
Quando si inizia a lavorare con MongoDB, di solito si usa il metodo find() per un'ampia gamma di query. Tuttavia, non appena le query diventano più avanzate, è necessario conoscere meglio l'aggregazione di MongoDB.
In questo articolo spiegherò i principi principali della costruzione di query aggregate in MongoDB e come sfruttare gli indici per velocizzarle.
Inoltre, introdurrò le fasi più importanti della pipeline di aggregazione, con brevi esempi che utilizzano ciascuna di esse, e come applicarle alla pipeline.

Che cos'è l'aggregazione in MongoDB?
L'aggregazione è un modo per elaborare un gran numero di documenti in una raccolta facendoli passare attraverso diversi stadi. Gli stadi costituiscono la cosiddetta pipeline. Gli stadi di una pipeline possono filtrare, ordinare, raggruppare, rimodellare e modificare i documenti che passano attraverso la pipeline.
Uno dei casi d'uso più comuni dell'aggregazione è il calcolo di valori aggregati per gruppi di documenti. Questo è simile all'aggregazione di base disponibile in SQL con la clausola GROUP BY e le funzioni COUNT, SUM e AVG. Tuttavia, l'aggregazione di MongoDB va oltre e può anche eseguire join di tipo relazionale, rimodellare i documenti, creare nuove collezioni e aggiornare quelle esistenti e così via.
Sebbene esistano altri metodi per ottenere dati aggregati in MongoDB, il framework di aggregazione è l'approccio consigliato per la maggior parte dei lavori.
Esistono i cosiddetti metodi a scopo singolo come estimatedDocumentCount(), count(), e distinct() che vengono aggiunti a un file find() che li rende veloci da usare ma di portata limitata.
Il framework map-reduce di MongoDB è un predecessore del framework di aggregazione ed è molto più complesso da usare. MongoDB ha deprecato
Come funziona la pipeline di aggregazione di MongoDB?
Ecco un diagramma che illustra una tipica pipeline di aggregazione di MongoDB.
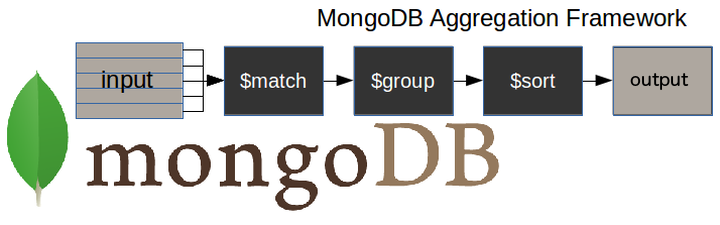
$matchstage - filtra i documenti con cui dobbiamo lavorare, quelli che si adattano alle nostre esigenze$groupstage - esegue il lavoro di aggregazione$sortstage - ordina i documenti risultanti nel modo desiderato (ascendente o discendente)
L'input della pipeline può essere una singola raccolta, mentre altre possono essere unite in un secondo momento.
La pipeline esegue quindi trasformazioni successive sui dati fino al raggiungimento dell'obiettivo.
In questo modo, possiamo suddividere una query complessa in fasi più semplici, in ognuna delle quali completiamo una diversa operazione sui dati. Così, alla fine della pipeline di query, avremo ottenuto tutto ciò che volevamo.
Questo approccio ci permette di verificare se la nostra query funziona correttamente in ogni fase, esaminando sia l'input che l'output. L'output di ogni fase sarà l'input della successiva.
Non c'è limite al numero di stadi utilizzati nella query, né al modo in cui li combiniamo.
Per ottenere prestazioni ottimali delle query, è necessario tenere conto di una serie di best practice. Ne parleremo più avanti nell'articolo.
Sintassi della pipeline aggregata di MongoDB
Questo è un esempio di come costruire una query di aggregazione:
db.collectionName.aggregate(pipeline, options),
- dove collectionName - è il nome di una raccolta,
- pipeline - è un array che contiene le fasi di aggregazione,
- opzioni - parametri opzionali per l'aggregazione
Questo è un esempio di sintassi della pipeline di aggregazione:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
Limiti dello stadio di aggregazione di MongoDB
L'aggregazione funziona in memoria. Ogni fase può utilizzare fino a 100 MB di RAM. Se si supera questo limite, il database emette un errore.
Se diventa un problema inevitabile, si può optare per il metodo della pagina su disco, con l'unico svantaggio di dover aspettare un po' di più perché il lavoro su disco è più lento di quello in memoria. Per scegliere il metodo della pagina su disco, è sufficiente impostare l'opzione allowDiskUse a vero come questo:
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
Si noti che questa opzione non è sempre disponibile per i servizi condivisi. Ad esempio, i cluster Atlas M0, M2 e M5 disabilitano questa opzione.
I documenti restituiti dalla query di aggregazione, sia come cursore che memorizzati tramite $out in un'altra raccolta, sono limitati a 16 MB. Cioè, non possono essere più grandi della dimensione massima di un documento MongoDB.
Se è probabile che si superi questo limite, è necessario specificare che l'output della query di aggregazione sarà un cursore e non un documento.
I nostri dati utilizzati per gli esempi di aggregazione di MongoDB
Mostrerò esempi di aggregazione MongoDB per le fasi più importanti della pipeline.
Per illustrare gli esempi, utilizzerò due collezioni. La prima si chiama 'universities' ed è costituito da questi documenti (i dati non sono reali):
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
Se si desidera testare questi esempi sulla propria installazione, è possibile inserirli con il comando bulk qui sotto, oppure importarli come file JSON:
use 3tdb
db.universities.insert([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
])
La seconda e ultima collezione si chiama 'courses' e si presenta così:
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
}
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
}
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
Anche in questo caso, è possibile inserirli nello stesso modo, utilizzando il codice seguente o importandoli come file JSON:
db.courses.insert([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
])
Esempi di aggregazione MongoDB
MongoDB $match
Il $match stage ci permette di scegliere da una raccolta solo i documenti con cui vogliamo lavorare. Ciò avviene filtrando quelli che non soddisfano i nostri requisiti.
Nell'esempio seguente, si vuole lavorare solo con quei documenti che specificano che Spain è il valore del campo country, e Salamanca è il valore del campo city.
Per ottenere un output leggibile, aggiungerò .pretty() alla fine di tutti i comandi.
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
]).pretty()
L'uscita è...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain","city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
]
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdbaa"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "UPSA",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6691191,
17,
40.9631732
]
},
"students" : [
{
"year" : 2014,
"number" : 4788
},
{
"year" : 2015,
"number" : 4821
},
{
"year" : 2016,
"number" : 6550
},
{
"year" : 2017,
"number" : 6125
}
]
}
MongoDB $progetto
È raro che sia necessario recuperare tutti i campi dei documenti. È buona norma restituire solo i campi necessari, per evitare di elaborare più dati del necessario.
Il $project viene utilizzato per fare questo e per aggiungere tutti i campi calcolati di cui si ha bisogno.
In questo esempio, abbiamo bisogno solo dei campi country, city e name.
Nel codice che segue, si noti che:
- Dobbiamo scrivere esplicitamente
_id : 0quando questo campo non è obbligatorio - A parte il
_idè sufficiente specificare solo i campi che dobbiamo ottenere come risultato della query
Questa fase ...
db.universities.aggregate([
{ $project : { _id : 0, country : 1, city : 1, name : 1 } }
]).pretty()
...darà il risultato...
{ "country" : "Spain", "city" : "Salamanca", "name" : "USAL" }
{ "country" : "Spain", "city" : "Salamanca", "name" : "UPSA" }
MongoDB $gruppo
Con il $group possiamo eseguire tutte le query di aggregazione o di riepilogo di cui abbiamo bisogno, come trovare conteggi, totali, medie o massimi.
In questo esempio, vogliamo conoscere il numero di documenti per università nella nostra 'universities' collezione:
La domanda ...
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } }
]).pretty()
produrrà questo risultato...
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
MongoDB $gruppo operatori di aggregazione
Lo stadio $group supporta alcune espressioni (operatori) che consentono di eseguire operazioni aritmetiche, array, booleane e di altro tipo come parte della pipeline di aggregazione.
| Operatore | Significato |
| $conteggio | Calcola la quantità di documenti nel gruppo dato. |
| $max | Visualizza il valore massimo del campo di un documento nella raccolta. |
| $min | Visualizza il valore minimo del campo di un documento nella raccolta. |
| $avg | Visualizza il valore medio del campo di un documento nella raccolta. |
| $somma | Somma i valori specificati di tutti i documenti della raccolta. |
| $push | Aggiunge valori supplementari all'array del documento risultante. |
Per vedere altri operatori di MongoDB e per saperne di più su questo argomento.
MongoDB $out
Si tratta di un tipo di stadio insolito, perché consente di trasportare i risultati dell'aggregazione in una nuova raccolta, o in una raccolta esistente dopo averla eliminata, o addirittura di aggiungerli ai documenti esistenti (novità della versione 4.1.2).
Il $out deve essere l'ultimo stadio della pipeline.
Per la prima volta, utilizziamo un'aggregazione con più di uno stadio. Ora ne abbiamo due, uno $group e un $out:
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } },
{ $out : 'aggResults' }
])
Ora, controlliamo il contenuto del nuovo 'aggResults' collezione:
db.aggResults.find().pretty()
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
>
Ora che abbiamo prodotto un'aggregazione a più stadi, possiamo procedere alla costruzione di una pipeline.
MongoDB $unwind
Il $unwind in MongoDB si trova comunemente in una pipeline perché è un mezzo per raggiungere un fine.
Non è possibile lavorare direttamente sugli elementi di una matrice all'interno di un documento con stadi come $group. Il $unwind ci permette di lavorare con i valori dei campi all'interno di un array.
Se nei documenti di input è presente un campo array, a volte è necessario produrre il documento più volte, una volta per ogni elemento dell'array.
A ogni copia del documento il campo dell'array viene sostituito con l'elemento successivo.
Nel prossimo esempio, applicherò lo stage solo al documento il cui campo name contiene il valore USAL.
Questo è il documento:
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
Ora, applichiamo il metodo $unwind sull'array degli studenti e verificare che si ottenga un documento per ogni elemento dell'array.
Il primo documento è costituito dai campi del primo elemento dell'array e dal resto dei campi comuni.
Il secondo documento è costituito dai campi del secondo elemento dell'array e dal resto dei campi comuni, e così via.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
]).pretty()
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
MongoDB $sort
È necessario il $sort per ordinare i risultati in base al valore di un campo specifico.
Per esempio, ordiniamo i documenti ottenuti come risultato del $unwind per il numero di studenti in ordine decrescente.
Per ottenere un risultato minore, proietterò solo l'anno e il numero di studenti.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
]).pretty()
Il risultato è ...
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
{ "students" : { "year" : 2016, "number" : 21913 } }
{ "students" : { "year" : 2017, "number" : 21715 } }
MongoDB $limite
E se si è interessati solo ai primi due risultati della ricerca? È molto semplice:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } },
{ $limit : 2 }
]).pretty()
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
Si noti che quando è necessario limitare il numero di documenti ordinati, è necessario utilizzare l'opzione $limit stadio solo dopo il $sort.
Ora abbiamo una pipeline completa.
Possiamo incollare l'intera query aggregata MongoDB e tutte le sue fasi direttamente nell'editor di aggregazione di Studio 3T.
Il codice viene incollato copiandolo e facendo clic sul pulsante incolla codice, come mostrato.
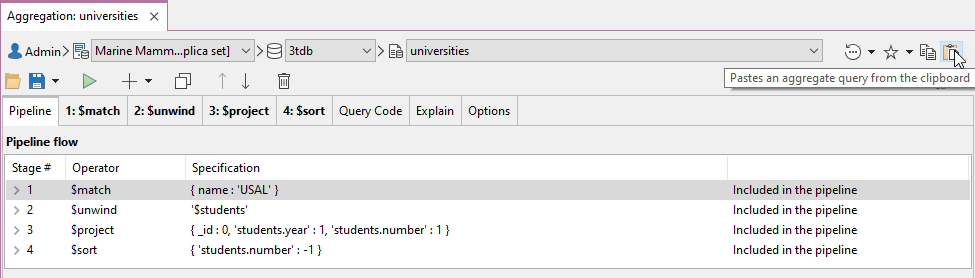
Si copia e si incolla solo la parte mostrata qui sotto
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
])
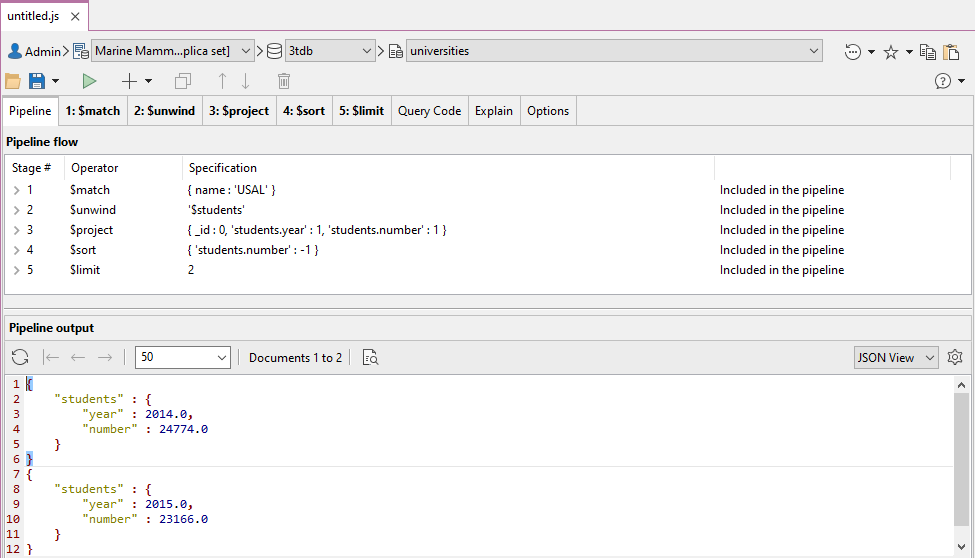
Nella schermata successiva, possiamo vedere la pipeline completa in Studio 3T e il suo output.
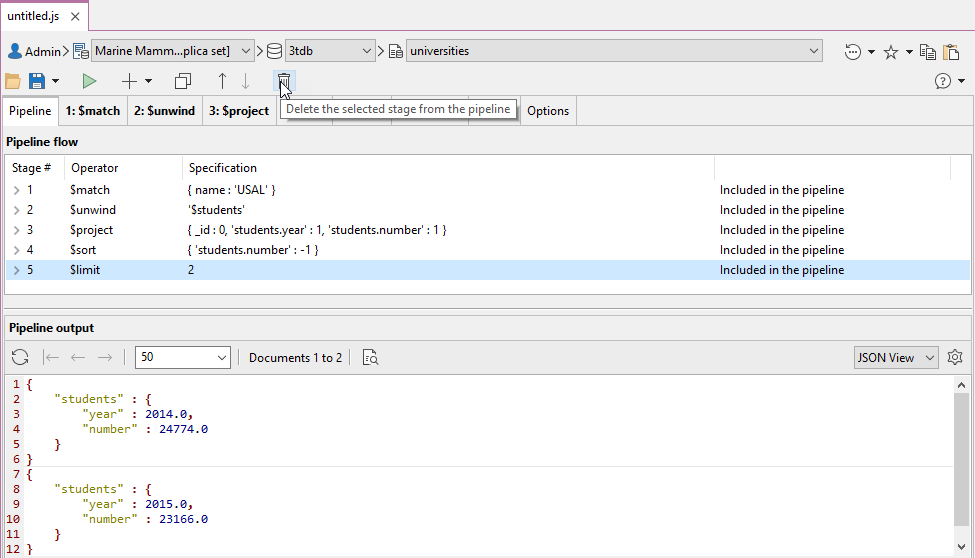
Per rimuovere le fasi in Studio 3T è sufficiente utilizzare il pulsante mostrato nella schermata successiva.
$addFields
È possibile che sia necessario apportare alcune modifiche all'output con l'aggiunta di nuovi campi. Nel prossimo esempio, vogliamo aggiungere l'anno di fondazione dell'università.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $addFields : { foundation_year : 1218 } }
]).pretty()
Il risultato è ...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
],
"foundation_year" : 1218
}
MongoDB $count
Il $count fornisce un modo semplice per verificare il numero di documenti ottenuti nell'output delle fasi precedenti della pipeline.
Vediamolo in azione:
db.universities.aggregate([
{ $unwind : '$students' },
{ $count : 'total_documents' }
]).pretty()
Questo fornisce il totale degli anni per i quali conosciamo il numero di studenti dell'Università.
{ "total_documents" : 8 }
MongoDB $lookup
Poiché MongoDB è basato su documenti, possiamo modellare i nostri documenti nel modo in cui ci serve. Tuttavia, spesso è necessario utilizzare informazioni provenienti da più collezioni.
Utilizzando il $lookupEcco una query aggregata che unisce i campi di due raccolte.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $project : { _id : 0, name : 1 } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} }
]).pretty()
Se si vuole che la query venga eseguita velocemente, è necessario 인덱스 . name nel campo universities e la collezione university nel campo courses collezione.
In altre parole, non si deve dimenticare di 인덱스 i campi coinvolti nel $lookup.
{
"name" : "USAL",
"courses" : [
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbab"),
"university" : "USAL",
"name" : "Computer Science",
"level" : "Excellent"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbac"),
"university" : "USAL",
"name" : "Electronics",
"level" : "Intermediate"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbad"),
"university" : "USAL",
"name" : "Communication",
"level" : "Excellent"
}
]
}
MongoDB $sortByCount
Questa fase è una scorciatoia per raggruppare, contare e quindi ordinare in ordine decrescente il numero di valori diversi in un campo.
Si supponga di voler conoscere il numero di corsi per livello, ordinati in modo decrescente. La query da costruire è la seguente:
db.courses.aggregate([
{ $sortByCount : '$level' }
]).pretty()
Questo è l'output:
{ "_id" : "Excellent", "count" : 2 }
{ "_id" : "Intermediate", "count" : 1 }
MongoDB $facet
A volte, quando si crea un report sui dati, si scopre che è necessario eseguire la stessa elaborazione preliminare per diversi report e ci si trova a dover creare e mantenere una raccolta intermedia.
Ad esempio, si può fare un riepilogo settimanale del trading che viene utilizzato da tutti i report successivi. Si potrebbe desiderare che sia possibile eseguire più di una pipeline simultaneamente sull'output di una singola pipeline di aggregazione.
Ora possiamo farlo all'interno di una singola pipeline, grazie all'opzione $facet stadio.
Guardate questo esempio:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} },
{ $facet : {
'countingLevels' :
[
{ $unwind : '$courses' },
{ $sortByCount : '$courses.level' }
],
'yearWithLessStudents' :
[
{ $unwind : '$students' },
{ $project : { _id : 0, students : 1 } },
{ $sort : { 'students.number' : 1 } },
{ $limit : 1 }
]
} }
]).pretty()
Abbiamo creato due report a partire dal nostro database di corsi universitari. CountingLevels e YearWithLessStudents.
Entrambi hanno utilizzato l'uscita dei primi due stadi, il $match e il $lookup.
Con un insieme di grandi dimensioni, questo può far risparmiare molto tempo di elaborazione, evitando la ripetizione e non è più necessario scrivere un insieme temporaneo intermedio.
{
"countingLevels" : [
{
"_id" : "Excellent",
"count" : 2
},
{
"_id" : "Intermediate",
"count" : 1
}
],
"yearWithLessStudents" : [
{
"students" : {
"year" : 2017,
"number" : 21715
}
}
]
}
Esercizio
Ora provate a risolvere da soli il prossimo esercizio.
Come si ottiene il numero totale di studenti che hanno fatto parte di ciascuna università?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } }
]).pretty()
Il risultato:
{ "_id" : "UPSA", "totalalumni" : 22284 }
{ "_id" : "USAL", "totalalumni" : 91568 }
Sì, ho combinato due fasi. Ma come si fa a costruire una query che ordina l'output in base al valore totalalumni in ordine decrescente?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } },
{ $sort : { totalalumni : -1 } }
]).pretty()
Bene, dobbiamo applicare il metodo $sort() all'uscita dello stadio $group().
Verifica della nostra query di aggregazione
Ho già detto che è molto facile, e anzi essenziale, verificare che le fasi della nostra query funzionino nel modo in cui ci serve.
Con Studio 3T, sono disponibili due pannelli dedicati per controllare i documenti di ingresso e di uscita per ogni particolare fase.
Prestazioni
La pipeline di aggregazione rimodella automaticamente la query con l'obiettivo di migliorarne le prestazioni.
Se si dispone di entrambi $sort e $match è sempre meglio utilizzare il metodo $match prima del $sort al fine di ridurre al minimo il numero di documenti che la $sort deve essere affrontato.
Per sfruttare gli indici, è necessario farlo nella prima fase della pipeline. In questo caso, si deve usare l'opzione $match o il $sort fasi.
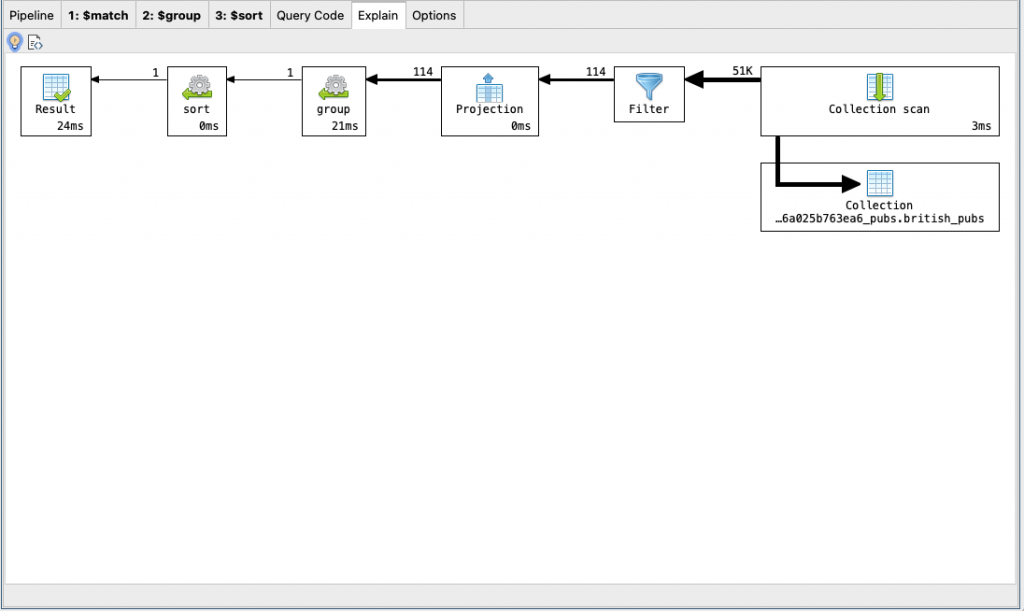
Possiamo verificare se la query sta usando un 인덱스 attraverso il parametro explain() metodo.
pipeline = [...]
db.<collectionName>.aggregate( pipeline, { explain : true })
Conclusione
Ho introdotto la pipeline di aggregazione di MongoDB e ho dimostrato con esempi come utilizzare solo alcune fasi.
Più si utilizza MongoDB, più la pipeline di aggregazione diventa importante per consentire di eseguire tutte quelle operazioni di reporting, trasformazione e interrogazione avanzata che sono parte integrante del lavoro di uno sviluppatore di database.
Con i processi di pipeline più complessi, diventa sempre più importante controllare e debuggare l'ingresso e l'uscita di ogni fase.
C'è sempre un punto in cui è necessario incollare la pipeline di aggregazione in crescita in un IDE per MongoDB come Studio 3T, con un editor di aggregazione integrato, in modo da poter eseguire il debug di ogni fase in modo indipendente.






