents in a secondary collection. The primary collection is the one on which you base your aggregate statement. The secondary collection is the one that contains the data you’ll be incorporating into the aggregation pipeline based on matching values. To use the $lookup operator, the secondary collection must be non-sharded and be in the same database as the primary collection.
When you run a stage based on the $lookup operator, MongoDB adds an array field to each document in the primary collection. The array field includes one element for each document in the secondary collection that matches the conditions set by the operator. For example, if only one document matches the specified condition, the array will include only one element, which will contain the matching document.
The most basic type of lookup operation is referred to as an equity match. In an equity match, the documents in the primary collection contain a field that matches a field in the secondary collection. Documents are considered matching between the two collections when the field values are equal. The following syntax shows the elements needed to perform an equity match:
$lookup:
{
from: secondary_collection,
localField: primary_collection_field,
foreignField: secondary_collection_field,
as: new_array_field_name
}
The $lookup operator takes four arguments, which you pass into the operator as a document with four fields:
- The
fromargument specifies the name of the secondary collection, which must be in the same database. - The
localFieldargument specifies the name of the field in the primary collection on which the match is based. - The
foreignFieldargument specifies the name of the field in the secondary collection on which the match is based. - The
asargument specifies the name of the array field that will be added to the documents in the primary collection, or more precisely, to the documents in the aggregation pipeline. The array will contain the matching documents from the secondary collection.
To demonstrate how this works, suppose you have two collections—invoices and products—and you’re building an aggregate statement based on the invoices collection.
For each document in the invoices collection, you want to retrieve product-specific information from the products collection.
The product_sku field in the invoices collection matches the sku field in the products collection, so you can use these fields with the $lookup operator to perform an equity match, as shown in the following example:
db.invoices.aggregate([
{
$lookup:
{
from: "products",
localField: "product_sku",
foreignField: "sku",
as: "product_info"
}
}
])
The example should be fairly straightforward:
- The
fromargument specifiesproductsas the secondary collection. - The
localFieldargument specifies theproduct_skufield in theinvoicescollection. - The
foreignFieldargument specifies theskufield in theproductscollection. - The
asargument assigns the nameproduct_infoto the new array field added to the pipeline.
If you were to run this statement, it would return the documents in the invoices collection, and each document would contain the product_info array field, which would include an element for each matching document (or zero elements if there were no matching documents). The following figure shows an example of what the results might look like when displayed in Tree View.
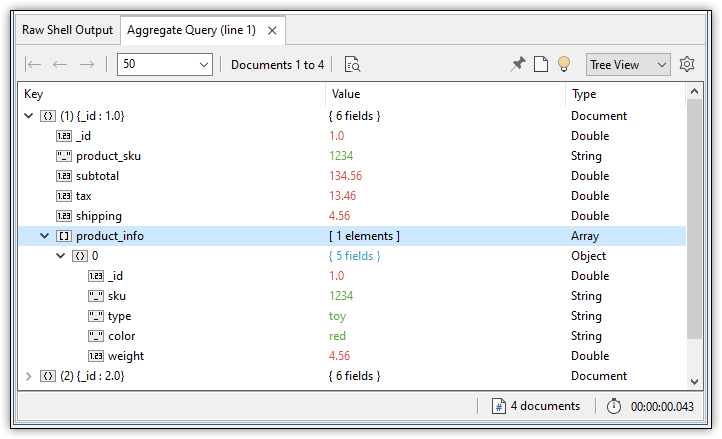
The first document in the results is expanded to show the product_info array and its elements. In this case, the array contains only one element, which means only one document in the products collection matched the specified criteria. Notice that the sku value in the product_info array has the same value as the product_sku value in the primary document. In the exercises to follow, you’ll get a closer look at the $lookup operator in action and the types of results you can expect.
$set
Another operator that we’ll cover in the exercises is the $set operator, which is an alias for the $addFields operator. The $set operator adds one or more fields to the aggregation pipeline, with the field values determined by the operator’s expression. If the name used for a new field is the same as an existing one, MongoDB overwrites the values in the existing field with the values defined in the operator’s expression.
The following syntax shows the elements that make up a $set expression:
$set: { new_field_name: field_expression, ... }
When using the $set operator to create a field, you must provide a field name, followed by an expression that defines the field’s values. For example, the following aggregate statement adds a field named total to the pipeline and uses the $add operator to set its value:
db.invoices.aggregate([
{
$set: { total: { $add: [ "$subtotal", "$tax", "$shipping" ] } }
}
])
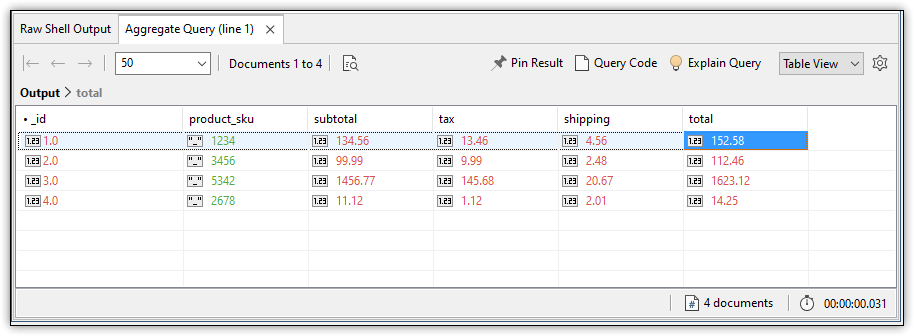
The $add operator adds together the values from the $subtotal, $tax and $shipping fields in the invoices collection. The total field is then added to the pipeline, along with the other fields in the collection’s documents. The following figure shows what the output data might look like after the new field has been added to the pipeline.
$limit
The exercises in this section also introduce you to the $limit operator, which limits the number of documents passed to the next stage in the pipeline. If you add a $limit stage directly after a $sort stage, without any intervening stages, MongoDB can coalesce the two stages to reduce the number of items that need to be stored in memory.
To use the $limit operator, you need only specify the operator name and a positive integer as its expression. The integer determines the maximum number of documents to include in the pipeline, as shown in the following syntax:
$limit: positive_integer
For example, if you want to limit the number of documents in the invoices collection to 25, you can define that stage as follows:
db.invoices.aggregate([ { $limit: 25 } ])
Now only the top 25 documents will be returned, based on how the documents are sorted when inputted into the $limit stage.

