The first two MongoDB courses—101 and 201—introduced you to the basics of how to aggregate document data in Studio 3T. As you’ll recall, aggregations make it possible to better understand the data and mine valuable information, which can help stakeholders make strategic business decisions. This course expands on those discussions to provide a more complete picture of how to aggregate data in Studio 3T to gain deeper insights into the stored documents.
At the heart of MongoDB aggregations is the mongo shell aggregate method, which enables you to aggregate document data within a specific collection. Even if you use the Studio 3T Aggregation Editor to build your aggregations, the aggregate method is still working behind the scenes to carry out the aggregation. The Aggregation Editor will even generate the aggregate statement that’s being used, which you can copy, save, and modify as needed. For this reason, the better you understand how the aggregate method works, the greater benefit you can derive from Aggregation Editor and the easier it is to modify aggregate statements no matter where they’re generated.
In this section of the course, you’ll learn how to build a mongo shell statement that’s based on the aggregate method. The exercises in this section aggregate data in the customers collection, which you’ll import as part of the first exercise (unless you already imported the collection when working through the MongoDB 201 course). In the exercises, you’ll learn how to use the aggregate method to create an aggregation pipeline that includes three stages. You’ll also learn how to add options to your aggregate statement for better controlling how the aggregation is processed.
By the end of this section, you will learn how to
- Filter the documents in the aggregation pipeline
- Group the documents in the aggregation pipeline
- Sort the documents in the aggregation pipeline
- Add processing options to your aggregate statement
What you will need
- Access to a MongoDB Atlas cluster
- Ability to download a .json file from the internet
- Access to Studio 3T – download it here.
Building a MongoDB aggregation
MongoDB provides the aggregate method for aggregating document data in a collection. You call the method from a collection object, using the following syntax:
db.getCollection(collection).aggregate(pipeline, options)
When building your statement, replace the collection placeholder with the actual collection name, followed by the aggregate method and its two arguments: pipeline and options.
The pipeline placeholder represents the script elements that make up the aggregation pipeline. This is where most of the work occurs. The pipeline is broken into one or more stages, which are separated by commas and enclosed in square brackets, as indicated in the following syntax:
pipeline ::= [stage, ...]
The stages are enclosed in brackets because they’re part of an array. In this respect, each stage is an array element that’s made up of an aggregate method and its expression, both enclosed in a set of curly braces:
stage ::= { aggregate_method: expression }
MongoDB runs the stages in the order specified in the pipeline until all stages have been completed. The pipeline is a linear process, with each stage building on the previous stage to produce the final data set.
In addition to the pipeline, you can include one or more options in your statement to better control how the aggregation is processed. The options are enclosed in curly braces and separated with commas, as shown in the following syntax:
option ::= {option, ...}
Although options are not mandatory, they must follow a specific format if you do include them. You should place the options right after the pipeline definition, with a comma separating the pipeline from the options.
The options are passed to the aggregate method as a document that contains one or more fields for defining the option settings. Each field consists of an option name and its value, as shown in the following syntax:
option ::= option_name: option_value
The format of the option value depends on which option you’re setting. It might be a simple scalar value, such as false, or a more complex expression. If you include multiple options, you must separate them with commas.
The best way to understand the aggregate syntax is to see it in action. The following statement provides a simple example of an aggregation based on the customers collection in the sales database:
use sales;
db.getCollection("customers").aggregate(
[
{ "$match": { "address.state": "Washington" } },
{ "$group":
{ "_id": "$address.city", "totals": { "$sum": "$transactions" } } },
{ "$sort": { "_id": 1.0 } }
],
{
"allowDiskUse": true,
"collation": { "locale" : "en_US" }
}
);The aggregate method takes two arguments: the pipeline and a set of options. The pipeline is enclosed in square brackets and includes three stages, each enclosed in curly braces.
Stage 1 uses the $match operator to filter the documents based on the values in the address.state field. Because the aggregate expression specifies the value Washington, only documents with an address.state value of Washington are included in the stage’s results. The filtered results are then passed onto the next stage in the pipeline.
Stage 2 uses the $group operator to group the documents returned by the first stage. The expression for this operator is divided into two parts. The first part (_id": "$address.city") indicates that the results should be grouped based on the address.city field. Notice that the address.city field name is preceded by a dollar sign. When referencing a field in an operator expression, you typically precede the field name with a dollar sign and enclose it in quotes.
The _id field is an exception to this rule. It’s a default field that’s assigned to the distinct values extracted from that target field when grouping data. In this case, the target field is address.city.
The second part of the stage 2 expression ("totals": { "$sum": "$transactions" }) defines a new field named totals. The field will hold the total number of transactions for each city. The $sum accumulator operator adds the values in the transactions field together for each city.
Stage 3 uses the $sort operator to sort the documents in the pipeline. The operator’s expression first specifies the field on which to base the sorting operation and then specifies the sort order. A value of 1 indicates that the documents should be sorted in ascending order, and a value of -1 indicates that they should be sorted in descending order.
In addition to the pipeline definition, the aggregate statement includes two processing options, which come after the pipeline definition:
- The
allowDiskUseoption controls whether aggregation operations can write data to temporary files on disk. If set tofalse, which is the default setting, data cannot be written to temporary files. If set to true, data can be written to temporary files. - The
collationoption sets the collation settings, which can take multiple values. In this case, only thelocalesetting is included, and its value is defined asen_US, which sets the collation to United States English.
If you run the aggregate statement in IntelliShell, you’ll get the results shown in the following figure. The results include the total number of transactions for each distinct value in the address.city field.
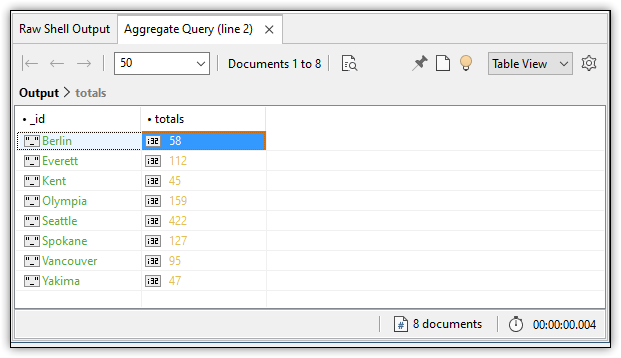
Although this aggregate statement is relatively simple, it demonstrates the basic principles of defining an aggregation. It includes multiple stages in the pipeline, as well as multiple processing options. You can add more stages or options as necessary.

