
Wenn Sie anfangen, mit MongoDB zu arbeiten, werden Sie normalerweise die find() Befehl für eine breite Palette von Abfragen. Sobald Ihre Abfragen jedoch fortgeschrittener werden, müssen Sie mehr über die MongoDB-Aggregation wissen.
In diesem Artikel erkläre ich die Hauptprinzipien der Erstellung von Aggregatabfragen in MongoDB und wie man die Vorteile von Indizes nutzen kann, um sie zu beschleunigen.
Darüber hinaus werde ich die wichtigsten Schritte der Aggregationspipeline mit kurzen Beispielen vorstellen und erläutern, wie sie in der Pipeline angewendet werden können.

Was ist Aggregation in MongoDB?
Die Aggregation ist eine Methode zur Verarbeitung einer großen Anzahl von Dokumenten in einer Sammlung, indem sie verschiedene Stufen durchläuft. Die Stufen bilden eine so genannte Pipeline. Die Stufen in einer Pipeline können Dokumente, die die Pipeline durchlaufen, filtern, sortieren, gruppieren, umgestalten und verändern.
Einer der häufigsten Anwendungsfälle von Aggregation ist die Berechnung von Aggregatwerten für Gruppen von Dokumenten. Dies ähnelt der grundlegenden Aggregation, die in SQL mit der GROUP BY-Klausel und den Funktionen COUNT, SUM und AVG möglich ist. Die MongoDB-Aggregation geht jedoch noch weiter und kann auch relationale Joins durchführen, Dokumente umgestalten, neue Sammlungen erstellen und bestehende aktualisieren und so weiter.
Es gibt zwar auch andere Methoden, um aggregierte Daten in MongoDB zu erhalten, aber das Aggregations-Framework ist der empfohlene Ansatz für die meisten Arbeiten.
Es gibt so genannte Einzweckmethoden wie estimatedDocumentCount(), count()und distinct() die an ein find() Dadurch sind sie zwar schnell einsetzbar, aber in ihrem Umfang begrenzt.
Das Map-Reduce-Framework von MongoDB ist ein Vorgänger des Aggregations-Frameworks und wesentlich komplexer in der Anwendung.
Wie funktioniert die MongoDB-Aggregationspipeline?
Das folgende Diagramm veranschaulicht eine typische MongoDB-Aggregationspipeline.
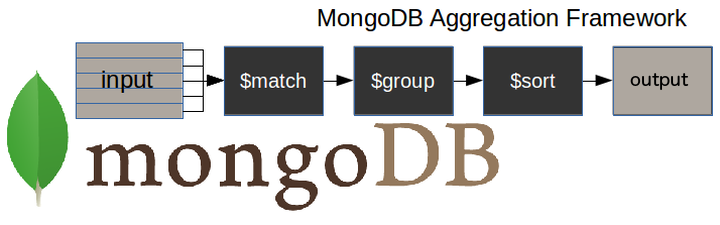
$matchStufe - filtert die Dokumente heraus, die wir benötigen und die unseren Anforderungen entsprechen$groupStufe - erledigt die Aggregation$sortstage - sortiert die resultierenden Dokumente wie gewünscht (aufsteigend oder absteigend)
Die Eingabe der Pipeline kann eine einzelne Sammlung sein, wobei andere später in der Pipeline zusammengeführt werden können.
Die Pipeline führt dann sukzessive Transformationen an den Daten durch, bis unser Ziel erreicht ist.
Auf diese Weise können wir eine komplexe Abfrage in einfachere Phasen unterteilen, in denen wir jeweils eine andere Operation an den Daten durchführen. Am Ende der Abfrage-Pipeline haben wir also alles erreicht, was wir wollten.
Mit diesem Ansatz können wir überprüfen, ob unsere Abfrage in jeder Phase ordnungsgemäß funktioniert, indem wir sowohl ihre Eingabe als auch ihre Ausgabe untersuchen. Die Ausgabe jeder Stufe ist die Eingabe für die nächste Stufe.

Es gibt keine Begrenzung für die Anzahl der Stufen, die in der Abfrage verwendet werden, oder dafür, wie wir sie kombinieren.
Um eine optimale Abfrageleistung zu erzielen, sind eine Reihe von bewährten Verfahren zu berücksichtigen. Wir werden später in diesem Artikel auf diese eingehen.
Syntax für MongoDB-Aggregat-Pipelines
Dies ist ein Beispiel dafür, wie man eine Aggregationsabfrage erstellt:
db.collectionName.aggregate(pipeline, options),
- wobei collectionName - der Name einer Sammlung ist,
- pipeline - ist ein Array, das die Aggregationsstufen enthält,
- options - optionale Parameter für die Aggregation
Dies ist ein Beispiel für die Syntax der Aggregationspipeline:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
Grenzen der MongoDB-Aggregationsstufe
Die Aggregation arbeitet im Speicher. Jede Stufe kann bis zu 100 MB RAM verwenden. Wenn Sie diese Grenze überschreiten, erhalten Sie von der Datenbank eine Fehlermeldung.
Wenn dies zu einem unvermeidlichen Problem wird, können Sie sich für die Auslagerung auf die Festplatte entscheiden, mit dem einzigen Nachteil, dass Sie etwas länger warten müssen, weil die Arbeit auf der Festplatte langsamer ist als im Speicher. Um die Methode des Auslagerns auf die Festplatte zu wählen, müssen Sie nur die Option allowDiskUse auf diese Weise wahr:
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
Beachten Sie, dass diese Option für gemeinsam genutzte Dienste nicht immer verfügbar ist. Bei den Clustern Atlas M0, M2 und M5 ist diese Option beispielsweise deaktiviert.
Die von der Aggregationsabfrage zurückgegebenen Dokumente, entweder als Cursor oder gespeichert über $out in einer anderen Sammlung, sind auf 16 MB begrenzt. Das heißt, sie können nicht größer sein als die maximale Größe eines MongoDB-Dokuments.
Wenn Sie diese Grenze voraussichtlich überschreiten werden, sollten Sie festlegen, dass die Ausgabe der Aggregationsabfrage als Cursor und nicht als Dokument erfolgt.
Unsere Daten für MongoDB-Aggregat-Beispiele
Ich werde Beispiele für MongoDB-Aggregate für die wichtigsten Pipelinestufen zeigen.
Um die Beispiele zu veranschaulichen, werde ich zwei Sammlungen verwenden. Die erste heißt 'universities' und setzt sich aus diesen Dokumenten zusammen (die Daten sind nicht echt):
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
Wenn Sie diese Beispiele auf Ihrer eigenen Installation testen möchten, können Sie sie mit dem unten stehenden Massenbefehl einfügen.
use 3tdb
db.universities.insertMany([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
])
Die zweite und letzte Sammlung heißt 'courses' und sieht wie folgt aus:
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
}
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
}
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
Auch hier können Sie sie auf dieselbe Weise einfügen, indem Sie den folgenden Code verwenden:
db.courses.insertMany([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
])
Beispiele für MongoDB-Aggregate
MongoDB $match
Die $match stage ermöglicht es uns, nur die Dokumente aus einer Sammlung auszuwählen, mit denen wir arbeiten wollen. Zu diesem Zweck werden diejenigen herausgefiltert, die nicht unseren Anforderungen entsprechen.
Im folgenden Beispiel wollen wir nur mit den Dokumenten arbeiten, die angeben, dass Spain ist der Wert des Feldes countryund Salamanca ist der Wert des Feldes city.
Um eine lesbare Ausgabe zu erhalten, werde ich Folgendes hinzufügen .pretty() am Ende aller Befehle.
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
]).pretty()
Die Ausgabe ist...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain","city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
]
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdbaa"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "UPSA",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6691191,
17,
40.9631732
]
},
"students" : [
{
"year" : 2014,
"number" : 4788
},
{
"year" : 2015,
"number" : 4821
},
{
"year" : 2016,
"number" : 6550
},
{
"year" : 2017,
"number" : 6125
}
]
}
MongoDB $Projekt
Es ist selten, dass Sie alle Felder in Ihren Dokumenten abrufen müssen. Es ist eine gute Praxis, nur die Felder zurückzugeben, die Sie benötigen, um nicht mehr Daten als nötig zu verarbeiten.
Die $project wird dazu verwendet, um dies zu tun und um alle benötigten berechneten Felder hinzuzufügen.
In diesem Beispiel benötigen wir nur die Felder country, cityund name.
Bitte beachten Sie im folgenden Code, dass:
- Wir müssen ausdrücklich schreiben
_id : 0wenn dieses Feld nicht erforderlich ist - Neben der
_idist es ausreichend, nur die Felder anzugeben, die wir als Ergebnis der Abfrage benötigen
Diese Phase ...
db.universities.aggregate([
{ $project : { _id : 0, country : 1, city : 1, name : 1 } }
]).pretty()
...wird das Ergebnis ...
{ "country" : "Spain", "city" : "Salamanca", "name" : "USAL" }
{ "country" : "Spain", "city" : "Salamanca", "name" : "UPSA" }
MongoDB $Gruppe
Mit dem $group können alle erforderlichen Aggregations- oder Zusammenfassungsabfragen durchgeführt werden, wie z. B. die Ermittlung von Zählungen, Summen, Durchschnittswerten oder Maximalwerten.
In diesem Beispiel möchten wir die Anzahl der Dokumente pro Universität in unserem 'universities' Sammlung:
Die Abfrage ...
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } }
]).pretty()
... führt zu diesem Ergebnis ...
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
MongoDB $group Aggregationsoperatoren
Die $group-Stufe unterstützt bestimmte Ausdrücke (Operatoren), mit denen der Benutzer arithmetische, Array-, boolesche und andere Operationen als Teil der Aggregationspipeline durchführen kann.
| Betreiber | Bedeutung |
| $Zahl | Berechnet die Anzahl der Dokumente in der angegebenen Gruppe. |
| $max | Zeigt den Höchstwert des Feldes eines Dokuments in der Sammlung an. |
| $min | Zeigt den Mindestwert des Feldes eines Dokuments in der Sammlung an. |
| $avg | Zeigt den Durchschnittswert des Feldes eines Dokuments in der Sammlung an. |
| $sum | Summiert die angegebenen Werte aller Dokumente in der Sammlung. |
| $push | Fügt zusätzliche Werte in das Array des Ergebnisdokuments ein. |
Sehen Sie sich die MongoDB-Operatoren unter an und erfahren Sie mehr über andere Operatoren.
MongoDB $out
Dies ist eine ungewöhnliche Art von Stufe, denn sie ermöglicht es Ihnen, die Ergebnisse Ihrer Aggregation in eine neue Sammlung oder in eine bestehende Sammlung zu übertragen, nachdem Sie sie fallen gelassen haben, oder sie sogar zu den bestehenden Dokumenten hinzuzufügen.
Die $out Stufe muss die letzte Stufe in der Pipeline sein.
Zum ersten Mal verwenden wir ein Aggregat mit mehr als einer Stufe. Wir haben jetzt zwei, eine $group und ein $out:
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } },
{ $out : 'aggResults' }
])
Jetzt überprüfen wir den Inhalt des neuen 'aggResults' Sammlung:
db.aggResults.find().pretty()
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
Nachdem wir nun eine mehrstufige Aggregation erstellt haben, können wir mit dem Aufbau einer Pipeline fortfahren.
MongoDB $unwind
Die $unwind Stufe in MongoDB ist üblicherweise in einer Pipeline zu finden, da sie ein Mittel zum Zweck ist.
Sie können nicht direkt mit den Elementen eines Arrays innerhalb eines Dokuments arbeiten, wenn Sie Schritte wie $group. Die $unwind ermöglicht es uns, mit den Werten der Felder innerhalb eines Arrays zu arbeiten.
Wenn die Eingabedokumente ein Array-Feld enthalten, müssen Sie das Dokument manchmal mehrmals ausgeben, einmal für jedes Element des Arrays.
Bei jeder Kopie des Dokuments wird das Array-Feld durch das nachfolgende Element ersetzt.
Im nächsten Beispiel werde ich die Stufe nur auf das Dokument anwenden, dessen Feld name enthält den Wert USAL.
Dies ist das Dokument:
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
Jetzt wenden wir die $unwind über das Array des Schülers und prüfen, ob wir ein Dokument für jedes Element des Arrays erhalten.
Das erste Dokument besteht aus den Feldern im ersten Element des Arrays und den übrigen gemeinsamen Feldern.
Das zweite Dokument besteht aus den Feldern im zweiten Element des Arrays und den übrigen gemeinsamen Feldern usw.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
]).pretty()
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
MongoDB $sort
Sie benötigen die $sort um Ihre Ergebnisse nach dem Wert eines bestimmten Feldes zu sortieren.
Sortieren wir zum Beispiel die Dokumente, die wir als Ergebnis der $unwind Stufe nach der Anzahl der Schüler in absteigender Reihenfolge.
Um einen geringeren Output zu erhalten, werde ich nur das Jahr und die Anzahl der Schüler hochrechnen.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
]).pretty()
Daraus ergibt sich das Ergebnis ...
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
{ "students" : { "year" : 2016, "number" : 21913 } }
{ "students" : { "year" : 2017, "number" : 21715 } }
MongoDB $Limit
Was, wenn Sie nur an den ersten beiden Ergebnissen Ihrer Abfrage interessiert sind? Es ist so einfach wie:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } },
{ $limit : 2 }
]).pretty()
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
Beachten Sie, dass Sie, wenn Sie die Anzahl der sortierten Dokumente begrenzen müssen, die Option $limit Bühne eben nach die $sort.
Jetzt haben wir eine volle Pipeline.
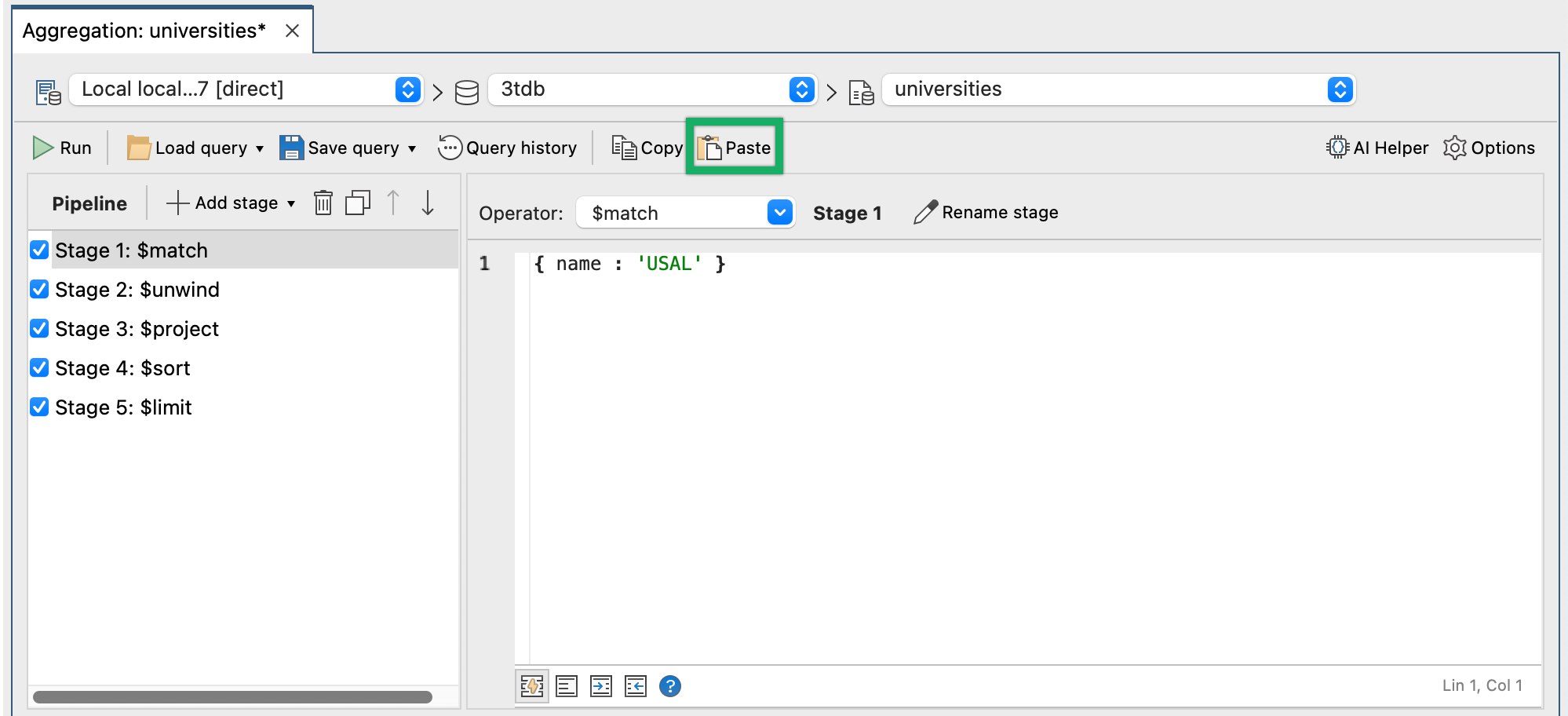
Wir können diese gesamte MongoDB-Aggregationsabfrage und alle ihre Phasen direkt in den Aggregationseditor in Studio 3T einfügen.
Nur der unten abgebildete Teil wird kopiert und eingefügt:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
])
Sie wird eingefügt, indem Sie sie kopieren und auf die Schaltfläche Einfügen klicken (siehe Abbildung).
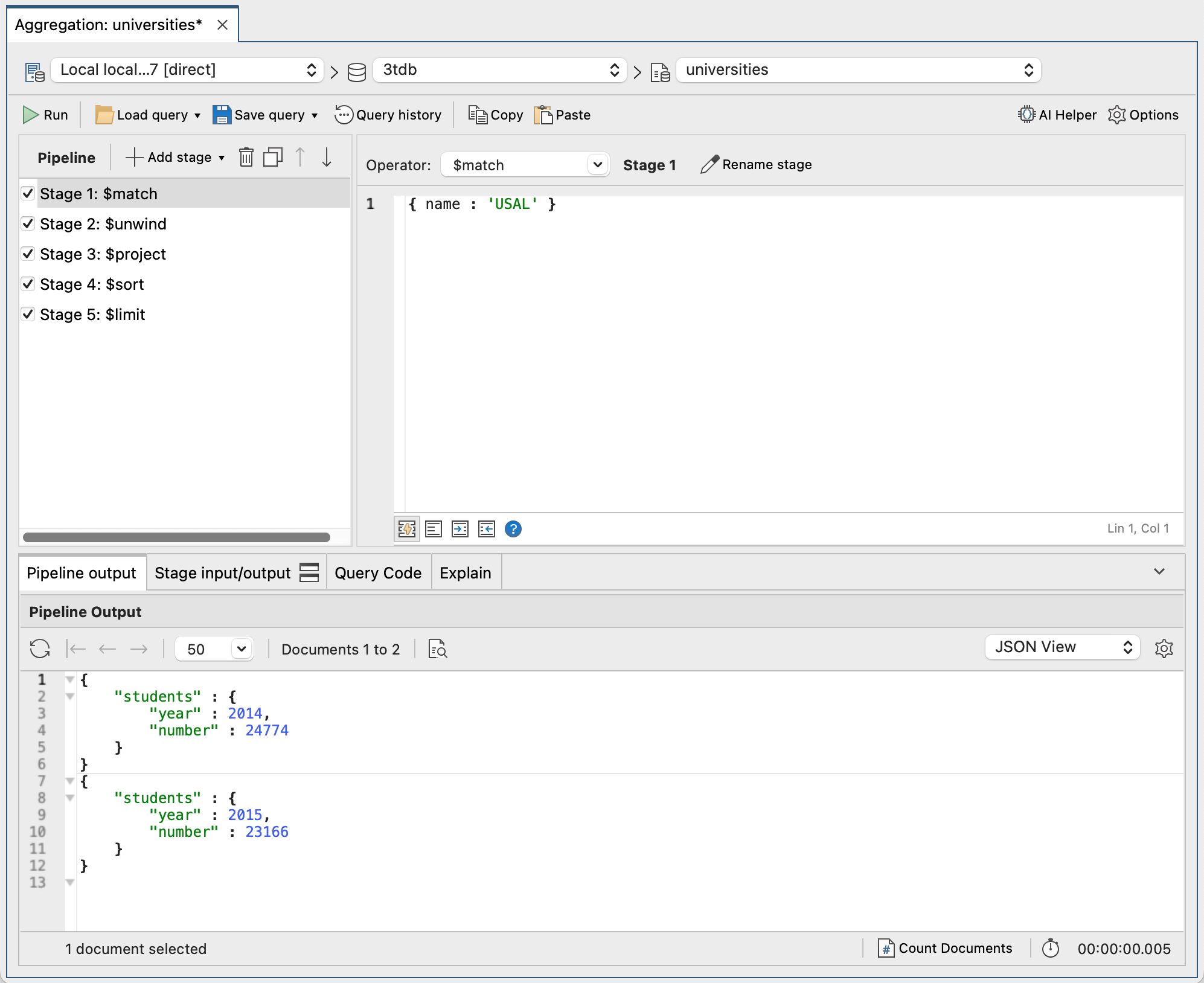
Im nächsten Screenshot sehen Sie die gesamte Pipeline in Studio 3T und ihre Ausgabe.
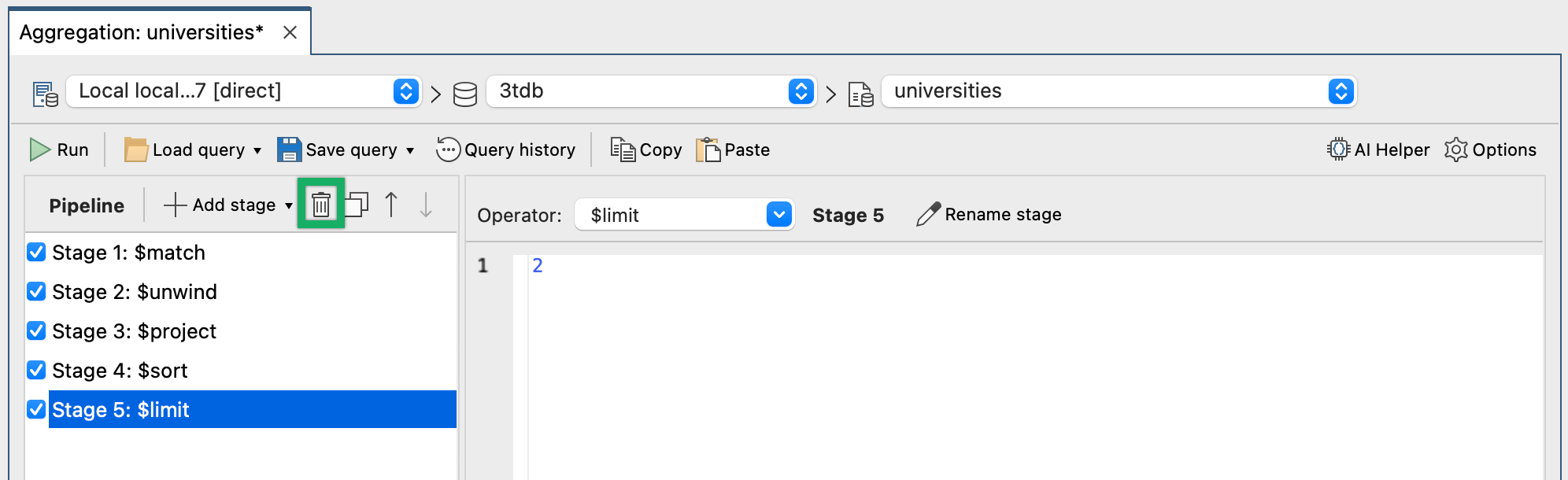
Das Entfernen von Stufen in Studio 3T ist eine einfache Angelegenheit: Wählen Sie die Stufe aus und verwenden Sie die im nächsten Screenshot gezeigte Schaltfläche.
$addFields
Manchmal kann es notwendig sein, Änderungen an Ihrer Ausgabe in Form von neuen Feldern vorzunehmen. Im nächsten Beispiel wollen wir das Gründungsjahr der Universität hinzufügen.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $addFields : { foundation_year : 1218 } }
]).pretty()
Daraus ergibt sich das Ergebnis ...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
],
"foundation_year" : 1218
}
MongoDB $Zahl
Die $count Stufe bietet eine einfache Möglichkeit, die Anzahl der Dokumente zu überprüfen, die in der Ausgabe der vorherigen Stufen der Pipeline enthalten sind.
Schauen wir uns das in Aktion an:
db.universities.aggregate([
{ $unwind : '$students' },
{ $count : 'total_documents' }
]).pretty()
Dies ergibt die Gesamtzahl der Jahre, für die wir die Anzahl der Studenten an der Universität kennen.
{ "total_documents" : 8 }
MongoDB $lookup
Da MongoDB dokumentenbasiert ist, können wir unsere Dokumente so gestalten, wie wir es brauchen. Oftmals ist es jedoch erforderlich, Informationen aus mehr als einer Sammlung zu verwenden.
Die Verwendung des $lookupHier ist eine aggregierte Abfrage, die Felder aus zwei Sammlungen zusammenführt.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $project : { _id : 0, name : 1 } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} }
]).pretty()
Wenn Sie wollen, dass diese Abfrage schnell läuft, müssen Sie index name Feld in der universities Sammlung und die university Feld in der courses Sammlung.
Mit anderen Worten: Vergessen Sie nicht, die Felder zu index , die an der $lookup.
{
"name" : "USAL",
"courses" : [
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbab"),
"university" : "USAL",
"name" : "Computer Science",
"level" : "Excellent"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbac"),
"university" : "USAL",
"name" : "Electronics",
"level" : "Intermediate"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbad"),
"university" : "USAL",
"name" : "Communication",
"level" : "Excellent"
}
]
}
MongoDB $sortByCount
Diese Stufe ist eine Abkürzung, um die Anzahl der verschiedenen Werte in einem Feld zu gruppieren, zu zählen und dann in absteigender Reihenfolge zu sortieren.
Angenommen, Sie möchten die Anzahl der Kurse pro Stufe in absteigender Reihenfolge wissen. Die Abfrage, die Sie erstellen müssten, lautet wie folgt:
db.courses.aggregate([
{ $sortByCount : '$level' }
]).pretty()
Dies ist die Ausgabe:
{ "_id" : "Excellent", "count" : 2 }
{ "_id" : "Intermediate", "count" : 1 }
MongoDB $facet
Bei der Erstellung eines Datenberichts kann es vorkommen, dass Sie dieselbe Vorverarbeitung für eine Reihe von Berichten durchführen müssen und eine Zwischensammlung anlegen und pflegen müssen.
Sie können z. B. eine wöchentliche Zusammenfassung des Handels erstellen, die von allen nachfolgenden Berichten verwendet wird. Sie hätten sich vielleicht gewünscht, mehr als eine Pipeline gleichzeitig über die Ausgabe einer einzigen Aggregationspipeline laufen lassen zu können.
Wir können dies nun innerhalb einer einzigen Pipeline tun, dank der $facet Bühne.
Schauen Sie sich dieses Beispiel an:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} },
{ $facet : {
'countingLevels' :
[
{ $unwind : '$courses' },
{ $sortByCount : '$courses.level' }
],
'yearWithLessStudents' :
[
{ $unwind : '$students' },
{ $project : { _id : 0, students : 1 } },
{ $sort : { 'students.number' : 1 } },
{ $limit : 1 }
]
} }
]).pretty()
Wir haben zwei Berichte aus unserer Datenbank der Universitätskurse erstellt: countingLevels und yearWithLessStudents.
Beide verwendeten den Ausgang der ersten beiden Stufen, die $match und die $lookup.
Bei einer großen Sammlung kann dies viel Verarbeitungszeit einsparen, da Wiederholungen vermieden werden und wir keine temporäre Zwischensammlung mehr schreiben müssen.
{
"countingLevels" : [
{
"_id" : "Excellent",
"count" : 2
},
{
"_id" : "Intermediate",
"count" : 1
}
],
"yearWithLessStudents" : [
{
"students" : {
"year" : 2017,
"number" : 21715
}
}
]
}
Übung
Versuchen Sie nun, die nächste Aufgabe selbst zu lösen.
Wie können wir die Gesamtzahl der Studenten ermitteln, die jemals an einer der Universitäten studiert haben?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } }
]).pretty()
Das Ergebnis:
{ "_id" : "UPSA", "totalalumni" : 22284 }
{ "_id" : "USAL", "totalalumni" : 91568 }
Ja, ich habe zwei Stufen kombiniert. Aber wie können wir eine Abfrage erstellen, die die Ausgabe nach den folgenden Kriterien sortiert totalalumni Feld in absteigender Reihenfolge?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } },
{ $sort : { totalalumni : -1 } }
]).pretty()
Richtig, wir müssen die $sort() Stufe am Ausgang des $group().
Überprüfung unserer Aggregationsabfrage
Wie ich bereits erwähnt habe, ist es sehr einfach und in der Tat unerlässlich, zu überprüfen, ob die Phasen unserer Abfrage so funktionieren, wie wir es brauchen.
Mit Studio 3T stehen Ihnen zwei spezielle Bedienfelder zur Verfügung, mit denen Sie die Eingabe- und Ausgabedokumente für eine bestimmte Phase überprüfen können.
Leistung
Die Aggregationspipeline formt die Abfrage automatisch um, um ihre Leistung zu verbessern.
Wenn Sie beides haben $sort und $match Stufen ist es immer besser, die $match vor dem $sort um die Anzahl der Dokumente zu minimieren, die der $sort Bühne zu bewältigen hat.
Um die Vorteile von Indizes zu nutzen, müssen Sie dies in der ersten Phase Ihrer Pipeline tun. Und hier müssen Sie die $match oder die $sort Stufen.
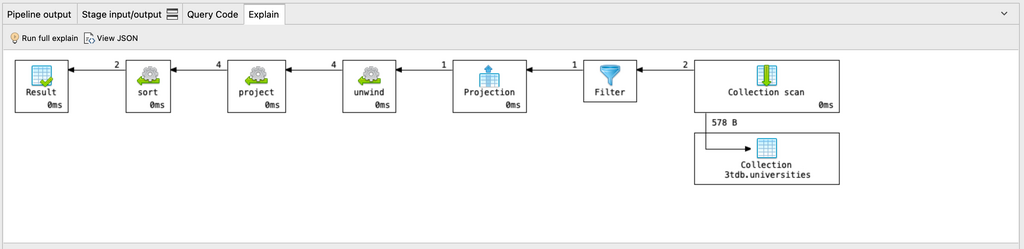
Wir können überprüfen, ob die Abfrage einen index verwendet, indem wir die explain() Methode.
pipeline = [...]
db.<collectionName>.aggregate( pipeline, { explain : true })
Sie können jederzeit die explain() Plan einer beliebigen Aggregationsabfrage als Diagramm oder in JSON, indem Sie auf die Registerkarte Explain klicken.
Schlussfolgerung
Ich habe die MongoDB-Aggregationspipeline vorgestellt und anhand von Beispielen gezeigt, wie man nur einige Stufen verwendet.
Je mehr Sie MongoDB verwenden, desto wichtiger wird die Aggregationspipeline, die Ihnen die Erstellung von Berichten, die Umwandlung und erweiterte Abfragen ermöglicht, die für die Arbeit eines Datenbankentwicklers so wichtig sind.
Je komplexer die Pipeline-Prozesse werden, desto wichtiger wird es, die Ein- und Ausgabe jeder Stufe zu überprüfen und zu debuggen.
Es gibt immer einen Punkt, an dem Sie die wachsende Aggregationspipeline in eine IDE für MongoDB wie Studio 3T mit einem eingebauten Aggregationseditor einfügen müssen, damit Sie jede Phase unabhängig debuggen können.







