Source: https://www.computerworlduk.com/data/what-is-sql-3681626/
SQL is the standard way of querying relational databases.
It has become the common way of talking about querying data that we can generally understand.
It isn’t intended for document databases, and it isn’t always appropriate. It has, for example, great difficulty with embedded arrays and other non-relational devices.
However, a SQL query is quite often a good way to start working on a MongoDB query.
It gets you started, and it is much easier to criticize and alter something already drafted than to create it from scratch.
In this article, I’ll show you various types of SQL join queries that benefit from this sort of approach and how you can fine-tune the automatically-generated MongoDB queries for better performance, or to get the output closer to what you need.
We’ll demonstrate this approach with INNER JOIN, queries with several JOINS, the IN clause, GROUP BY, and finally LEFT OUTER JOINS.
Talking to MongoDB with SQL
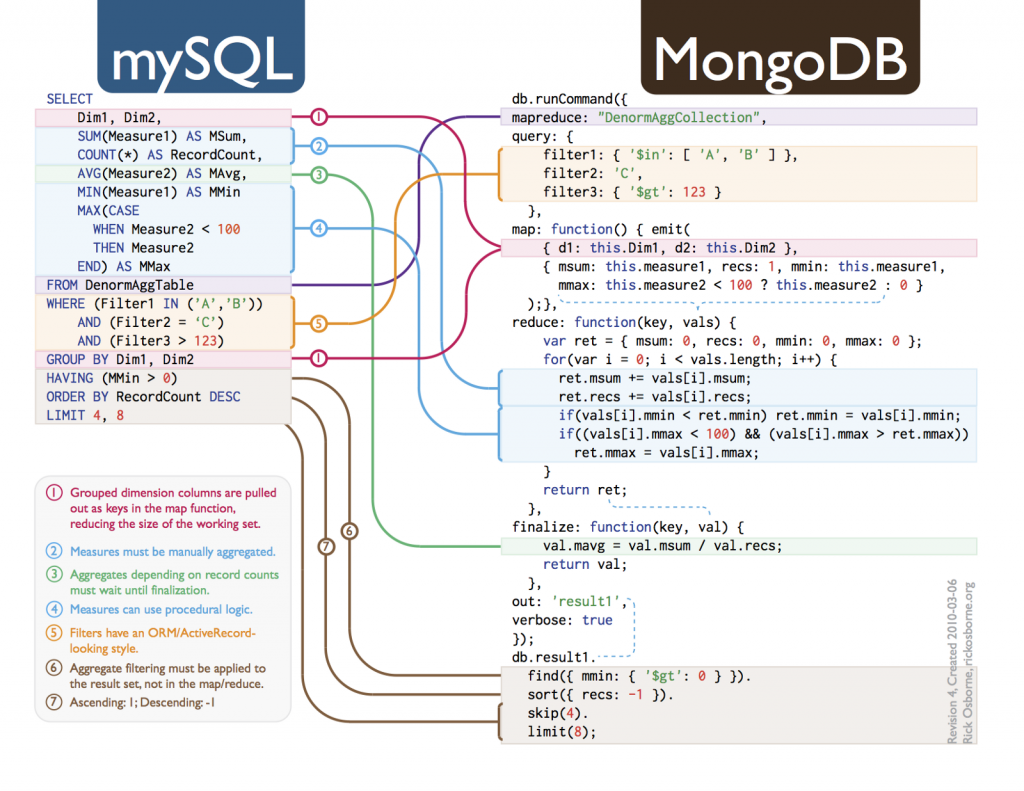
Source: https://rickosborne.org/download/SQL-to-MongoDB.pdf
If you can talk SQL, there are several third-party tools that allow you to use SQL to query and manipulate MongoDB databases.
From an application, you can use SQL as an alternative to shell queries if you use ODBC.
Any certified ODBC interface is obliged to have a pretty decent public standard subset of SQL implemented called ISO/IEC 9075-3:1995 (E) Call-Level Interface (SQL/CLI).
You can, with the ODBC text driver, even use SQL queries to interrogate or write to CSV or tab-delimited text files as if they were a database.
With an ODBC MongoDB driver from a reputable source, you can do the same thing: talk in SQL.
There is a handy chart provided by MongoDB that shows the equivalence between the two query languages, the SQL to MongoDB Mapping Chart.
There are also utilities for translation for queries that don’t involve joins, such as QueryMongo.
The MongoDB GUI Studio 3T takes it further with a different approach that allows you to produce and test the code from SQL and then fine-tune it, or modify it in a special aggregation window called Aggregation Editor. Studio 3T understands joins and aggregations.
Reservations to SQL and joins
Although I’ve more years of experience of SQL than I like to admit publicly, I am worried about using a relational language for a document database.
XML and JSON are uneasy fits into the relational model because there are different ways of joining document collections, particularly when there are embedded lists and objects.
There is no SQL equivalent, for example, to the request to search through a collection, to look through an array of objects within each document, and, if you get a match, return just the items of the list that match, and whatever other items you specify within the documents as part of the returned collection.
However, it is very convenient to use SQL occasionally to avoid the drudgery of keying in the basic aggregation, and then taking the resulting mongo shell code and altering it to your requirements.
SQL and Studio 3T
Studio 3T has a SQL Query feature that allows you to execute SQL in MongoDB.
It is interpreted directly into the Mongo shell language equivalent, with variants for commonly-used languages like JavaScript (Node.js), Java, Python, and C# so you can cut and paste the results directly into code.
It used to just interpret a very small number of simple queries, but it now does joins.
I generally use it to get started with an aggregate query that I can then transfer to the Aggregation Editor to fine-tune.
In this article, just to provide a SQL playground for MongoDB, I’ll be using an old Sybase relational database from the eighties, called Pubs.
Because it originally had very little data in it, it isn’t much used now but a large number of queries have been written using it. I’ve not used the original data, but instead created a much larger volume of spoof data and added a few things to exercise a database.
I’ve added a download link for the Pubs database at the end of this article, as a zipped directory of JSON files. Here it is, installed.
The tables in the original relational form have been imported using Studio 3T’s Import Wizard.
Each table appears as a collection in the Pubs database. This means, for instance, that data about publishers and titles are now separate, in two collections, requiring a JOIN to get at the full data.
The import routine does not convert primary keys to the MongoDB equivalent so we’ll need a few unique indexes to get this working properly.
Rather than just reproduce the original keys and references, we’ll start without them and add them to taste.
Why? Because we can see the improvement that comes from using the index, and may be able to provide covering queries that allow us to avoid accessing the actual document entirely.
Getting started with the SQL Query feature
We have a quick look at the titles collection in the collection view of Studio 3T.
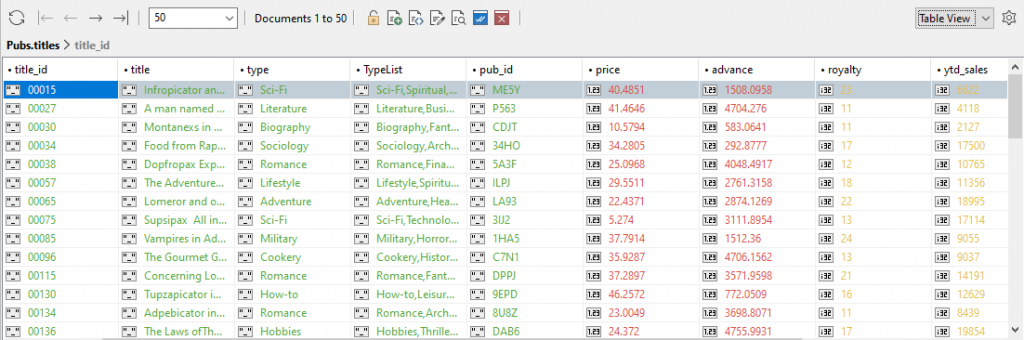
There is some interesting info to explore here.
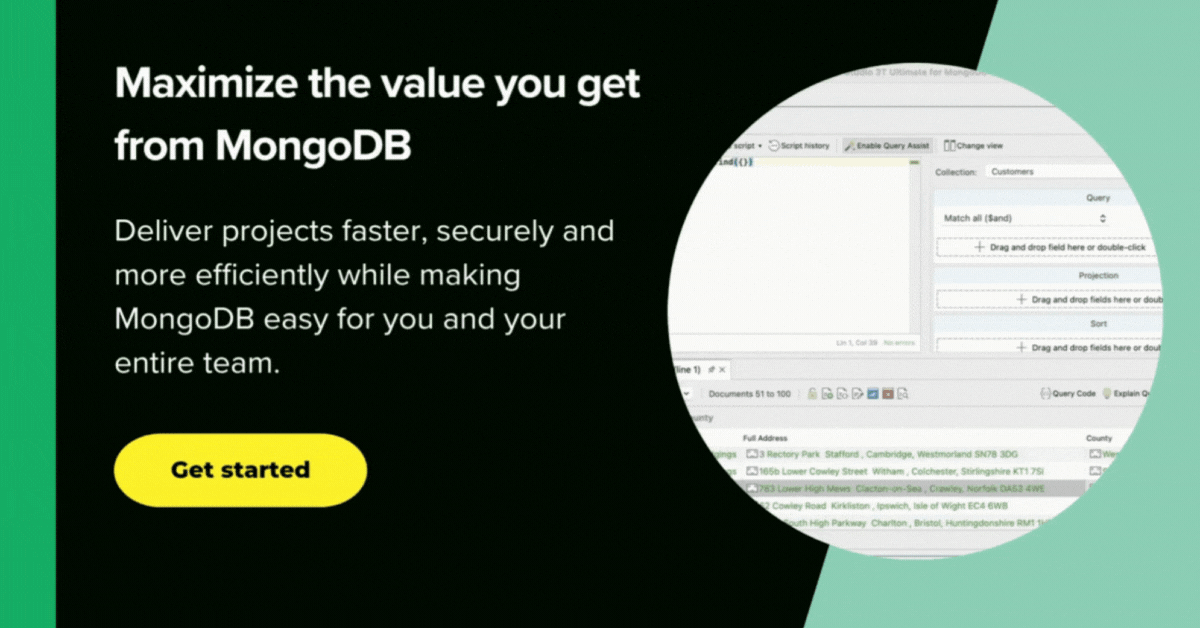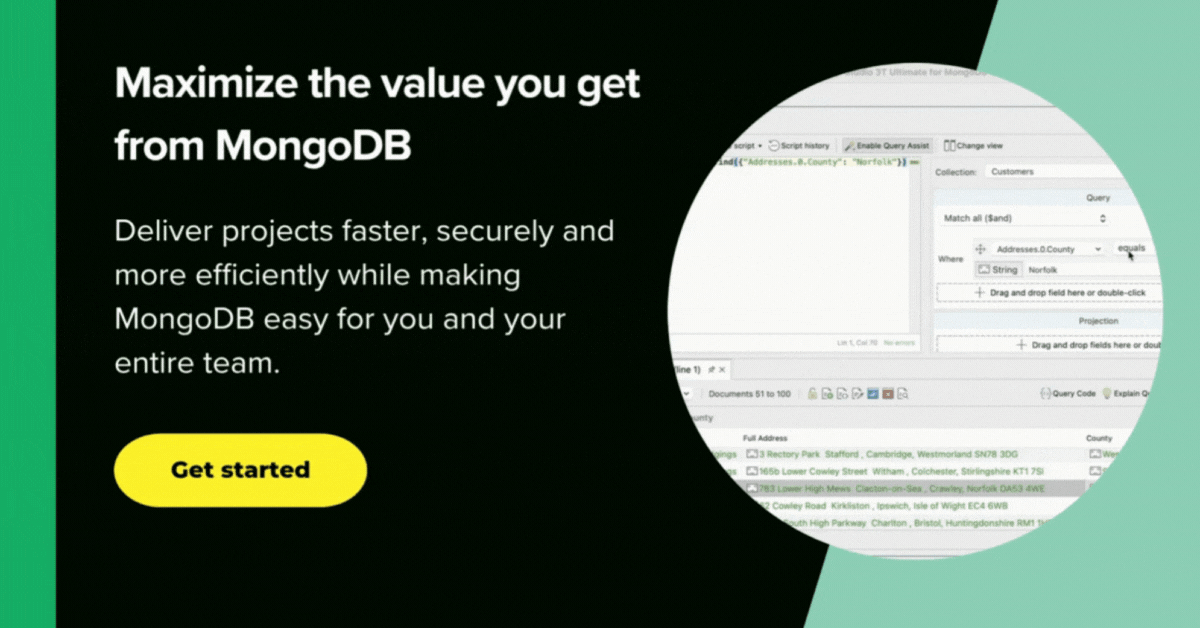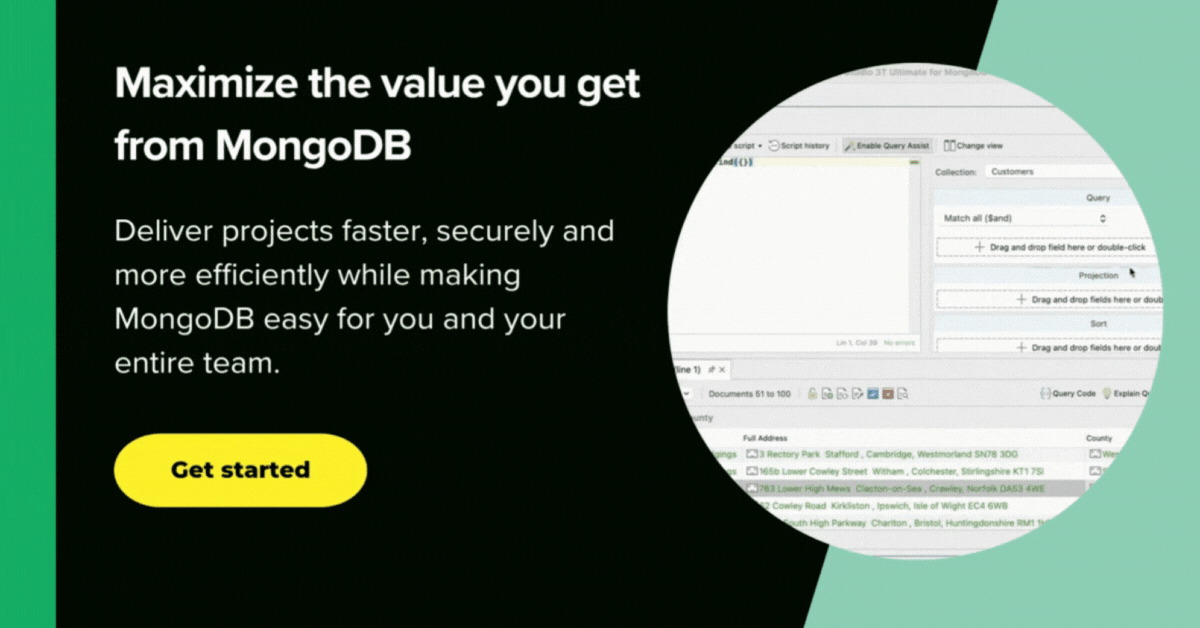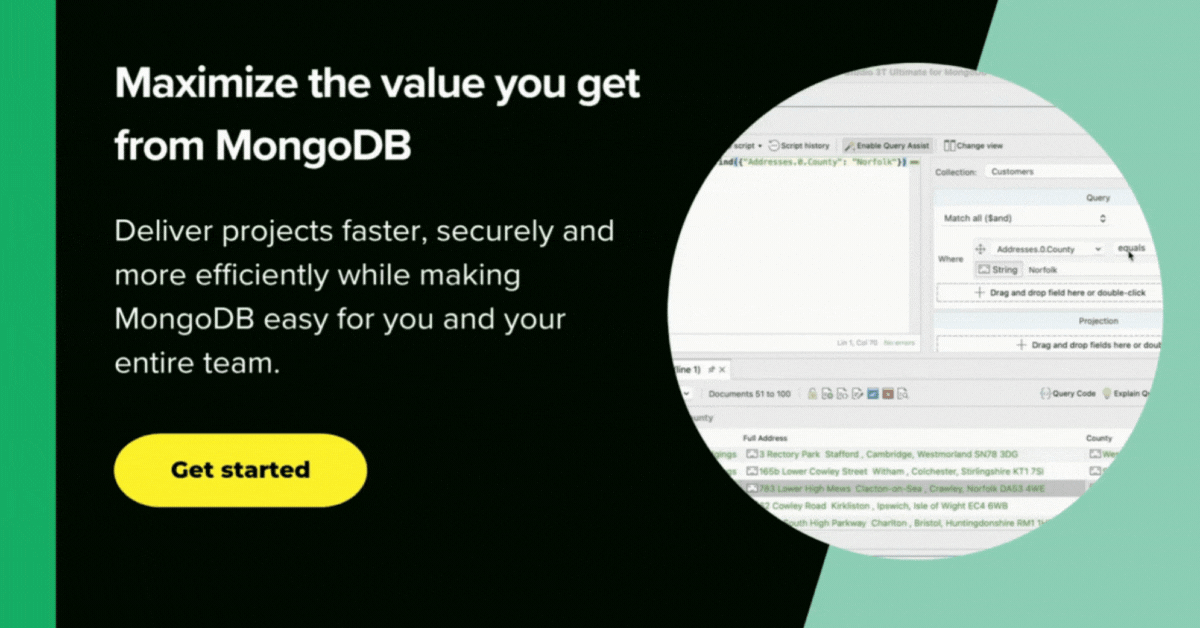
What titles, and of which type, start with the word ‘Secret’?
SELECT title FROM titles WHERE title LIKE 'Secret%';
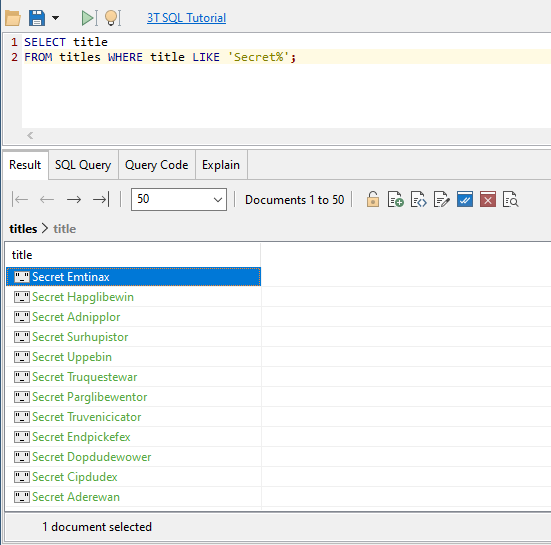
Please ignore the silly titles. I didn’t want to spend too much time to get ten thousand spoof titles.
The .find() method code that was actually executed was
use Pubs;
db.getCollection("titles").find(
{
"title" : /^Secret.*$/i
},
{
"title" : "$title",
"type" : "$type"
}
);
SQL INNER JOIN in MongoDB

Now for a join. What books are being published by one particular publisher?
In SQL-speak, we need to join the two ‘tables’ (collections) with an inner join to find out.
We select our Pubs database in the browser pane and click on the SQL menu item in Studio 3T’s global toolbar.
Then we tap in some SQL.
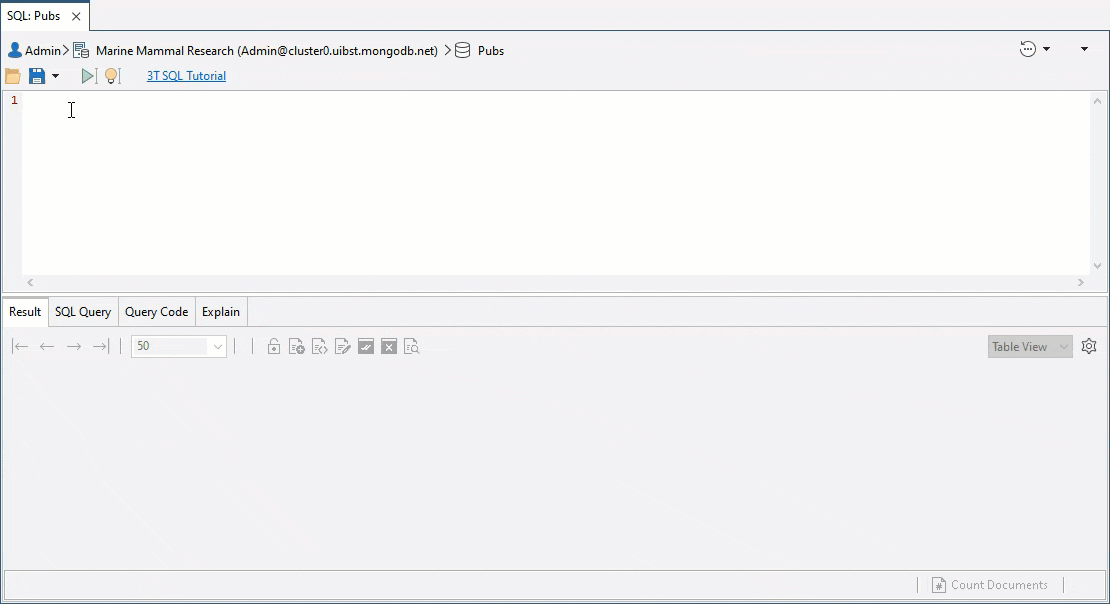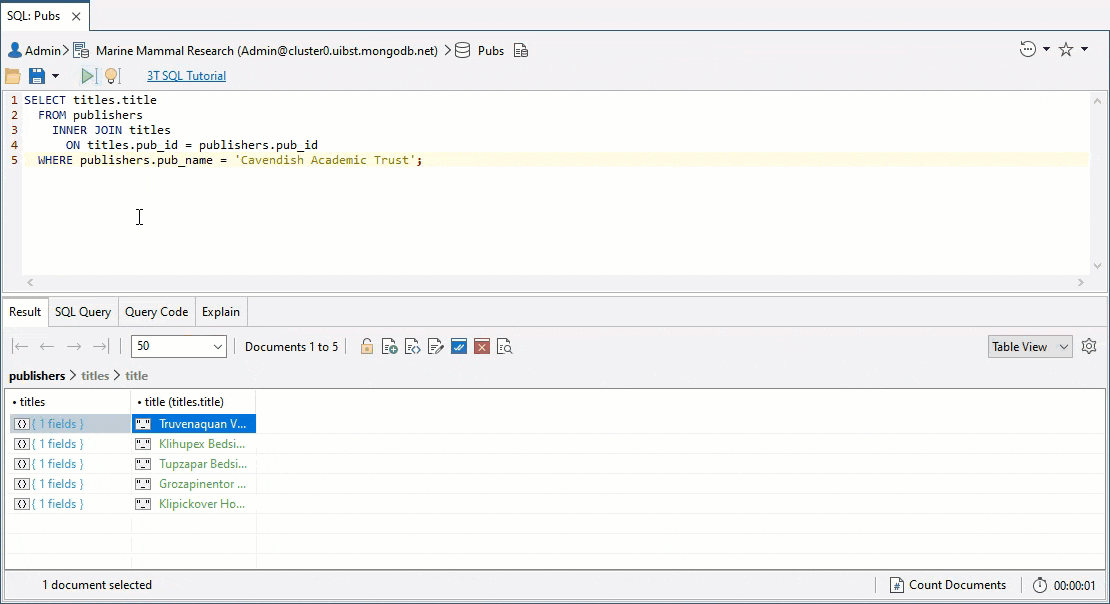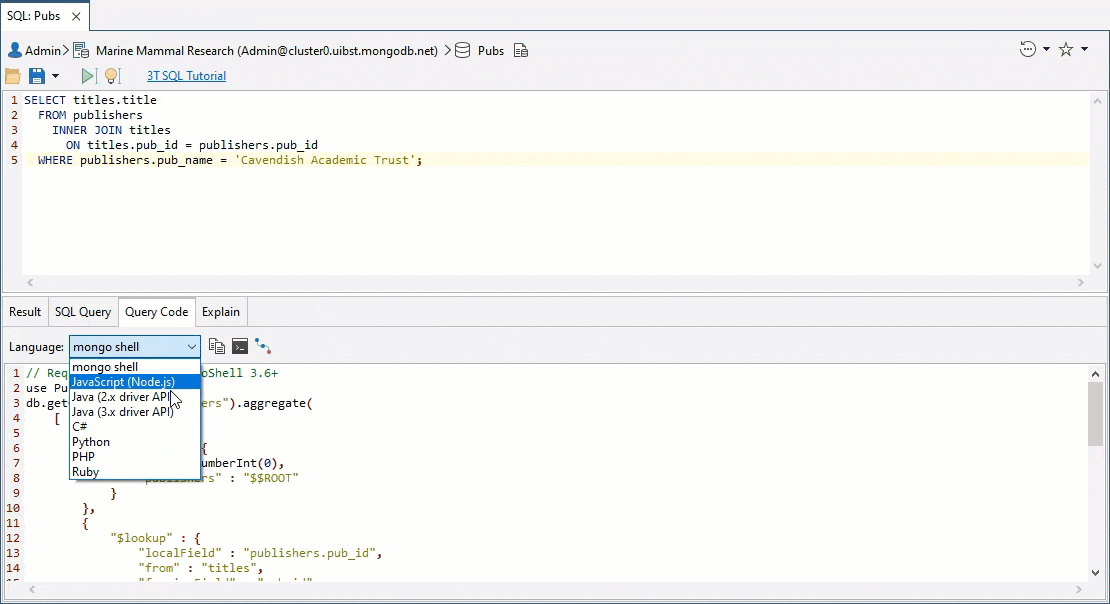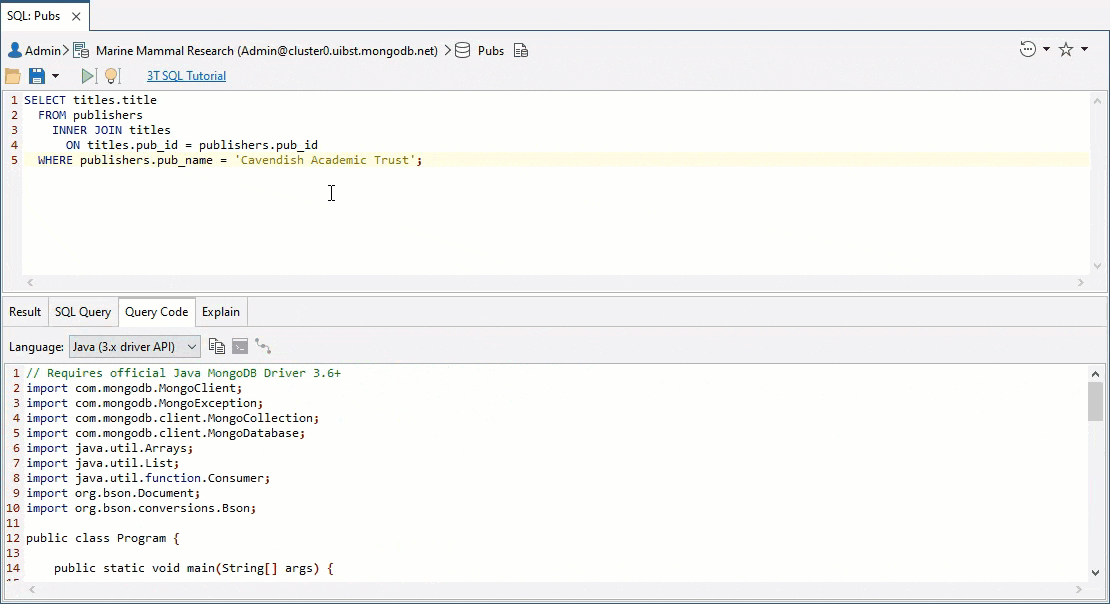
SELECT titles.title
FROM publishers
INNER JOIN titles
ON titles.pub_id = publishers.pub_id
WHERE publishers.pub_name = 'Cavendish Academic Trust';
We get a result!
{
"titles" : {
"title" : "Truvenaquan Volume 1"
}
}
{
"titles" : {
"title" : "Klihupex Bedside Book"
}
}
{
"titles" : {
"title" : "Tupzapar Bedside Book"
}
}
{
"titles" : {
"title" : "Grozapinentor Bedside Book"
}
}
{
"titles" : {
"title" : "Klipickover Horrors"
}
}
We can see from the ‘Explain’ tab that it had to do a collection scan (COLLSCAN) of the publishers table, all two thousand of them, to get the result.
Simply by changing the SQL a bit, we can make it go slower, and scan ten thousand documents to get the same result:
SELECT titles.title
FROM titles
INNER JOIN publishers
ON titles.pub_id = publishers.pub_id
WHERE publishers.pub_name = 'Cavendish Academic Trust';
There are more titles than there are publishers, so if each publisher has, say, five titles, then the publishers table will have five times as many documents as the titles collection.
Doing a lookup for every title is five times as many lookups as doing a lookup for every publisher. What we’ve done suggests that, when using this utility, it pays to put the smaller collection first.
In most relational databases, the order in which you specify the tables will make no difference because the query optimiser will work out the best way of doing it.
However, the optimiser has the advantage that it has a lot of extra information that it can use to make choices: any SQL interpreter can only translate literally from SQL to Javascript. We will need an index.
In the relational original of this database, the pub_id field was a primary key for the publishers and the foreign key for the titles. All MongoDB collections have an_id key that corresponds to a relational key. Unfortunately, our transfer of the PUBS database didn’t assign the primary key to the _id.
MongoDB aggregations generally can use just one index, but MongoDB can use a separate index under the covers for the $lookup stage. We can, and should, index the foreign key in a lookup, but we would do a lot better by drastically reducing the amount of data being accessed, and supporting that operation with an index.
When looking at the query, it is obvious that the best strategy is to locate the document in the publishers collection for the ‘Cavendish Academic Trust’ and get the pub_id value to get the titles that have that same value.
To help achieve that, we put the pub_name and pub_id in the index, in that order. This means that MongoDB can get the pub_name out of the index and altogether avoid pulling the publisher collection into memory.
db.publishers.createIndex(
{ 'pub_name': 1,'pub_id': 1 },
{ name: 'PublishersPubNamePubid' }
)
We run the query again and we can see from the profiler that it refuses to use the index. (see ‘How to Investigate MongoDB Query Performance’ on how to use the profiler to do this). This is because we still have work to do.
To do a join, we have to use an aggregate.
An aggregate can only use an index if the filtering ($match stage) is done first. This makes lots of sense when you think of the mechanics of implementing the query.
To do this, we get the mongo shell source code from the Query Code pane, and put it on the clipboard (Ctrl + A followed by Ctrl + C; or using the copy icon as shown below)
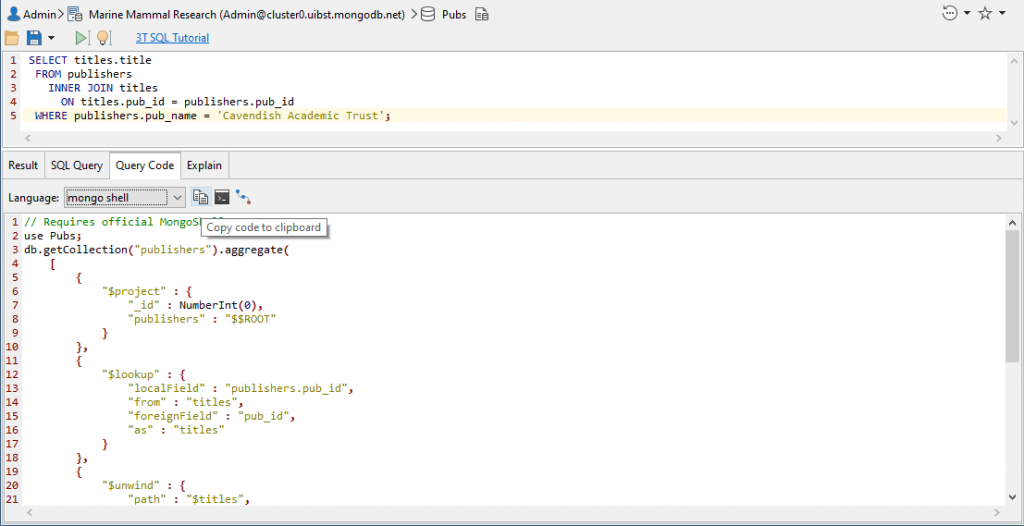
Now we open up Aggregation Editor and click on the paste button on the right.

Now the whole aggregation query appears as a list of stages.
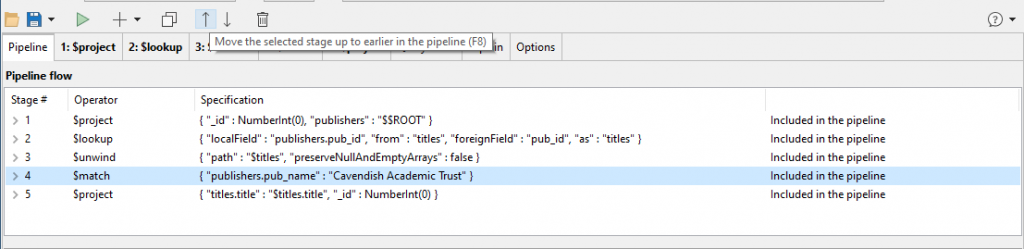
I’ve highlighted the match stage and I’m moving it up the sequence by clicking the up-arrow.
It should be the first thing that mongo does when executing the aggregate query, so we can move it with the ordering arrows.

Click, click, click. Now we need to edit this stage that we’ve just moved.
{
"publishers.pub_name" : "Cavendish Academic Trust"
}
Needs to be …
{
"pub_name" : "Cavendish Academic Trust"
}
…because the publishers object is now created later in the $project stage.
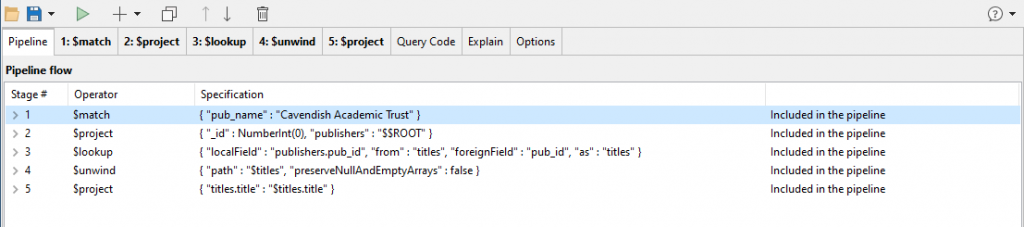
So we now do that by clicking on the tab where you see the mouse-pointer and editing the stage.
We now run it from the aggregation window and check the profile to see if it now uses an index scan (IXSCAN) rather than a collection scan (COLLSCAN). Yes, the query is now lightning fast, and uses our index. From the system.profile:
"millis" : 0,
"planSummary" : "IXSCAN { pub_name: 1, pub_id: 1 "},
For the result, I would like something nearer what a relational database would do: provide a list of documents providing a title. In real life, we’d probably want more than the title. I’d rewrite stage 5 to add the fields we want in the result with an alias (BookName in this example) and add a new projection to take out the two objects containing the joins.
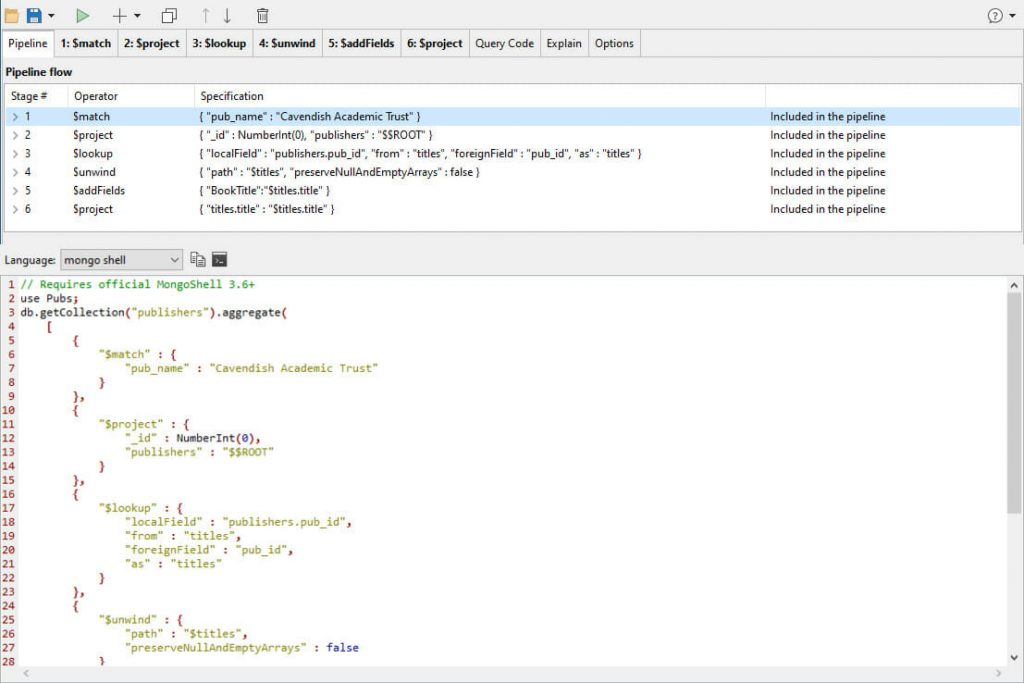
This gives the result …
{
"BookTitle" : "Truvenaquan Volume 1"
}
{
"BookTitle" : "Klihupex Bedside Book"
}
{
"BookTitle" : "Tupzapar Bedside Book"
}
{
"BookTitle" : "Grozapinentor Bedside Book"
}
{
"BookTitle" : "Klipickover Horrors"
}
This is a much neater result that has eliminated the embedded array that is created by the ‘lookup’ stage.
Queries with several joins
At this stage, we’ve achieved a reasonable result quickly, but we’re not satisfied. Who wrote the books, for example? What are their subject categories?
Authors, of course, can write several books, and books can have several authors, who share royalties. More than one author can have a particular name.
To keep things neat, and allow you to calculate royalties, revenue and author popularity, they have to have a separate collection and another collection that relates author to title.
Quickly, we tap in a SQL query:
SELECT titles.title, titles.type, authors.au_fname, authors.au_lname
FROM dbo.publishers
INNER JOIN dbo.titles
ON titles.pub_id = publishers.pub_id
INNER JOIN dbo.titleauthor
ON titleauthor.title_id = titles.title_id
INNER JOIN dbo.authors
ON authors.au_id = titleauthor.au_id
WHERE publishers.pub_name = 'Cavendish Academic Trust';
Here are the first two results.
{
"titles" : {
"title" : "Truvenaquan Volume 1",
"type" : "Military"
},
"authors" : {
"au_fname" : "Wanda",
"au_lname" : "Solomon"
}
}
{
"titles" : {
"title" : "Klihupex Bedside Book",
"type" : "Mystery"
},
"authors" : {
"au_fname" : "Norman",
"au_lname" : "Morton"
}
}
Now this may be enough for you. It is pretty fast, but I’m not easily satisfied.
Unless you are desperate for the last smidgen of performance, the existing indexes will do.
We can avoid a COLLSCAN by moving the $match stage up as before, and iron out those “authors” and “titles” objects since we don’t need them. (If we find a title with more than one author, we will need an embedded array.)
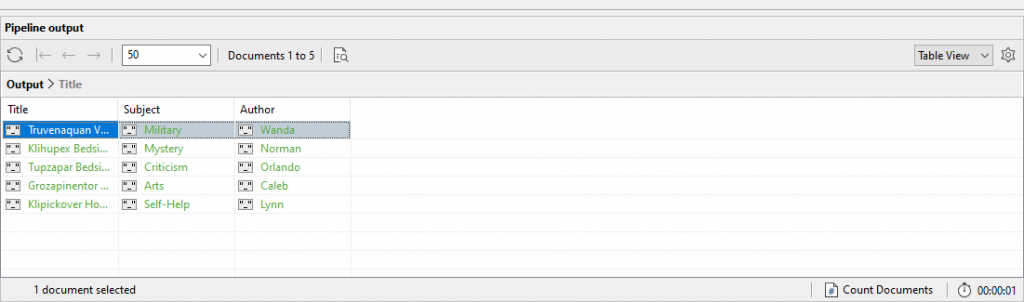
A quick check with the profiler shows that we are examining fewer documents and using the index.
The overall time hasn’t changed much because of all the unindexed joins going on – we can, and should, index a lookup with indexes on the foreign keys au_id and title_id. However, we have already tweaked the result to give us a more readable output.
The IN clause
There are some more SQL features that are supported.
You can provide a list with an IN clause within the WHERE filter.
This is used in SQL instead of giving a whole lot of OR conditions:
SELECT titles.title, publishers.pub_name
FROM publishers
INNER JOIN titles
ON titles.pub_id = publishers.pub_id
WHERE publishers.pub_name in
('Cavendish Academic Trust','Notley Academic Press','Abridge House')
ORDER BY titles.title
LIMIT 5
OFFSET 5
Which provides the result (in JSON):
{
"publishers" : {
"pub_name" : "Abridge House"
},
"titles" : {
"title" : "Healing Fromunover"
}
}
{
"publishers" : {
"pub_name" : "Cavendish Academic Trust"
},
"titles" : {
"title" : "Klihupex Bedside Book"
}
}
{
"publishers" : {
"pub_name" : "Cavendish Academic Trust"
},
"titles" : {
"title" : "Klipickover Horrors"
}
}
{
"publishers" : {
"pub_name" : "Notley Academic Press"
},
"titles" : {
"title" : "Legends of Sursapex"
}
}
{
"publishers" : {
"pub_name" : "Abridge House"
},
"titles" : {
"title" : "Moral Uperiman"
}
}
GROUP BY and reporting
The use of aggregation functions with GROUP BY is likely to be the most useful. Which, for example, are the top ten most profitable topics or types?
SELECT Sum(ytd_sales), type FROM titles GROUP BY type ORDER BY Sum(ytd_sales) DESC LIMIT 10 ;
Slightly changing the field names by changing the generated code slightly gives us…
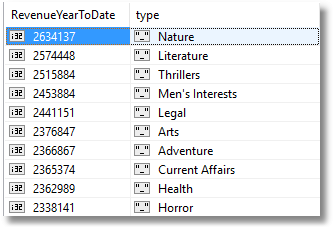
Which are the top twenty most profitable publishers in the year to date?
SELECT Sum(titles.ytd_sales), publishers.pub_name
FROM titles
INNER JOIN publishers
ON titles.pub_id = publishers.pub_id
GROUP BY publishers.pub_name
ORDER BY Sum(titles.ytd_sales) desc
LIMIT 20
With a bit of tweaking of field names, we can make it a bit pretty.
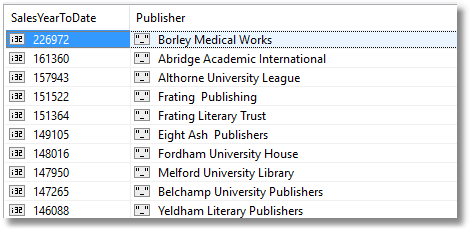
LEFT OUTER JOINs
We can do outer joins. These are handy where we want to find out what isn’t part of a relationship between documents.
To give a practical example, how many of our titles don’t have a publisher? (Probably self-published!)
SELECT Count(*)
FROM titles
LEFT OUTER JOIN publishers
ON titles.pub_id = publishers.pub_id
WHERE publishers.pub_id IS NULL
The answer is 105.
{
"COUNT(*)" : NumberInt(105)
}
OK. What sort of titles are they without publishers, and who wrote them?
The query is this, but please don’t try executing it. It will take a very long time without modification.
SELECT titles.title, titles.type, authors.au_fname, authors.au_lname
FROM dbo.titles
INNER JOIN dbo.titleauthor
ON titleauthor.title_id = titles.title_id
INNER JOIN dbo.authors
ON authors.au_id = titleauthor.au_id
LEFT OUTER JOIN publishers
ON titles.pub_id = publishers.pub_id
WHERE publishers.pub_id IS NULL
It produces code that isn’t in the best order for performance.
The first join must always do the most filtering. We just copy the code and paste it into an aggregation window for coarse tuning.
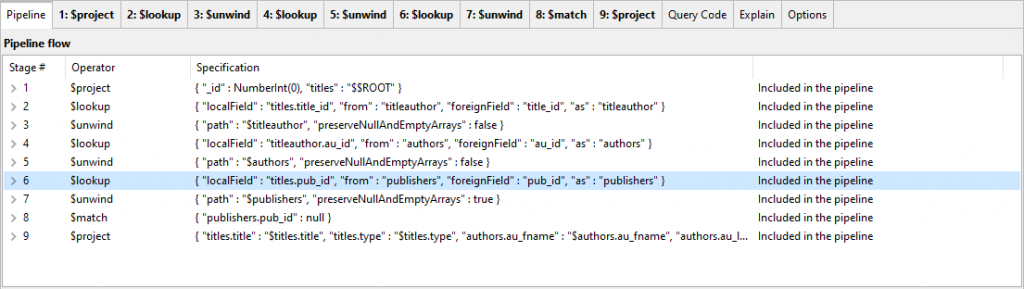
Stages 6, 7 and 8 need to be moved up the order to be straight after the first projection.
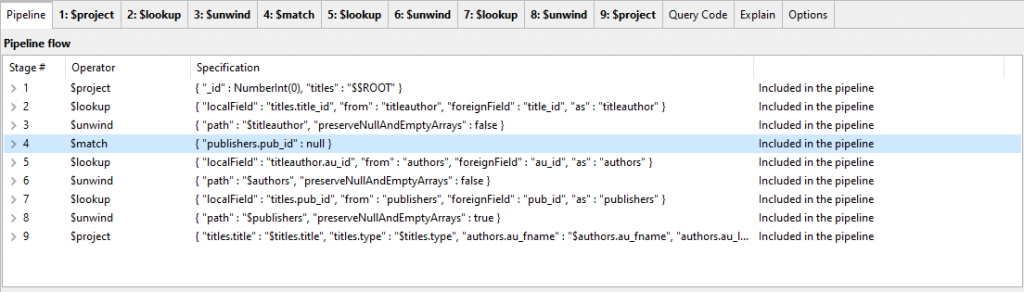
This gets the query working in around 2.6 seconds on our test server. Can we do any fine tuning?
The titles that have no publisher have nulls in them. We could cut out the outer join entirely and just filter via an initial indexed $match.
However, we’re trying to illustrate an outer join and so we won’t do that. This optimisation will not apply to many outer join queries.
We can get it down to 2.2 seconds by reducing what is passed down the pipeline to just the data we want. That first $project stage can be reduced from taking the entire document down the pipeline
{
"_id" : NumberInt(0),
"titles" : "$ROOT"
}
…to just the data we actually need.
{
"_id" : NumberInt(0),
"titles.title" : "$title",
"titles.title_id" : "$title_id",
"titles.type" : "$type",
"titles.pub_id" : "$pub_id"
}
So you can see that the SQL Query feature can get you started, but there is generally more work to be done to get the query exactly as you want it.
Using SQL Query to get a head start
Even when the SQL window can’t give us the entire query in the form we want, it can give us a really good start, and it is far quicker for someone with SQL skills than hand-cutting mongo shell aggregate queries.
Imagine we want a list of the number of titles published by year ordered by year.
We can’t group by year from the SQL window, but we can tap in a rough query that we can tidy up to our requirement
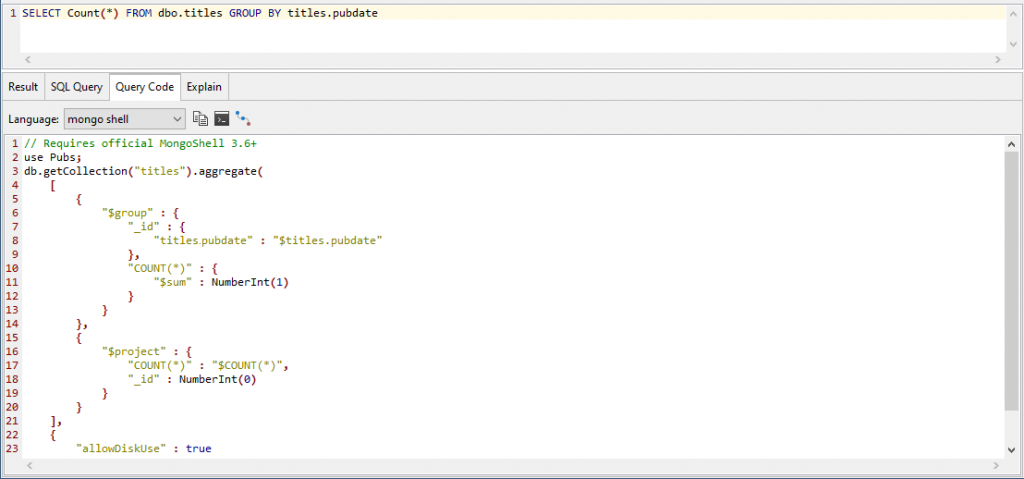
Yes, it isn’t what we want, because each title was published at a different date so the $count value will always be 1.
We put that mongo shell code in the Aggregation Editor as I’ve already demonstrated, and fix things, testing as we go, to produce this.
use Pubs;
db.getCollection("titles").aggregate(
[
{
"$group" : {
"_id" : {
"Year" : {
"$year" : "$pubdate"
}
},
"NumberPublished" : {
"$sum" : NumberInt(1)
}
}
},
{
"$addFields" : {
"Year" : "$_id.Year"
}
},
{
"$project" : {
"_id" : NumberInt(0)
}
},
{
"$sort" : {
"Year" : 1.0
}
}
],
{
"allowDiskUse" : false
}
);
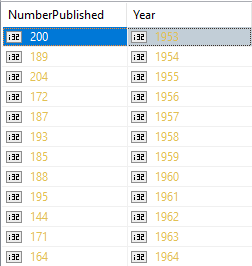
This code then gives us what we want in a simple form
Conclusions
The idea of longing for SQL when using MongoDB seems absurd, like longing for nice pots of tea with cream buns when in Italy.
After having used various approaches with MongoDB, I can agree that there is a certain tedium in getting started with a complex MongoDB aggregation.
There are two facilities in Studio 3T that turn it into a pleasure: Firstly, using the SQL Query feature to rough out a working query via GROUP BY and JOIN, and secondly, fine tuning the resulting mongo shell query in a controlled way using the Aggregation Editor, where you can test every stage independently and change the order for best performance.
That way, you can get aggregations that perform well, and do it quickly.
Downloads
Download the collections used in this article to create your own Pubs database and try out the example queries.