
Lorsque vous commencez à travailler avec MongoDB, vous utilisez généralement l'option find() pour un large éventail de requêtes. Cependant, dès que vos requêtes deviennent plus avancées, vous aurez besoin d'en savoir plus sur l'agrégation MongoDB.
Dans cet article, j'expliquerai les grands principes de la construction de requêtes agrégées dans MongoDB et comment tirer parti des index pour les accélérer.
En outre, je présenterai les étapes les plus importantes du pipeline d'agrégation avec de courts exemples pour chacune d'entre elles, et comment les appliquer au pipeline.

Qu'est-ce que l'agrégation dans MongoDB ?
L'agrégation est une manière de traiter un grand nombre de documents dans une collection en les faisant passer par différentes étapes. Ces étapes constituent ce que l'on appelle un pipeline. Les étapes d'un pipeline peuvent filtrer, trier, grouper, remodeler et modifier les documents qui passent par le pipeline.
L'un des cas d'utilisation les plus courants de l'agrégation consiste à calculer des valeurs agrégées pour des groupes de documents. Ceci est similaire à l'agrégation de base disponible en SQL avec la clause GROUP BY et les fonctions COUNT, SUM et AVG. L'agrégation MongoDB va cependant plus loin et peut également effectuer des jointures de type relationnel, remodeler des documents, créer de nouvelles collections et mettre à jour des collections existantes, etc.
Bien qu'il existe d'autres méthodes pour obtenir des données agrégées dans MongoDB, le cadre d'agrégation est l'approche recommandée pour la plupart des travaux.
Il existe ce que l'on appelle des méthodes à but unique comme estimatedDocumentCount(), count()et distinct() qui sont ajoutés à un find() ce qui les rend rapides à utiliser mais limités dans leur champ d'application.
Le cadre map-reduce de MongoDB est un prédécesseur du cadre d'agrégation et son utilisation est beaucoup plus complexe.
Comment fonctionne le pipeline d'agrégation MongoDB ?
Voici un diagramme illustrant un pipeline d'agrégation MongoDB typique.
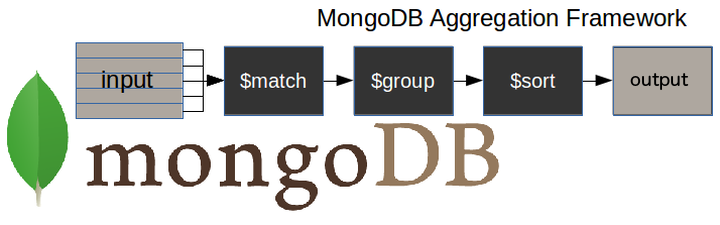
$matchétape - filtre les documents avec lesquels nous devons travailler, ceux qui répondent à nos besoins$groupétape - effectue le travail d'agrégation$sortétape - trie les documents résultants de la manière que nous souhaitons (par ordre croissant ou décroissant).
L'entrée du pipeline peut être une collection unique, les autres pouvant être fusionnées plus tard dans le pipeline.
Le pipeline effectue ensuite des transformations successives sur les données jusqu'à ce que notre objectif soit atteint.
De cette manière, nous pouvons décomposer une requête complexe en étapes plus simples, dans chacune desquelles nous effectuons une opération différente sur les données. Ainsi, à la fin du pipeline de requêtes, nous aurons réalisé tout ce que nous voulions.
Cette approche nous permet de vérifier si notre requête fonctionne correctement à chaque étape en examinant à la fois son entrée et sa sortie. La sortie de chaque étape sera l'entrée de la suivante.

Il n'y a pas de limite au nombre d'étapes utilisées dans la requête, ni à la manière de les combiner.
En matière de requêtes, il convient de prendre en compte un certain nombre de bonnes pratiques pour obtenir des performances optimales. Nous y reviendrons plus loin dans cet article.
Syntaxe du pipeline d'agrégats MongoDB
Voici un exemple de construction d'une requête d'agrégation :
db.collectionName.aggregate(pipeline, options),
- où NomCollection - est le nom d'une collection,
- pipeline - est un tableau qui contient les étapes de l'agrégation,
- options - paramètres optionnels pour l'agrégation
Voici un exemple de la syntaxe du pipeline d'agrégation :
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
Limites de l'étape d'agrégation de MongoDB
L'agrégation fonctionne en mémoire. Chaque étape peut utiliser jusqu'à 100 Mo de RAM. Vous recevrez une erreur de la base de données si vous dépassez cette limite.
Si cela devient un problème inévitable, vous pouvez opter pour la méthode de la page sur disque, avec le seul inconvénient que vous attendrez un peu plus longtemps parce qu'il est plus lent de travailler sur le disque plutôt qu'en mémoire. Pour choisir la méthode de la page sur disque, il suffit de définir l'option allowDiskUse à la vérité comme ceci :
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
Notez que cette option n'est pas toujours disponible pour les services partagés. Par exemple, les clusters Atlas M0, M2 et M5 désactivent cette option.
Les documents retournés par la requête d'agrégation, soit sous forme de curseur, soit stockés par l'intermédiaire de $out dans une autre collection, sont limitées à 16 Mo. En d'autres termes, ils ne peuvent pas dépasser la taille maximale d'un document MongoDB.
Si vous êtes susceptible de dépasser cette limite, vous devez spécifier que la sortie de la requête d'agrégation se fera sous la forme d'un curseur et non d'un document.
Nos données utilisées pour les exemples d'agrégats MongoDB
Je montrerai des exemples d'agrégats MongoDB pour les étapes les plus importantes du pipeline.
Pour illustrer les exemples, je vais utiliser deux collections. La première s'appelle 'universities' et est constitué de ces documents (les données ne sont pas réelles) :
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
Si vous souhaitez tester ces exemples sur votre propre installation, vous pouvez les insérer à l'aide de la commande bulk ci-dessous.
use 3tdb
db.universities.insertMany([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
])
La deuxième et dernière collection s'appelle 'courses' et se présente comme suit :
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
}
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
}
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
Là encore, vous pouvez les insérer de la même manière, en utilisant le code suivant :
db.courses.insertMany([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
])
Exemples d'agrégats MongoDB
MongoDB $match
Le $match étape nous permet de choisir, dans une collection, les documents avec lesquels nous voulons travailler. Pour effectuer cela, elle filtre les documents qui ne répondent pas à nos exigences.
Dans l'exemple suivant, nous ne voulons travailler qu'avec les documents qui spécifient que Spain est la valeur du champ countryet Salamanca est la valeur du champ city.
Afin d'obtenir un résultat lisible, je vais ajouter .pretty() à la fin de toutes les commandes.
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
]).pretty()
Le résultat est...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain","city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
]
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdbaa"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "UPSA",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6691191,
17,
40.9631732
]
},
"students" : [
{
"year" : 2014,
"number" : 4788
},
{
"year" : 2015,
"number" : 4821
},
{
"year" : 2016,
"number" : 6550
},
{
"year" : 2017,
"number" : 6125
}
]
}
MongoDB $projet
Il est rare que vous ayez besoin de récupérer tous les champs de vos documents. Une bonne pratique consiste à ne renvoyer que les champs dont vous avez besoin afin d'éviter de traiter plus de données qu'il n'est nécessaire.
Le $project étape est utilisée pour effectuer cela et pour ajouter les champs calculés dont vous avez besoin.
Dans cet exemple, nous n'avons besoin que des champs country, cityet name.
Dans le code qui suit, veuillez noter que :
- Nous devons écrire explicitement
_id : 0lorsque ce champ n'est pas requis - Outre les
_idil suffit de spécifier uniquement les champs que nous devons obtenir comme résultat de la requête
Cette étape ...
db.universities.aggregate([
{ $project : { _id : 0, country : 1, city : 1, name : 1 } }
]).pretty()
... donnera le résultat ...
{ "country" : "Spain", "city" : "Salamanca", "name" : "USAL" }
{ "country" : "Spain", "city" : "Salamanca", "name" : "UPSA" }
MongoDB $group
Avec la $group nous pouvons effectuer toutes les requêtes d'agrégation ou de synthèse dont nous avons besoin, telles que la recherche de comptes, de totaux, de moyennes ou de maximums.
Dans cet exemple, nous voulons connaître le nombre de documents par université dans notre base de données.universitiesLa collection de l'Institut de recherche et de développement de l'Union européenne :
La requête ...
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } }
]).pretty()
... produira ce résultat ...
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
Opérateurs d'agrégation MongoDB $group
L'étape $group prend en charge certaines expressions (opérateurs) permettant aux utilisateurs d'effectuer diverses opérations (arithmétiques, de tableau, booléennes, etc) dans le cadre du processus d'agrégation.
| Opérateur | Signification |
| $count | Calcule la quantité de documents dans le groupe donné. |
| max. | Affiche la valeur maximale du champ d'un document dans la collection. |
| $min | Affiche la valeur minimale du champ d'un document dans la collection. |
| $avg | Affiche la valeur moyenne du champ d'un document dans la collection. |
| Somme | Additionne les valeurs spécifiées de tous les documents de la collection. |
| $push | Ajoute des valeurs supplémentaires dans le tableau du document résultant. |
Consultez les opérateurs MongoDB et apprenez-en plus sur les autres opérateurs.
MongoDB $out
Il s'agit d'un type d'étape inhabituel car il vous permet de reporter les résultats de votre agrégation dans une nouvelle collection, ou dans une collection existante après l'avoir supprimée, ou même de les ajouter aux documents existants.
Le $out doit être la dernière étape du pipeline.
Pour la première fois, nous utilisons une agrégation avec plus d'une étape. Nous en avons maintenant deux, une $group et un $out:
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } },
{ $out : 'aggResults' }
])
Nous vérifions maintenant le contenu du nouveau 'aggResultsLa collection de l'Institut de recherche et de développement de l'Union européenne :
db.aggResults.find().pretty()
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
Maintenant que nous avons produit une agrégation en plusieurs étapes, nous pouvons continuer à construire un pipeline.
MongoDB $unwind
Le $unwind l'étape dans MongoDB se trouve généralement dans un pipeline parce qu'il s'agit d'un moyen de parvenir à une fin.
Vous ne pouvez pas travailler directement sur les éléments d'un tableau à l'intérieur d'un document avec des étapes telles que $group. Les $unwind nous permet de travailler avec les valeurs des champs d'un tableau.
Lorsque les documents d'entrée contiennent un champ de type tableau, il est parfois nécessaire d'éditer le document plusieurs fois, une fois pour chaque élément du tableau.
Le champ du tableau est remplacé par l'élément successif pour chaque copie du document.
Dans l'exemple suivant, je vais appliquer l'étape uniquement au document dont le champ name contient la valeur USAL.
Voici le document :
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
Maintenant, nous appliquons le $unwind sur le tableau de l'élève, et vérifier que nous obtenons un document pour chaque élément du tableau.
Le premier document est constitué des champs du premier élément du tableau et du reste des champs communs.
Le deuxième document est constitué des champs du deuxième élément du tableau et du reste des champs communs, et ainsi de suite.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
]).pretty()
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
MongoDB $sort
Vous avez besoin du $sort pour trier vos résultats en fonction de la valeur d'un champ spécifique.
Par exemple, trions les documents obtenus à la suite de l'opération $unwind par ordre décroissant du nombre d'étudiants.
Afin d'obtenir un résultat moindre, je vais projeter uniquement l'année et le nombre d'étudiants.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
]).pretty()
Cela donne le résultat ...
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
{ "students" : { "year" : 2016, "number" : 21913 } }
{ "students" : { "year" : 2017, "number" : 21715 } }
MongoDB $limit
Que faire si vous n'êtes intéressé que par les deux premiers résultats de votre requête ? C'est aussi simple que cela :
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } },
{ $limit : 2 }
]).pretty()
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
Notez que lorsque vous devez limiter le nombre de documents triés, vous devez utiliser l'option $limit étape juste après les $sort.
Nous disposons à présent d'un pipeline complet.
Nous pouvons coller cette requête agrégée MongoDB et toutes ses étapes directement dans l'éditeur d'agrégation de Studio 3T.
Seule la partie ci-dessous est copiée et collée :
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
])
Il est collé en le copiant et en cliquant sur le bouton Coller comme indiqué.
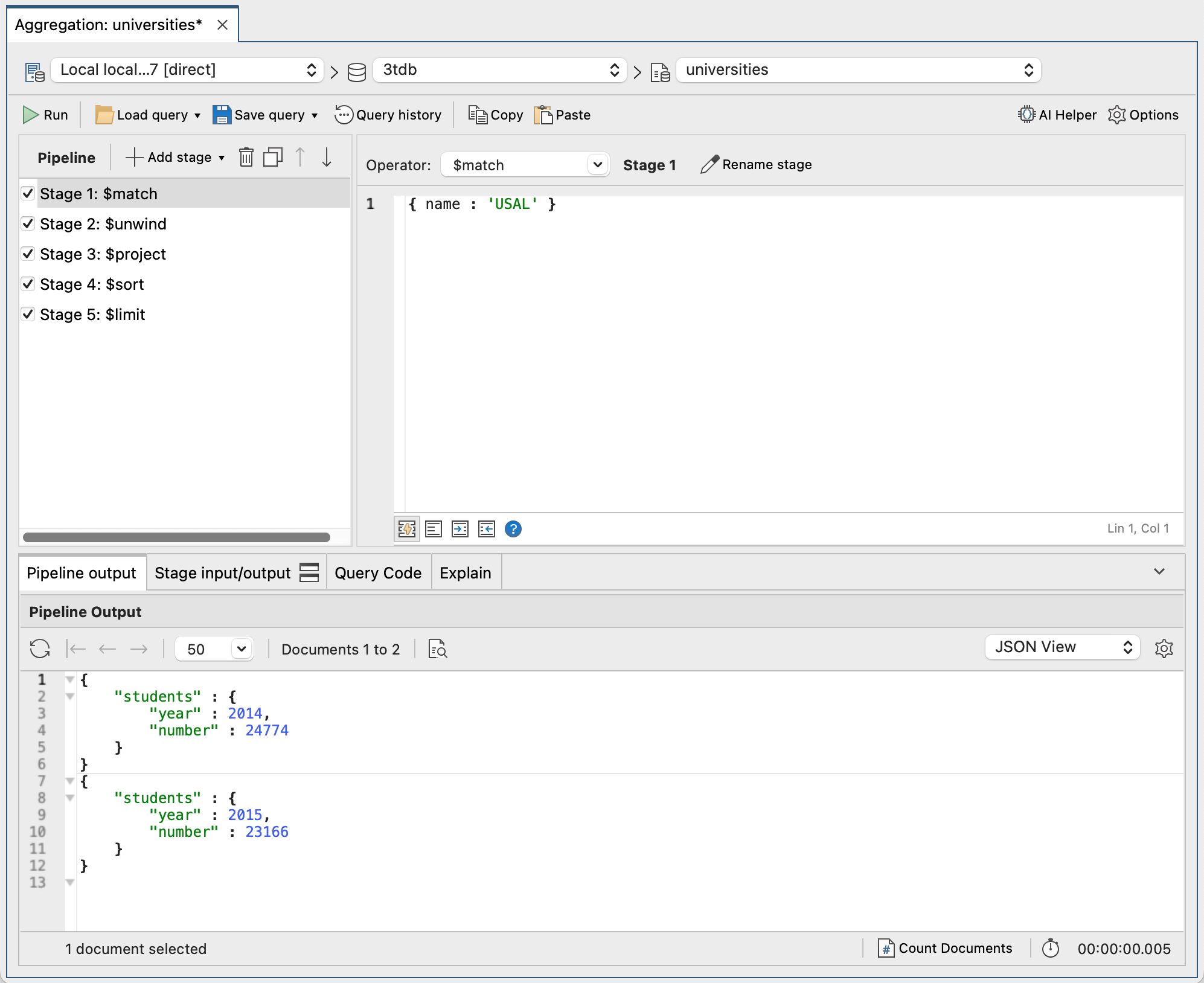
Dans la capture d'écran suivante, nous pouvons voir le pipeline complet dans Studio 3T, ainsi que son résultat.
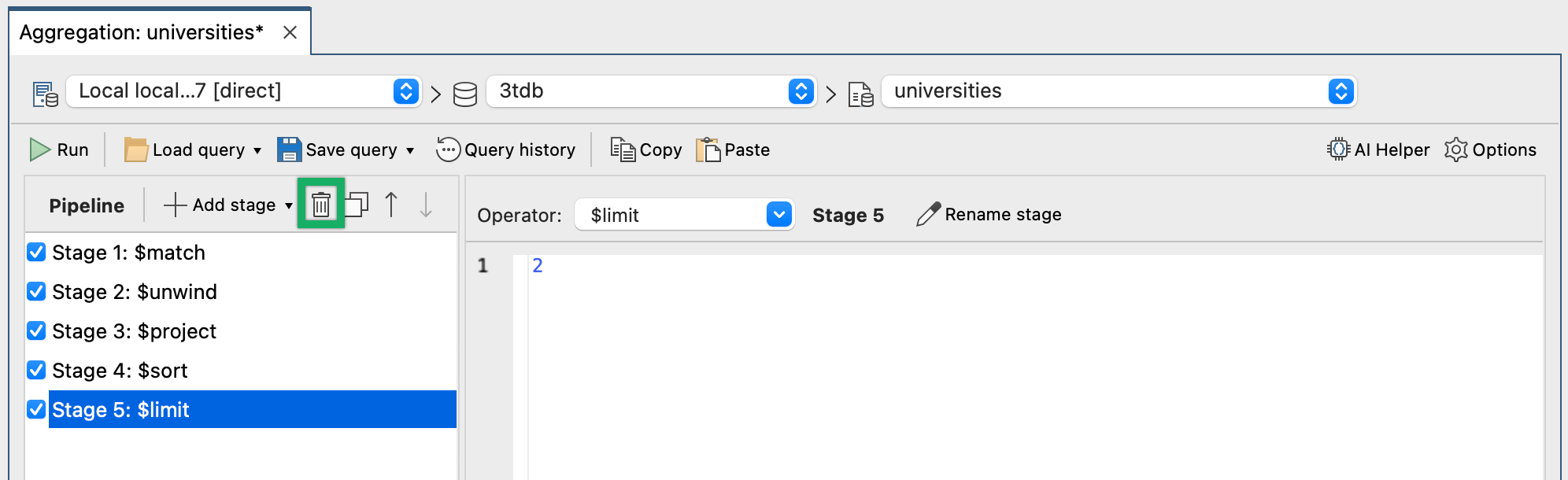
Pour supprimer des étapes dans Studio 3T, il suffit de sélectionner l'étape et d'utiliser le bouton illustré dans la capture d'écran suivante.
$addFields
Il peut arriver que vous deviez apporter des modifications à vos résultats en ajoutant de nouveaux champs. Dans l'exemple suivant, nous souhaitons ajouter l'année de création de l'université.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $addFields : { foundation_year : 1218 } }
]).pretty()
Cela donne le résultat ...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
],
"foundation_year" : 1218
}
MongoDB $count
Le $count permet de vérifier facilement le nombre de documents obtenus à l'issue des étapes précédentes du pipeline.
Voyons ce qu'il en est :
db.universities.aggregate([
{ $unwind : '$students' },
{ $count : 'total_documents' }
]).pretty()
Cela donne le total des années pour lesquelles nous connaissons le nombre d'étudiants à l'Université.
{ "total_documents" : 8 }
MongoDB $lookup
MongoDB étant basé sur des documents, nous pouvons façonner nos documents comme nous le souhaitons. Cependant, il est souvent nécessaire d'utiliser des informations provenant de plusieurs collections.
L'utilisation de la $lookupVoici une requête agrégée qui fusionne les champs de deux collections.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $project : { _id : 0, name : 1 } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} }
]).pretty()
Si vous voulez que cette requête s'exécute rapidement, vous devrez indexer le fichier name champ dans le universities collection et university champ dans le courses collection.
En d'autres termes, n'oubliez pas d'indexer les champs concernés par la $lookup.
{
"name" : "USAL",
"courses" : [
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbab"),
"university" : "USAL",
"name" : "Computer Science",
"level" : "Excellent"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbac"),
"university" : "USAL",
"name" : "Electronics",
"level" : "Intermediate"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbad"),
"university" : "USAL",
"name" : "Communication",
"level" : "Excellent"
}
]
}
MongoDB $sortByCount
Cette étape est un raccourci pour regrouper, compter et trier par ordre décroissant le nombre de valeurs différentes dans un champ.
Supposons que vous souhaitiez connaître le nombre de cours par niveau, classés par ordre décroissant. Voici la requête que vous auriez à construire :
db.courses.aggregate([
{ $sortByCount : '$level' }
]).pretty()
Voici le résultat :
{ "_id" : "Excellent", "count" : 2 }
{ "_id" : "Intermediate", "count" : 1 }
MongoDB $facet
Lors de la création d'un état des données, il arrive que l'on doive effectuer le même traitement préliminaire pour un certain nombre d'états et que l'on doive créer et gérer une collection intermédiaire.
Vous pouvez, par exemple, réaliser un résumé hebdomadaire des transactions qui sera utilisé dans tous les rapports ultérieurs. Vous auriez pu souhaiter qu'il soit possible d'exécuter simultanément plus d'un pipeline sur la sortie d'un seul pipeline d'agrégation.
Nous pouvons maintenant le faire dans un seul pipeline grâce à la fonction $facet étape.
Voici un exemple :
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} },
{ $facet : {
'countingLevels' :
[
{ $unwind : '$courses' },
{ $sortByCount : '$courses.level' }
],
'yearWithLessStudents' :
[
{ $unwind : '$students' },
{ $project : { _id : 0, students : 1 } },
{ $sort : { 'students.number' : 1 } },
{ $limit : 1 }
]
} }
]).pretty()
Nous avons créé deux rapports à partir de notre base de données de cours universitaires : countingLevels et yearWithLessStudents.
Ils utilisent tous deux la sortie des deux premières étapes, le $match et le $lookup.
Dans le cas d'une collection volumineuse, cela permet de gagner beaucoup de temps de traitement en évitant les répétitions, il n'est plus alors nécessaire d'écrire une collection temporaire intermédiaire.
{
"countingLevels" : [
{
"_id" : "Excellent",
"count" : 2
},
{
"_id" : "Intermediate",
"count" : 1
}
],
"yearWithLessStudents" : [
{
"students" : {
"year" : 2017,
"number" : 21715
}
}
]
}
Exercice
Maintenant, essayez de résoudre l'exercice suivant par vous-même.
Comment obtenir le nombre total d'étudiants ayant appartenu à chacune des universités ?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } }
]).pretty()
Le résultat :
{ "_id" : "UPSA", "totalalumni" : 22284 }
{ "_id" : "USAL", "totalalumni" : 91568 }
Oui, j'ai combiné deux étapes. Mais comment construire une requête qui trie la sortie selon le critère totalalumni dans un ordre décroissant ?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } },
{ $sort : { totalalumni : -1 } }
]).pretty()
Bien, nous devons appliquer le $sort() à la sortie de l'étape $group().
Vérification de notre requête d'agrégation
J'ai mentionné plus haut qu'il est très facile, et même essentiel, de vérifier que les étapes de notre requête se déroulent comme nous le souhaitons.
Avec Studio 3T, vous disposez de deux panneaux pour vérifier les documents d'entrée et de sortie pour une étape donnée.
Performance
Le pipeline d'agrégation remodèle automatiquement la requête dans le but d'améliorer ses performances.
Si vous avez les deux $sort et $match il est toujours préférable d'utiliser le $match avant le $sort afin de réduire au minimum le nombre de documents que le $sort l'étape doit faire face.
Pour tirer parti des index, vous devez le faire dans la première étape de votre pipeline. Et là, vous devez utiliser la fonction $match ou le $sort étapes.
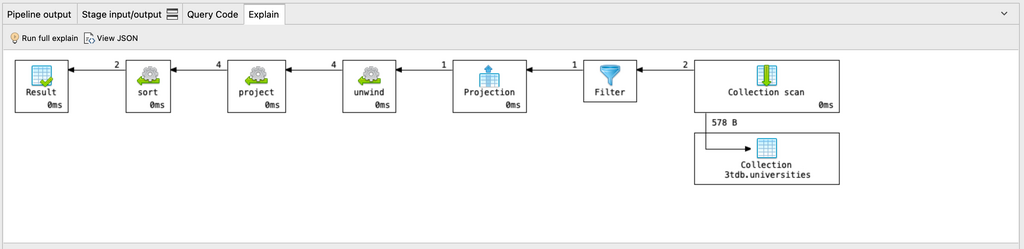
Nous pouvons vérifier si la requête utilise un index à l'aide de la fonction explain() méthode.
pipeline = [...]
db.<collectionName>.aggregate( pipeline, { explain : true })
Vous pouvez toujours consulter le explain() plan de toute requête d'agrégation sous forme de diagramme ou en JSON en cliquant sur l'onglet Expliquer.
Conclusion
J'ai présenté le pipeline d'agrégation MongoDB et démontré à l'aide d'exemples comment n'utiliser que certaines étapes.
Plus vous utilisez MongoDB, plus le pipeline d'agrégation devient important pour vous permettre d'effectuer toutes les tâches de reporting, de transformation et d'interrogation avancée qui font partie intégrante du travail d'un développeur de base de données.
Avec les processus de pipeline plus complexes, il devient de plus en plus important de vérifier et de déboguer l'entrée et la sortie de chaque étape.
Il y a toujours un moment où vous devez coller le pipeline d'agrégation croissant dans un IDE pour MongoDB tel que Studio 3T, avec un éditeur d'agrégation intégré, de sorte que vous puissiez déboguer chaque étape indépendamment.







