
Der neue 인덱스 Manager von Studio 3T stellt sich vor
Möchten Sie wissen, wie Sie am schnellsten herausfinden können, welche Indizes Sie in einer Sammlung haben, oder wie Sie ganz einfach neue Indizes erstellen können? Probieren Sie den neuen und verbesserten 인덱스 Manager aus, mit dem Sie Indizes mit einem Mausklick ein- und ausblenden können, so dass Sie nicht warten müssen, bis Ihre Indizes neu erstellt sind. Sehen Sie auf einen Blick, wie oft Ihre Indizes verwendet werden. Sie können sogar einen Seite-an-Seite-Vergleich von Indizes in verschiedenen Datenbanken durchführen.
Studio 3T kostenlos testenWas sind Indizes in MongoDB und warum brauchen wir sie?
Indizes machen die Abfrage von Daten effizienter. Ohne Indizes führt MongoDB einen Auflistungs-Scan durch, bei dem alle Dokumente in der Auflistung gelesen werden, um festzustellen, ob die Daten den in der Abfrage angegebenen Bedingungen entsprechen. Indizes begrenzen die Anzahl der Dokumente, die MongoDB liest, und mit den richtigen Indizes können Sie die Leistung verbessern. Indizes speichern den Wert eines Feldes oder einer Gruppe von Feldern, geordnet nach dem Wert des Feldes.

Anzeigen des 인덱스 Managers
Um die Indizes einer Sammlung anzuzeigen, suchen Sie die Sammlung in der Verbindungsstruktur und erweitern Sie sie. Sie können den Abschnitt Indizes erweitern, um die Namen von 인덱스 zu sehen:
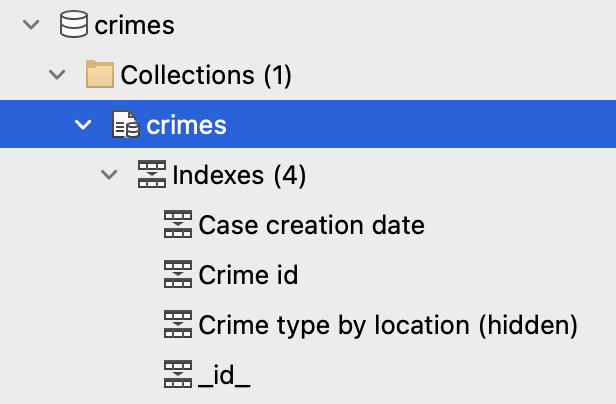
Um den 인덱스 Manager anzuzeigen, doppelklicken Sie auf den Eintrag Indizes am oberen Rand des Abschnitts Indizes.
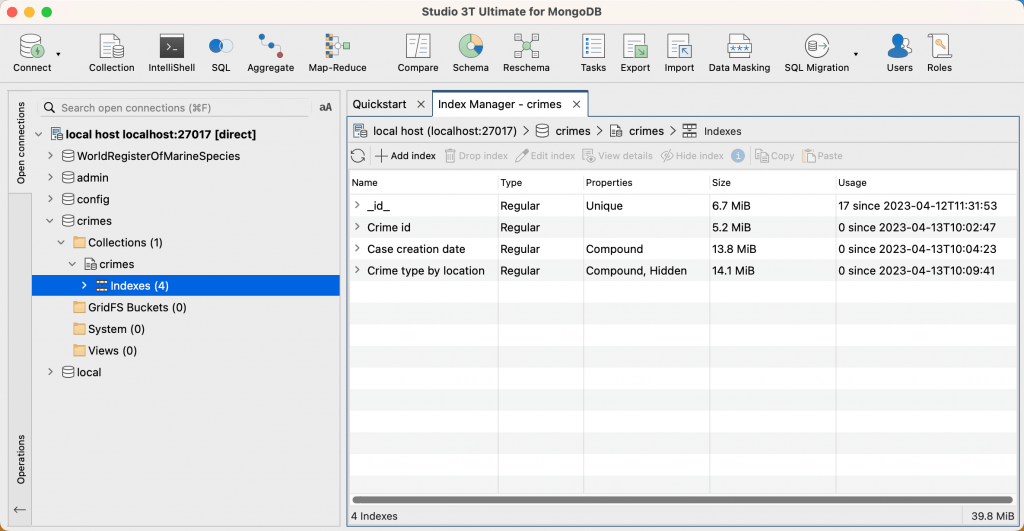
Der 인덱스 Manager zeigt eine Liste aller Indizes für die Sammlung an:
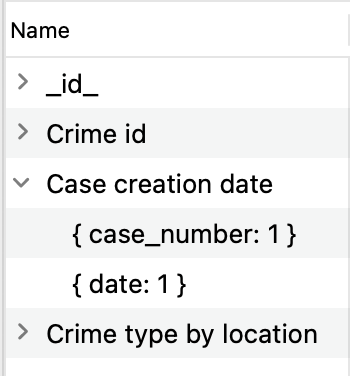
Um die Felder von 인덱싱된 und ihre Sortierreihenfolge anzuzeigen, klicken Sie auf den Pfeil im Feld Name:
인덱스 Größe
Um die beste Leistung zu erzielen, sollten Sie sicherstellen, dass alle Indizes für alle Sammlungen in den RAM-Speicher Ihres MongoDB-Servers passen, um das Lesen von Indizes von der Festplatte zu vermeiden. In einigen Fällen speichern die Indizes nur die jüngsten Werte im RAM. Weitere Informationen finden Sie in der MongoDB-Dokumentation. Das Feld Größe zeigt die Größe der einzelnen 인덱스 in der ausgewählten Sammlung an. Die Gesamtgröße von 인덱스 (Summe aller Indizes) für die Sammlung wird in der unteren rechten Ecke des 인덱스 Managers angezeigt.
인덱스 Verwendung
Die Verwendung zeigt an, wie oft ein 인덱스 seit der Erstellung von 인덱스 oder seit dem letzten Neustart des Servers verwendet wurde.
인덱스 Manager zeigt Nutzungsinformationen nur dann an, wenn Ihr Benutzer über Berechtigungen für den MongoDB-Befehl $indexStats verfügt. Weitere Informationen zu 인덱스 Statistiken finden Sie in der MongoDB-Dokumentation.
Wenn eine 인덱스 nicht verwendet wird, sollten Sie sie löschen, um den mit der Pflege der 인덱스 verbundenen Overhead zu vermeiden, wenn Feldwerte aktualisiert werden, und um Speicherplatz zu sparen.
Hinzufügen einer 인덱스
Klicken Sie in der Verbindungsstruktur mit der rechten Maustaste auf eine Sammlung, und wählen Sie dann Hinzufügen 인덱스.
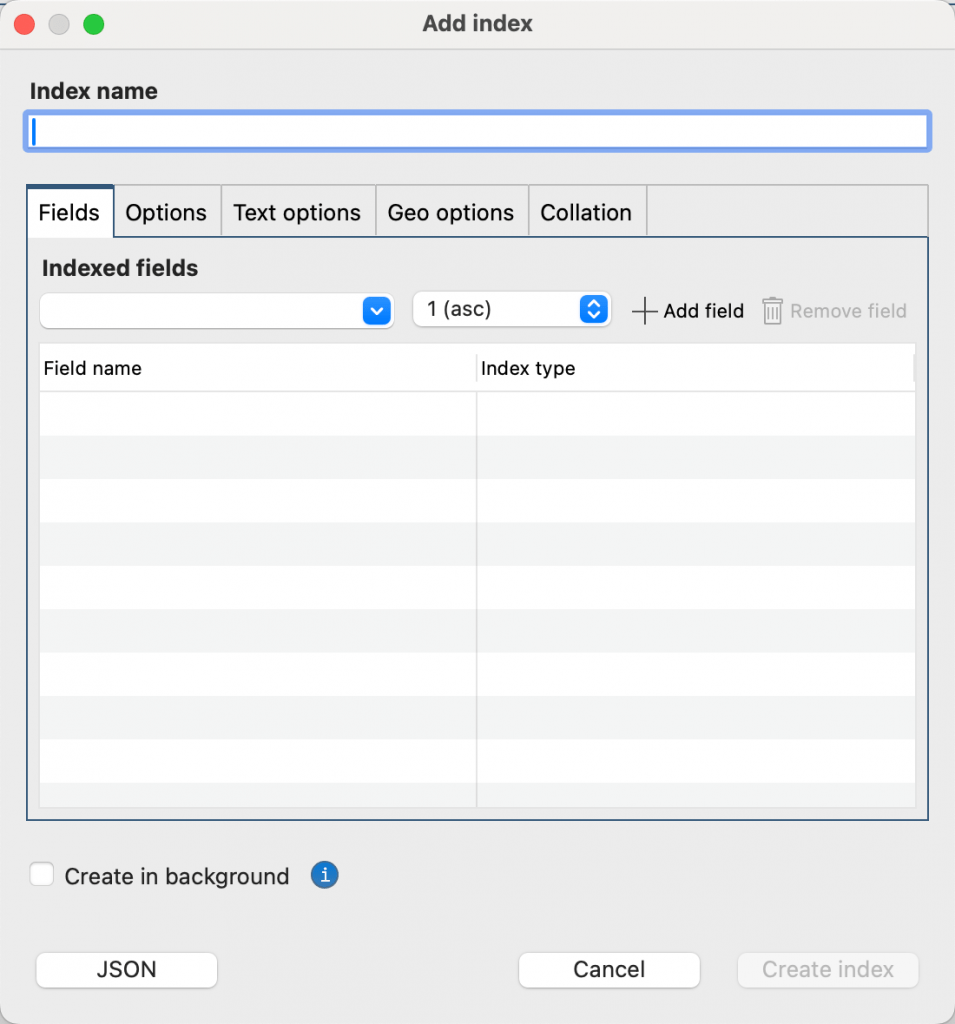
Geben Sie im Dialogfeld 인덱스 hinzufügen den Namen Ihrer 인덱스 in das Feld 인덱스 name ein. Wenn Sie das Feld 인덱스 name leer lassen, erstellt Studio 3T einen Standardnamen 인덱스 für Sie, der auf den Namen der von Ihnen ausgewählten Felder und dem Typ 인덱스 basiert.
Fügen Sie die erforderlichen Felder zu Ihrer 인덱스 hinzu. Wählen Sie dazu das Feld aus der Liste 인덱싱된 fields aus und wählen Sie dann die Sortierreihenfolge (1 asc oder -1 desc) oder den Typ von 인덱스. Weitere Informationen über 인덱스 Typen und Eigenschaften finden Sie unter MongoDB 인덱스 types und MongoDB 인덱스 properties. Klicken Sie auf Feld hinzufügen.
Standardmäßig erstellt MongoDB Indizes im Vordergrund, wodurch alle Lese- und Schreibvorgänge in der Datenbank verhindert werden, während die 인덱스 erstellt wird. Dies führt zu kompakten 인덱스 Größen und benötigt weniger Zeit für die Erstellung. Um Lese- und Schreibvorgänge während der Erstellung von 인덱스 zu ermöglichen, aktivieren Sie das Kontrollkästchen Im Hintergrund erstellen. Das Ergebnis ist eine weniger kompakte 인덱스 und die Erstellung dauert länger.
Im Laufe der Zeit wird die Größe jedoch konvergieren, als ob Sie die 인덱스 im Vordergrund erstellt hätten. Weitere Informationen zum Erstellen von Indizes finden Sie in der MongoDB-Dokumentation.
Wenn Sie das Hinzufügen von Feldern zu Ihrer 인덱스 abgeschlossen haben, klicken Sie auf Erstellen 인덱스.
MongoDB 인덱스 Typen
Einzelfeldindizes
Wenn Sie 인덱싱된 Felder angeben, wenden Sie eine Sortierreihenfolge für jedes Feld an. In einem Einzelfeld 인덱스 ist die Sortierreihenfolge nicht wichtig, da MongoDB die Daten in beide Richtungen durchlaufen kann.
Zusammengesetzte Indizes
Zusammengesetzte Indizes geben mehrere 인덱싱된 Felder an. Die Reihenfolge, in der Sie die Felder angeben, ist wichtig. MongoDB empfiehlt, die ESR-Regel (Gleichheit, Suche, Bereich) zu befolgen:
- Fügen Sie zunächst die Felder hinzu, für die Gleichheitsabfragen durchgeführt werden, d. h. exakte Übereinstimmungen mit einem einzigen Wert
- Fügen Sie als nächstes Felder hinzu, die die Sortierreihenfolge der Abfrage wiedergeben
- schließlich Felder für Bereichsfilter hinzufügen
Indizes mit mehreren Schlüsseln
Multikey-Indizes werden für Felder verwendet, die Arrays enthalten. Sie müssen nur das Feld angeben, das das Array enthält, und MongoDB erstellt automatisch einen 인덱스 Schlüssel für jedes Element im Array.
Text-Indizes
Textindizes unterstützen die Suche in Feldern, die Strings oder ein Array von String-Elementen sind. Sie können einen Text 인덱스 pro Sammlung erstellen. Ein Text 인덱스 kann mehrere Felder enthalten.
인덱스 Version: Es gibt drei Versionen, wobei 3 die Standardversion ist.
Standardsprache: Die Standardsprache ist Englisch. Die von Ihnen gewählte Sprache bestimmt die Regeln, nach denen die Wortwurzeln analysiert werden (Suffixstämme), und definiert die Stoppwörter, die herausgefiltert werden. Im Englischen gehören zu den Suffixstämmen beispielsweise -ing und -ed, und zu den Stoppwörtern gehören the und a.
Sprache überschreiben: Geben Sie einen anderen Feldnamen an, um das Sprachfeld zu überschreiben.
Feldgewichtungen: Für jedes 인덱싱된 Feld multipliziert MongoDB die Anzahl der Übereinstimmungen mit der Gewichtung und summiert die Ergebnisse. MongoDB verwendet diese Summe, um eine Punktzahl für das Dokument zu berechnen. Wählen Sie ein Feld aus der Liste aus, geben Sie seine Gewichtung im Feld an und klicken Sie auf Feld hinzufügen. Die Standardfeldgewichtung ist 1.
Platzhalter-Indizes
Wildcard-Indizes unterstützen Abfragen, bei denen die Feldnamen unbekannt sind, zum Beispiel in beliebigen benutzerdefinierten Datenstrukturen, deren Schema dynamisch ist. Ein Nicht-Wildcard-Index 인덱스 unterstützt nur Abfragen auf die Werte von benutzerdefinierten Datenstrukturen. Wildcard-Indizes filtern alle übereinstimmenden Felder.
Um einen Platzhalter 인덱스 für alle Felder für jedes Dokument in einer Sammlung hinzuzufügen, wählen Sie $** (alle Felder) in der Liste 인덱싱된 fields:

Geografische Indizes
2d-Indizes
2d-Indizes werden für Daten verwendet, die als Punkte auf einer zweidimensionalen Ebene gespeichert sind. 2D-Indizes sind für Legacy-Koordinatenpaare in MongoDB 2.2 und früher vorgesehen. Untere Grenze und Obere Grenze ermöglicht die Angabe eines Ortsbereichs anstelle der Standardeinstellungen von -180 (einschließlich) für Längengrad und 180 (nicht einschließlich) für Breitengrad. Mit der Option Bitpräzision können Sie die Größe der Ortswerte in Bits festlegen, bis zu einer Genauigkeit von 32 Bits. Der Standardwert beträgt 26 Bits, was bei Verwendung des Standard-Positionsbereichs einer Genauigkeit von etwa 60 Zentimetern entspricht.
2d-Kugel
2D-Kugelindizes unterstützen Abfragen, die Geometrien auf einer erdähnlichen Kugel berechnen.
Geo-Heuhaufen
geoHaystack-Indizes verbessern die Leistung bei Abfragen, die eine flache Geometrie verwenden. geoHaystack-Indizes wurden in MongoDB 4.4 veraltet und in MongoDB 5.0 entfernt. geoHaystack-Indizes erstellen Buckets mit Dokumenten aus demselben geografischen Gebiet. Sie müssen die Bucket-Größe angeben. Bei einer Bucket-Größe von 5 wird beispielsweise eine 인덱스 erstellt, die Ortswerte gruppiert, die innerhalb von 5 Einheiten des angegebenen Längen- und Breitengrads liegen. Die Bereichsgröße bestimmt auch die Granularität von 인덱스.
MongoDB 인덱스 Eigenschaften
Einzigartige Indizes
Eindeutige Indizes verhindern, dass Dokumente eingefügt werden, wenn es bereits ein Dokument gibt, das diesen Wert für das Feld 인덱싱된 enthält.
Spärliche Indizes
Sparse-Indizes überspringen Dokumente, die das Feld 인덱싱된 nicht enthalten, es sei denn, der Wert des Feldes ist null. Sparse-Indizes enthalten nicht alle Dokumente in der Sammlung.
Versteckte Indizes
Versteckte Indizes werden im Abfrageplan nicht angezeigt. Mit dieser Option wird der 인덱스 bei seiner Erstellung als versteckt festgelegt. Sie können den 인덱스 im 인덱스 Manager als nicht ausgeblendet festlegen. Weitere Informationen finden Sie unter Ausblenden eines 인덱스.
TTL-Indizes
TTL-Indizes sind Einzelfeldindizes, die Dokumente auslaufen lassen und MongoDB anweisen, Dokumente nach einer bestimmten Zeit aus der Datenbank zu löschen. Das Feld 인덱싱된 muss ein Datumstyp sein. Geben Sie die Verfallszeit in Sekunden ein.
Teilweise Indizes
Teilindizes enthalten nur die Dokumente, die einem Filterausdruck entsprechen.
Indizes ohne Berücksichtigung der Groß-/Kleinschreibung
Indizes, die die Groß-/Kleinschreibung nicht berücksichtigen, unterstützen Abfragen, die die Groß-/Kleinschreibung beim Vergleich von Zeichenketten ignorieren. Die Verwendung eines case-insensitive 인덱스 hat keinen Einfluss auf die Ergebnisse einer Abfrage. Um den 인덱스 zu verwenden, müssen Abfragen die gleiche Kollation angeben.
Sie definieren Indizes ohne Berücksichtigung der Groß- und Kleinschreibung mithilfe der Kollationierung. Mit der Kollationierung können Sie sprachspezifische Regeln für den Zeichenfolgenvergleich festlegen, z. B. Regeln für Akzente. Sie können die Sortierung auf der Ebene der Sammlung oder 인덱스 festlegen. Wenn eine Sammlung eine definierte Sortierung hat, erben alle Indizes diese Sammlung, es sei denn, Sie geben eine eigene Sortierung an.
Um eine Sortierung auf der Ebene 인덱스 anzugeben, markieren Sie das Feld Benutzerdefinierte Sortierung verwenden. Die Einstellung Gebietsschema ist obligatorisch und bestimmt die Sprachregeln. Setzen Sie Stärke auf 1 oder 2, um die Groß- und Kleinschreibung zu ignorieren. Alle anderen Einstellungen sind optional und ihre Standardwerte hängen von dem von Ihnen angegebenen Gebietsschema ab. Weitere Informationen zu Sortiereinstellungen finden Sie in der MongoDB-Dokumentation.
Fallenlassen eines 인덱스
Ungenutzte Indizes wirken sich auf die Leistung einer Datenbank aus, da MongoDB die 인덱스 immer dann pflegen muss, wenn Dokumente eingefügt oder aktualisiert werden. Die Spalte "Verwendung" im 인덱스 Manager zeigt Ihnen, wie oft ein 인덱스 verwendet wurde.
Bevor Sie ein 인덱스 ausblenden, sollten Sie testen, wie gut 인덱스 die Abfragen unterstützt, indem Sie es ausblenden. Wenn Sie einen Leistungsabfall feststellen, heben Sie die Ausblendung der 인덱스 auf, damit die Abfragen sie wieder nutzen können.
Sie können die standardmäßige _id 인덱스 , die MongoDB erstellt, wenn Sie eine neue Sammlung hinzufügen, nicht löschen.
Um eine 인덱스 zu löschen, führen Sie einen der folgenden Schritte aus:
- klicken Sie im Verbindungsbaum mit der rechten Maustaste auf 인덱스 und wählen Sie Drop 인덱스.
- Wählen Sie in der Verbindungsstruktur 인덱스 und drücken Sie Strg + Rücktaste (Windows) oder fn + Löschen (Mac).
- Wählen Sie 인덱스 im 인덱스 Manager und klicken Sie auf die Schaltfläche Drop 인덱스.
- Klicken Sie mit der rechten Maustaste auf das 인덱스 im 인덱스 Manager und wählen Sie Drop 인덱스.
Um mehr als einen 인덱스 zu löschen, markieren Sie die gewünschten Indizes im Verbindungsbaum, klicken Sie mit der rechten Maustaste und wählen Sie Indizes löschen.
Bearbeitung eines 인덱스
Die Bearbeitung eines 인덱스 ermöglicht es Ihnen, ein bestehendes 인덱스 zu modifizieren, z. B. um die 인덱싱된 Felder zu ändern. Der 인덱스 Manager löscht die 인덱스 für Sie und erstellt die 인덱스 mit den von Ihnen angegebenen Änderungen neu.
Um eine 인덱스 zu bearbeiten, führen Sie einen der folgenden Schritte aus, um das Dialogfeld Bearbeiten 인덱스 zu öffnen:
- klicken Sie im Verbindungsbaum mit der rechten Maustaste auf 인덱스 und wählen Sie Bearbeiten 인덱스.
- im Verbindungsbaum, wählen Sie die 인덱스 und drücken Sie die Eingabetaste.
- Wählen Sie im 인덱스 Manager die Seite 인덱스 aus und klicken Sie auf die Schaltfläche 인덱스 bearbeiten.
- Klicken Sie mit der rechten Maustaste auf 인덱스 im 인덱스 Manager und wählen Sie 인덱스 bearbeiten.
Nehmen Sie die gewünschten Änderungen vor und klicken Sie auf " Verwerfen und neu erstellen" 인덱스.
Wenn die einzige Änderung, die Sie an 인덱스 vornehmen, darin besteht, die 인덱스 auszublenden oder wieder einzublenden, muss der 인덱스 Manager die 인덱스 nicht ablegen und neu erstellen, sodass Sie auf Änderungen übernehmen klicken, um diese Änderung vorzunehmen.
Details auf 인덱스 ansehen
Sie können eine schreibgeschützte Version der Details von 인덱스 anzeigen, damit Sie nicht versehentlich irgendwelche Einstellungen ändern.
Führen Sie einen der folgenden Schritte aus, um die Details zu einer 인덱스 anzuzeigen:
- Wählen Sie im 인덱스 Manager die Seite 인덱스 und klicken Sie auf die Schaltfläche Details anzeigen.
- Klicken Sie im 인덱스 Manager mit der rechten Maustaste auf die 인덱스 und wählen Sie Details anzeigen.
Verstecken eines 인덱스
Sie können eine 인덱스 aus dem Abfrageplan ausblenden. Das Ausblenden von 인덱스 ermöglicht es Ihnen, die Auswirkung des Weglassens von 인덱스 zu bewerten. Das Ausblenden von 인덱스 erspart es Ihnen, 인덱스 wegzulassen und dann neu zu erstellen. Sie können die Leistung von Abfragen mit und ohne 인덱스 vergleichen, indem Sie die Abfrage mit 인덱스 ausführen, dann das 인덱스 ausblenden und die Abfrage erneut ausführen.
Wenn Sie einen 인덱스 ausblenden, gelten seine Funktionen weiterhin, z. B. wenden eindeutige Indizes weiterhin eindeutige Beschränkungen auf Dokumente an und TTL-Indizes lassen Dokumente weiterhin ablaufen. Der ausgeblendete 인덱스 verbraucht weiterhin Festplattenplatz und Arbeitsspeicher. Wenn er also die Leistung nicht verbessert, sollten Sie erwägen, den 인덱스 zu entfernen.
Versteckte Indizes werden ab MongoDB 4.4 oder höher unterstützt. Stellen Sie sicher, dass featureCompatibilityVersion auf 4.4 oder höher gesetzt ist.
Um eine 인덱스 auszublenden, führen Sie einen der folgenden Schritte aus:
- Klicken Sie im Verbindungsbaum mit der rechten Maustaste auf 인덱스 und wählen Sie 인덱스 ausblenden. Der 인덱스 wird als ausgeblendet markiert.
- Wählen Sie 인덱스 im 인덱스 Manager und klicken Sie auf die Schaltfläche 인덱스 ausblenden. Die Spalte Eigenschaften im 인덱스 Manager zeigt, dass 인덱스 ausgeblendet ist.
- Klicken Sie mit der rechten Maustaste auf 인덱스 im 인덱스 Manager und wählen Sie 인덱스 ausblenden.
Führen Sie einen der folgenden Schritte aus, um eine 인덱스 einzublenden:
- klicken Sie im Verbindungsbaum mit der rechten Maustaste auf 인덱스 und wählen Sie 인덱스 einblenden.
- Wählen Sie 인덱스 im 인덱스 Manager und klicken Sie auf die Schaltfläche 인덱스 ausblenden.
- Klicken Sie mit der rechten Maustaste auf 인덱스 im 인덱스 Manager und wählen Sie 인덱스 einblenden.
Kopieren einer 인덱스
Sie können eine 인덱스 aus einer Datenbank kopieren und ihre Eigenschaften in eine andere Datenbank einfügen.
Um eine 인덱스 zu kopieren, führen Sie einen der folgenden Schritte aus:
- klicken Sie im Verbindungsbaum mit der rechten Maustaste auf 인덱스 und wählen Sie Kopieren 인덱스.
- Wählen Sie im 인덱스 Manager die Seite 인덱스 und klicken Sie auf die Schaltfläche Kopieren.
- Klicken Sie mit der rechten Maustaste auf 인덱스 im 인덱스 Manager und wählen Sie 인덱스 kopieren.
Um die 인덱스 einzufügen, klicken Sie im Verbindungsbaum mit der rechten Maustaste auf die Zielsammlung und wählen Sie Einfügen 인덱스.
Um mehr als einen 인덱스 zu kopieren, markieren Sie die gewünschten Indizes im Verbindungsbaum, klicken mit der rechten Maustaste und wählen Indizes kopieren. Klicken Sie im Verbindungsbaum mit der rechten Maustaste auf die Zielsammlung, und wählen Sie Indizes einfügen.
MongoDB-Indizes verwenden (Tutorial)
Obwohl in einer MongoDB-Datenbank eine große Menge an Informationen gespeichert werden kann, benötigen Sie eine effektive Indizierungsstrategie, um die benötigten Informationen schnell und effizient abzurufen.
In diesem Tutorial werde ich einige der Grundlagen der Verwendung von MongoDB-Indizes mit einfachen Abfragen durchgehen und dabei Aktualisierungen und Einfügungen außer Acht lassen.
Dies soll ein praktischer Ansatz sein, der nur so viel Theorie enthält, dass Sie die Beispiele ausprobieren können. Die Absicht ist es, dem Leser die Möglichkeit zu geben, nur die Shell zu benautzen, obwohl alles viel einfacher in der MongoDB-GUI ist, die ich benutzt habe, Studio 3T.
Eine Einführung in MongoDB-Indizes
Wenn MongoDB Ihre Daten in eine Sammlung importiert, erstellt es einen Primärschlüssel, der durch einen Index erzwungen wird.
Aber es kann nicht erraten, welche anderen Indizes Sie benötigen, weil es keine Möglichkeit gibt, die Art von Suchvorgängen, Sortierungen und Aggregationen vorherzusagen, die Sie mit diesen Daten durchführen wollen.
Er liefert lediglich einen eindeutigen Bezeichner für jedes Dokument in Ihrer Sammlung, der in allen weiteren Indizes beibehalten wird. MongoDB erlaubt keine Heaps. - unindizierte Daten, die lediglich durch Vorwärts- und Rückwärtszeiger miteinander verbunden sind.
Mit MongoDB können Sie zusätzliche Indizes erstellen, die dem Design der Indizes in relationalen Datenbanken ähneln und einen gewissen Verwaltungsaufwand erfordern.
Wie bei anderen Datenbanksystemen gibt es spezielle Indizes für spärliche Daten, für die Suche im Text oder für die Auswahl räumlicher Informationen.
Für eine Abfrage oder Aktualisierung wird in der Regel nur eine einzige 인덱스 verwendet, sofern eine geeignete verfügbar ist. Eine 인덱스 kann in der Regel die Leistung jeder Datenoperation verbessern, aber das ist nicht immer der Fall.
Sie könnten versucht sein, den "Scattergun"-Ansatz zu wählen, d. h. viele verschiedene Indizes zu erstellen, um sicherzustellen, dass es einen gibt, der wahrscheinlich geeignet ist. Der Nachteil ist jedoch, dass jeder 인덱스 Ressourcen verbraucht und vom System gepflegt werden muss, sobald sich die Daten ändern.
Wenn Sie es mit den Indizes übertreiben, werden sie die Speicherseiten dominieren und zu übermäßiger Festplatten-E/A führen. Am besten ist eine kleine Anzahl hocheffektiver Indizes.
Eine kleine Sammlung wird wahrscheinlich in den Cache passen, so dass der Aufwand für die Bereitstellung von Indizes und die Abstimmung von Abfragen einen großen Einfluss auf die Gesamtleistung zu haben scheint.
Mit zunehmender Größe der Dokumente und steigender Anzahl von Dokumenten kommt diese Arbeit jedoch zum Tragen. Ihre Datenbank wird sich gut skalieren lassen.
Erstellen einer Testdatenbank
Zur Veranschaulichung einiger Indexgrundlagen werden wir 70.000 Kunden aus einer JSON-Datei in MongoDB laden. Jedes Dokument enthält den Namen, die Adressen, die Telefonnummern, die Kreditkartendaten und die "Aktennotizen" der Kunden. Diese wurden aus Zufallszahlen generiert.
Dieses Laden kann entweder über Mongoimport oder über ein Tool wie Studio 3T erfolgen.
Angeben der Sortierung in MongoDB-Sammlungen
Bevor Sie eine Sammlung erstellen, müssen Sie die Sortierung berücksichtigen, d. h. die Art und Weise, wie die Suche und Sortierung durchgeführt wird (die Sortierung wird vor MongoDB 3.4 nicht unterstützt).
Möchten Sie, dass bei der Sortierung von Zeichenketten die Kleinbuchstaben nach den Großbuchstaben sortiert werden, oder soll die Groß-/Kleinschreibung ignoriert werden? Wird ein durch eine Zeichenfolge dargestellter Wert je nach den in Großbuchstaben dargestellten Zeichen als unterschiedlich betrachtet? Wie gehen Sie mit akzentuierten Zeichen um? Standardmäßig haben Sammlungen eine binäre Sortierung, was in der Welt des Handels wahrscheinlich nicht erforderlich ist.
Um herauszufinden, welche Sortierung, wenn überhaupt, für Ihre Sammlung verwendet wird, können Sie diesen Befehl verwenden (hier für unsere Sammlung "Kunden").
db.getCollectionInfos({name: 'Customers'})

Dies zeigt, dass ich die Sammlung Customers mit der Sortierreihenfolge "en" eingestellt habe.
Wenn ich in der Shell-Ausgabe nach unten scrolle, sehe ich, dass alle MongoDB-Indizes die gleiche Sortierung haben, was gut ist.
Leider können Sie die Sortierung einer bestehenden Sammlung nicht ändern. Sie müssen die Sammlung erstellen, bevor Sie die Daten hinzufügen.
So erstellen Sie eine Sammlung "Kunden" mit einer englischen Sortierung. In Studio 3T können Sie die Sortierung sowohl über die Benutzeroberfläche als auch über die integrierte IntelliShell definieren.
Hier sehen Sie die Registerkarte "Sortierung" des Fensters "Neue Sortierung hinzufügen", das Sie erreichen, indem Sie mit der rechten Maustaste auf den Namen der Datenbank klicken und dann auf "Neue Sortierung hinzufügen ...".

Sie können dasselbe in IntelliShell mit dem Befehl erreichen:
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

Alternativ können Sie jeder Suche, jeder Sortierung und jedem Zeichenfolgenvergleich Sortierinformationen hinzufügen.
Meiner Erfahrung nach ist es übersichtlicher, sicherer und einfacher zu ändern, wenn Sie dies auf der Ebene der Sammlung tun. Wenn die Sortierreihenfolge einer 인덱스 nicht mit der Sortierreihenfolge der von Ihnen durchgeführten Suche oder Sortierung übereinstimmt, kann MongoDB die 인덱스 nicht verwenden.
Wenn Sie ein Dokument importieren, ist es am besten, wenn die natürliche Reihenfolge nach der von Ihnen festgelegten Sortierung in der Reihenfolge des am häufigsten vorkommenden 인덱싱된 Attributs vorsortiert ist. Dadurch wird der Primärschlüssel "geclustert", so dass 인덱스 weniger Seitenblöcke für jede 인덱스 Schlüsselsuche besuchen muss und das System eine viel höhere Trefferquote erhält.
Das Schema verstehen
Sobald wir die Musterdaten geladen haben, können wir ihr Schema einfach durch Untersuchung des ersten Dokuments anzeigen
db.Customers.find({}).limit(1);
In Studio 3T können Sie dies auf der Registerkarte Sammlung sehen:

MongoDB-Indizes für einfache Abfragen
Beschleunigung einer sehr einfachen Abfrage
Wir werden nun eine einfache Abfrage in unserer neu erstellten Datenbank ausführen, um alle Kunden mit dem Nachnamen "Johnston" zu finden.
Wir möchten eine Projektion über "Vorname" und "Nachname", sortiert nach "Nachname", durchführen oder auswählen. Die Zeile "_id" : NumberInt(0), bedeutet nur, dass die ID nicht zurückgegeben werden soll.
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

Wenn wir sicher sind, dass die Abfrage das richtige Ergebnis liefert, können wir sie so ändern, dass die Ausführungsstatistiken zurückgegeben werden.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
Laut der Ausführungsstatistik von "Explain" dauert dies auf meinem Rechner 59 Ms (ExecutionTimeMillis). Dabei handelt es sich um einen COLLSCAN, d. h. es ist kein 인덱스 verfügbar, so dass Mongo die gesamte Sammlung durchsuchen muss.
Bei einer relativ kleinen Sammlung ist das nicht unbedingt schlecht, aber wenn die Sammlung größer wird und mehr Benutzer auf die Daten zugreifen, passt sie wahrscheinlich nicht mehr in den ausgelagerten Speicher, und die Festplattenaktivität nimmt zu.
Die Datenbank lässt sich nicht gut skalieren, wenn sie gezwungen ist, einen großen Prozentsatz von COLLSCANs durchzuführen. Es ist eine gute Idee, die von häufig ausgeführten Abfragen verwendeten Ressourcen zu minimieren.
Es liegt auf der Hand, dass eine 인덱스 , wenn sie die benötigte Zeit verkürzen soll, wahrscheinlich Name.Nachname beinhaltet.
Fangen wir damit an und machen daraus eine aufsteigende 인덱스 , da wir die Sortierung aufsteigend haben wollen:
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
Auf meinem Rechner dauert es jetzt 4 Ms (ExecutionTimeMillis). Dazu gehört ein IXSCAN (ein 인덱스 Scan, um Schlüssel zu erhalten), gefolgt von einem FETCH (zum Abrufen der Dokumente).
Wir können dies verbessern, da die Abfrage den Vornamen ermitteln muss.
Wenn wir Name.Vorname in die 인덱스 einfügen, kann die Datenbank-Engine den Wert in der 인덱스 verwenden, anstatt den zusätzlichen Schritt zu machen, ihn aus der Datenbank zu holen.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
Auf diese Weise dauert die Abfrage weniger als 2 Ms.
Da 인덱스 die Abfrage "abdeckt", konnte MongoDB die Abfragebedingungen erfüllen und die Ergebnisse nur mit den 인덱스 -Schlüsseln zurückgeben, ohne dass Dokumente aus der Sammlung untersucht werden mussten, um die Ergebnisse zurückzugeben. (Wenn Sie im Ausführungsplan eine IXSCAN-Stufe sehen, die kein Kind einer FETCH-Stufe ist, dann hat die 인덱스 die Abfrage "abgedeckt").
Sie werden feststellen, dass unsere Sortierung die offensichtliche aufsteigende Sortierung, A-Z, war. Wir haben das mit einer 1 als Wert für die Sortierung angegeben. Was ist, wenn das Endergebnis von Z-A (absteigend) sein soll und mit -1 angegeben wird? Bei dieser kurzen Ergebnismenge ist kein Unterschied feststellbar.
Das scheint ein Fortschritt zu sein. Aber was ist, wenn man den Index falsch gewählt hat? Das kann zu Problemen führen.
Wenn Sie die Reihenfolge der beiden Felder im Index so ändern, dass Name.Vorname vor Name.Nachname steht, steigt die Ausführungszeit auf 140 Ms, ein enormer Anstieg.
Dies erscheint bizarr, da 인덱스 die Ausführung tatsächlich verlangsamt hat, so dass sie mehr als doppelt so lange dauert wie mit der Standard-Primärstrategie 인덱스 (zwischen 40 und 60 Ms). MongoDB prüft zwar die möglichen Ausführungsstrategien auf eine gute, aber wenn Sie keine geeignete 인덱스 zur Verfügung stellen, ist es schwierig, die richtige auszuwählen.
Was haben wir also bisher gelernt?
Es scheint, dass einfache Abfragen am meisten von Indizes profitieren, die an den Auswahlkriterien beteiligt sind, und zwar mit der gleichen Sortierung.
In unserem vorherigen Beispiel haben wir eine allgemeine Wahrheit über MongoDB-Indizes veranschaulicht: Wenn das erste Feld von 인덱스 nicht Teil der Auswahlkriterien ist, ist es nicht sinnvoll, die Abfrage auszuführen.
Beschleunigung von unSARGable-Abfragen
Was passiert, wenn wir zwei Kriterien haben, von denen eines eine String-Übereinstimmung innerhalb des Wertes beinhaltet?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
Wir wollen einen Kunden namens Wiggins finden, der in Rutland lebt. Es dauert 50 Ms ohne unterstützenden Index.
Wenn wir den Namen von der Suche ausschließen, verdoppelt sich die Ausführungszeit sogar.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
Wenn wir nun einen zusammengesetzten Index einführen, der mit dem Namen beginnt und dann die Adresse hinzufügt, stellen wir fest, dass die Abfrage so schnell war, dass 0 Ms aufgezeichnet wurden.
Das liegt daran, dass der Index es MongoDB ermöglicht, nur die 52 Wiggins in der Datenbank zu finden und die Suche nur über diese Adressen durchzuführen. Das scheint gut genug zu sein!
Was passiert, wenn wir die beiden Kriterien umdrehen? Überraschenderweise meldet das Kriterium "explain" 72 Ms.
Beides sind gültige Kriterien, die in der Abfrage angegeben werden. Wenn jedoch das falsche Kriterium verwendet wird, ist die Abfrage mit einer Zeitspanne von 20 Ms mehr als nutzlos.
Der Grund für diesen Unterschied ist offensichtlich. Die Adresse 인덱스 kann zwar ein Durchsuchen aller Daten verhindern, aber nicht bei der Suche helfen, da sie einen regulären Ausdruck enthält.
Hier gibt es zwei allgemeine Grundsätze.
Eine komplexe Suche sollte die Auswahlkandidaten so weit wie möglich mit dem ersten Element in der Liste der Indizes reduzieren. Der Begriff "Kardinalität" wird für diese Art von Selektivität verwendet. Ein Feld mit geringer Kardinalität, wie z. B. das Geschlecht, ist weit weniger selektiv als der Nachname.
In unserem Beispiel ist der Nachname selektiv genug, um die offensichtliche Wahl für das erste Feld zu sein, das in einem Index aufgeführt ist, aber nicht viele Abfragen sind so offensichtlich.
Die Suche, die vom ersten Feld in einem verwendbaren 인덱스 angeboten wird, sollte SARGable sein. Dies ist eine Abkürzung für die Aussage, dass das Feld 인덱스 Search ARGumentablesein muss.
Im Fall der Suche nach dem Wort "rutland" stand der Suchbegriff nicht in direktem Zusammenhang mit dem Inhalt des Index und der Sortierung des Indexes.
Wir waren nur deshalb in der Lage, sie effektiv zu nutzen, weil wir MongoDB mit Hilfe des 인덱스 -Auftrags davon überzeugen konnten, dass es die beste Strategie ist, die zwanzig wahrscheinlichsten "Wiggins" in der Datenbank zu finden und dann die Kopie der vollständigen Adresse in 인덱스 zu verwenden und nicht das Dokument selbst.
Diese zwanzig vollständigen Adressen konnten dann sehr schnell durchsucht werden, ohne dass die Daten aus den zwanzig Dokumenten abgerufen werden mussten. Mit dem Primärschlüssel, der sich in 인덱스 befand, konnte sie schließlich sehr schnell das richtige Dokument aus der Sammlung abrufen.
Einfügen eines eingebetteten Arrays in eine Suche
Versuchen wir es mit einer Abfrage, die etwas komplexer ist.
Wir möchten nach dem Nachnamen und der E-Mail-Adresse des Kunden suchen.
Unsere Dokumentensammlung ermöglicht es unserem "Kunden", eine oder mehrere E-Mail-Adressen zu haben. Diese befinden sich in einem eingebetteten Array.
Wir wollen nur jemanden mit einem bestimmten Nachnamen finden, in unserem Beispiel "Barker", und eine bestimmte E-Mail-Adresse, in unserem Beispiel "[email protected]".
Wir wollen nur die übereinstimmende E-Mail-Adresse und ihre Details zurückgeben (wann sie registriert wurde und wann sie ungültig wurde). Wir werden dies von der Shell aus ausführen und die Ausführungsstatistiken untersuchen.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Das ergibt:
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
Dies sagt uns, dass Cassie Barker die E-Mail-Adresse [email protected] vom 11. Januar 2016 bis zum 25. Januar 2018 hatte. Als wir die Abfrage durchführten, dauerte sie 240 ms, weil es keine nützliche 인덱스 gab (es wurden alle 40000 Dokumente in einem COLLSCAN untersucht).
Zu diesem Zweck können wir einen Index erstellen:
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
Mit diesem Index konnte die Ausführungszeit auf 6 ms reduziert werden.
Die Nad 인덱스 , die als einzige für die Sammlung verfügbar war, bezog sich nur auf das Feld Name.Nachname.
Für die Eingabestufe wurde die IXSCAN-Strategie verwendet, die sehr schnell 33 übereinstimmende Dokumente lieferte, und man kam voran.
Anschließend wurden die übereinstimmenden Dokumente gefiltert, um das Array EmailAddresses für die Adresse abzurufen, die dann in der Projektionsphase zurückgegeben wurde. Insgesamt wurden 3 Ms verwendet, im Gegensatz zu den 70 Ms, die es brauchte.
Die Hinzufügung anderer Felder auf der Website 인덱스 hatte keine spürbaren Auswirkungen. Das erste Feld von 인덱스 ist für den Erfolg ausschlaggebend.
Was wäre, wenn wir nur wissen wollten, wer eine bestimmte E-Mail-Adresse verwendet?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Hier wirkt ein 인덱스 für das Feld emailAddress Wunder. Ohne ein geeignetes 인덱스 wird ein COLLSCAN durchgeführt, der auf meinem Entwicklungsserver etwa 70 Ms benötigt.
Mit einem Index...
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
... die benötigte Zeit ist bereits zu schnell, um sie zu messen.
Sie werden bemerkt haben, dass MongoDB zum Indizieren eines Feldes, das einen Array-Wert enthält, einen Indexschlüssel für jedes Element im Array erstellt.
Wir könnten es noch schneller machen, wenn wir davon ausgehen, dass E-Mail-Adressen eindeutig sind (in diesen gefälschten Daten sind sie es nicht, und im wirklichen Leben ist dies eine gefährliche Annahme!)
Wir können auch die 인덱스 verwenden, um den Abruf des Feldes "Vollständiger Name" zu "decken", so dass MongoDB diesen Wert von der 인덱스 abrufen kann, anstatt ihn aus der Datenbank abzurufen, aber der Anteil der Zeitersparnis wird gering sein.
Ein Grund dafür, dass Indexabfragen so gut funktionieren, ist, dass sie in der Regel viel bessere Trefferquoten im Cache erzielen als vollständige Sammlungsscans. Wenn jedoch die gesamte Sammlung in den Cache passt, kommt ein Sammlungsscan der Indexgeschwindigkeit näher.
Verwendung von Aggregaten
Schauen wir uns die beliebtesten Namen in unserer Kundenliste an, indem wir eine Aggregation verwenden. Wir stellen eine 인덱스 zu "Name.Nachname" bereit.
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
In unseren Top Ten finden sich also viele Mitglieder der Familie Snyder:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
Dies dauerte trotz COLLSCAN nur 8 Ms, da die gesamte Datenbank im Cache-Speicher gehalten werden konnte.
Es wird derselbe Abfrageplan verwendet, auch wenn Sie die Aggregation über ein nicht indiziertes Feld durchführen. (Elisha, Eric, Kim und Lee sind die beliebten Vornamen!)
Ich frage mich, welche Vornamen die meisten Notizen in ihrer Akte anziehen?
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
In meinen gefälschten Daten sind es die Personen mit dem Namen Charisse, die die meisten Noten erhalten. Hier wissen wir, dass ein COLLSCAN unvermeidlich ist, da sich die Anzahl der Notizen in einem Live-System ändern wird. Einige Datenbanken erlauben Indizes für berechnete Spalten, aber das würde hier nicht helfen.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
Die Leistung von Aggregationen kann durch einen Index verbessert werden, da sie die Aggregation abdecken können. Nur die Pipeline-Operatoren "$match" und "$sort" können die Vorteile eines Indexes direkt nutzen, und auch nur dann, wenn sie am Anfang der Pipeline stehen.
Der SQL Data Generator wurde für die Erstellung der Testdaten in diesem Lernprogramm verwendet.
Schlussfolgerungen
- Wenn Sie eine Indizierungsstrategie für MongoDB entwickeln, müssen Sie eine Reihe von Faktoren berücksichtigen, z. B. die Struktur der Daten, das Nutzungsmuster und die Konfiguration der Datenbankserver.
- MongoDB verwendet bei der Ausführung einer Abfrage in der Regel nur einen 인덱스 , und zwar sowohl für die Suche als auch für die Sortierung, und wenn eine Strategie zur Auswahl steht, werden die besten Kandidaten-Indizes ausgewählt.
- In den meisten Datensammlungen gibt es einige recht gute Kandidaten für Indizes, die wahrscheinlich eine klare Unterscheidung zwischen den Dokumenten in der Sammlung ermöglichen und die bei der Durchführung von Suchvorgängen wahrscheinlich beliebt sind.
- Es ist eine gute Idee, mit Indizes sparsam umzugehen, da sie nur wenig Ressourcen verbrauchen. Eine größere Gefahr besteht darin, dass man vergisst, was bereits vorhanden ist. Glücklicherweise ist es in MongoDB nicht möglich, doppelte Indizes zu erstellen.
- Es ist immer noch möglich, mehrere zusammengesetzte Indizes zu erstellen, die in ihrer Zusammensetzung sehr ähnlich sind. Wenn ein 인덱스 nicht verwendet wird, ist es am besten, ihn wegzulassen.
- Zusammengesetzte Indizes sind sehr gut geeignet, um Abfragen zu unterstützen. Sie verwenden das erste Feld für die Suche und verwenden dann die Werte in den anderen Feldern, um die Ergebnisse zurückzugeben, anstatt die Werte aus den Dokumenten zu holen. Sie unterstützen auch Sortierungen, die mehr als ein Feld verwenden, solange diese in der richtigen Reihenfolge sind.
- Damit Indizes für String-Vergleiche wirksam sind, müssen sie die gleiche Sortierung verwenden.
- Es lohnt sich, die Leistung von Abfragen im Auge zu behalten. Neben der Verwendung der von explain() zurückgegebenen Werte lohnt es sich, die Abfragen zu timen und auf langlaufende Abfragen zu prüfen, indem die Profilerstellung aktiviert und die langsamen Abfragen untersucht werden. Es ist oft überraschend einfach, die Geschwindigkeit solcher Abfragen durch die Bereitstellung der richtigen 인덱스 zu verändern.
FAQs über MongoDB-Indizes
Indizes verlangsamen MongoDB-Abfragen nicht. Wenn jedoch ein Dokument erstellt, aktualisiert oder gelöscht wird, müssen auch die zugehörigen Indizes aktualisiert werden, was sich auf die Schreibleistung auswirkt.
Sie sollten die Indizierung in MongoDB vermeiden, wenn Sie eine kleine Sammlung haben oder wenn Sie eine Sammlung haben, die nicht häufig abgefragt wird.
Da MongoDB für jeden 인덱스 eine Datei erstellt, können zu viele Indizes die Leistung beeinträchtigen. Wenn die MongoDB-Speicher-Engine gestartet wird, werden alle Dateien geöffnet, so dass die Leistung bei einer übermäßigen Anzahl von Indizes abnimmt.
Doppelklicken Sie auf das Feld Indizes in der Verbindungsstruktur für die Sammlungen, die Sie vergleichen möchten, so dass Sie zwei Registerkarten 인덱스 Manager erhalten. Klicken Sie mit der rechten Maustaste auf den oberen Rand einer der Registerkarten und wählen Sie Vertikal teilen. Die Registerkarten werden nebeneinander angezeigt, so dass Sie die Indizes für die beiden Datenbanken vergleichen können.
Führen Sie Ihre Abfrage auf der Registerkarte "Sammlungen" aus und öffnen Sie die Registerkarte "Erklären", um eine visuelle Darstellung der Verarbeitung der Abfrage durch MongoDB zu sehen. Wenn die Abfrage eine 인덱스 verwendet hat, sehen Sie eine 인덱스 scannen Stufe, andernfalls sehen Sie eine Sammlung scannen Stufe. Informationen zur Verwendung der Registerkarte Explain finden Sie im Knowledge Base-Artikel Visuelles Explain | MongoDB Explain, visualisiert.
Suchen Sie die Sammlung in der Verbindungsstruktur, und doppelklicken Sie auf den Abschnitt Indizes, um den 인덱스 Manager zu öffnen. Der 인덱스 Manager zeigt die Größeninformationen für jede 인덱스 der Sammlung an.
Suchen Sie die Sammlung in der Verbindungsstruktur. Die Indizes werden im Abschnitt Indizes unter dem Namen der Sammlung aufgeführt. Doppelklicken Sie auf einen 인덱스 , um eine schreibgeschützte Version seiner Details anzuzeigen. Größe und Verwendungsdetails werden auf der Registerkarte 인덱스 Manager auf der Registerkarte Sammlungen angezeigt.
Wenn MongoDB eine 인덱스 erstellt, wird die Sammlung vorübergehend gesperrt, was alle Lese- und Schreibvorgänge auf die Daten in dieser Sammlung verhindert. MongoDB erstellt 인덱스 Metadaten, eine temporäre Tabelle mit Schlüsseln und eine temporäre Tabelle mit Beschränkungsverletzungen. Die Sperre für die Sammlung wird dann aufgehoben, und Lese- und Schreibvorgänge werden in regelmäßigen Abständen zugelassen. MongoDB scannt die Dokumente in der Sammlung und schreibt in die temporären Tabellen. Während MongoDB die 인덱스 aufbaut, gibt es mehrere Schritte im Prozess, bei denen die Sammlung ausschließlich gesperrt ist. Alle Einzelheiten zum Erstellungsprozess finden Sie in der MongoDB Dokumentation. Wenn 인덱스 erstellt ist, aktualisiert MongoDB die 인덱스 Metadaten und gibt die Sperre frei.
Wenn Ihre Sammlung in einer Produktionsumgebung eine hohe Schreiblast hat, sollten Sie in Erwägung ziehen, Ihre 인덱스 in Zeiten mit reduziertem Betrieb zu erstellen, z. B. während Wartungsperioden, so dass die Leistung nicht beeinträchtigt wird und die 인덱스 Erstellungszeit kürzer ist.
Wenn Sie eine 인덱스 in MongoDB erstellen, gibt die Ziffer 1 an, dass Sie die 인덱스 in aufsteigender Reihenfolge erstellen möchten. Um eine 인덱스 in absteigender Reihenfolge zu erstellen, verwenden Sie -1.
Erfahren Sie mehr über MongoDB-Indizes
Möchten Sie mehr über MongoDB-Indizes erfahren? Sehen Sie sich diese verwandten Knowledge-Base-Artikel an:
Optimieren von MongoDB-Abfragen mit find() und Indizes
Wie man den MongoDB Profiler und explain() verwendet, um langsame Abfragen zu finden
Visual Explain | MongoDB Explain, visualisiert
Artikel aktualisiert von Kirsty Burgess am 03/05/2023
Kirsty ist unsere Chef-Schriftstellerin. Wenn sie nicht bei 3T arbeitet, kann man Kirsty dabei beobachten, wie sie mit Skistiefeln eine Dreieckspose macht, in der Küche ein Chaos mit allen Gläsern aus dem Gewürzschrank anrichtet oder auf dem Hügel hinter ihrem Haus spazieren geht und auf die hohen Gebäude am Horizont schaut.






