
Cuando empiece a trabajar con MongoDB, normalmente utilizará la función find() para una amplia gama de consultas. Sin embargo, en cuanto sus consultas sean más avanzadas, necesitará saber más sobre la agregación de MongoDB.
En este artículo, explicaré los principios fundamentales de la construcción de consultas agregadas en MongoDB y cómo aprovechar los índices para acelerarlas.
Además, presentaré las etapas más importantes de la tubería de agregación con breves ejemplos que utilizan cada una de ellas, y cómo aplicarlas a la tubería.

¿Qué es la agregación en MongoDB?
La agregación es una forma de procesar un gran número de documentos de una colección haciéndolos pasar por distintas etapas. Las etapas constituyen lo que se conoce como "pipeline". Las etapas de un pipeline pueden filtrar, ordenar, agrupar, remodelar y modificar los documentos que pasan por el pipeline.
Uno de los usos más comunes de la agregación es calcular valores agregados para grupos de documentos. Esto es similar a la agregación básica disponible en SQL con la cláusula GROUP BY y las funciones COUNT, SUM y AVG. Sin embargo, MongoDB Aggregation va más allá y también puede realizar uniones de tipo relacional, remodelar documentos, crear nuevas colecciones y actualizar las existentes, etc.
Aunque existen otros métodos para obtener datos agregados en MongoDB, el marco de agregación es el enfoque recomendado para la mayoría de los trabajos.
Existe lo que se denomina métodos de propósito único como estimatedDocumentCount(), count()y distinct() que se añaden a un find() lo que las hace rápidas de usar pero limitadas en su alcance.
El framework map-reduce en MongoDB es un predecesor del framework de agregación y mucho más complejo de utilizar.
¿Cómo funciona el proceso de agregación de MongoDB?
A continuación se muestra un diagrama que ilustra un proceso de agregación típico de MongoDB.
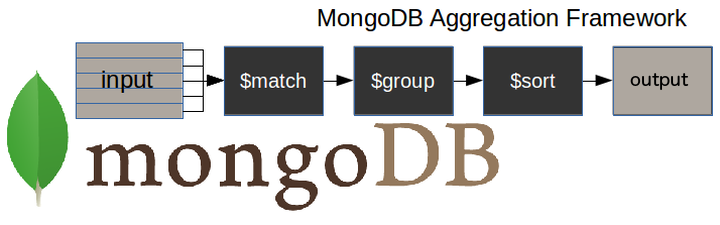
$matchetapa - filtra los documentos con los que necesitamos trabajar, los que se ajustan a nuestras necesidades$groupetapa - realiza el trabajo de agregación$sortetapa - ordena los documentos resultantes de la forma que deseemos (ascendente o descendente)
La entrada de la cadena puede ser una sola colección, en la que se pueden fusionar otras más adelante.
A continuación, la tubería realiza transformaciones sucesivas en los datos hasta alcanzar nuestro objetivo.
De este modo, podemos dividir una consulta compleja en etapas más sencillas, en cada una de las cuales completamos una operación diferente sobre los datos. Así, al final de la cadena de consultas, habremos conseguido todo lo que queríamos.
Este enfoque nos permite comprobar si nuestra consulta funciona correctamente en cada etapa examinando tanto su entrada como su salida. La salida de cada etapa será la entrada de la siguiente.

No hay límite en el número de etapas utilizadas en la consulta, ni en la forma de combinarlas.
Para conseguir un rendimiento óptimo de las consultas, hay que tener en cuenta una serie de buenas prácticas. Más adelante hablaremos de ellas.
Sintaxis de canalización agregada de MongoDB
Este es un ejemplo de cómo construir una consulta de agregación:
db.collectionName.aggregate(pipeline, options),
- donde collectionName - es el nombre de una colección,
- pipeline - es un array que contiene las etapas de agregación,
- options - parámetros opcionales para la agregación
Este es un ejemplo de la sintaxis del canal de agregación:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
Agregación de MongoDB etapa límites
La agregación funciona en memoria. Cada etapa puede utilizar hasta 100 MB de RAM. Recibirá un error de la base de datos si supera este límite.
Si se convierte en un problema inevitable puedes optar por paginar a disco, con la única desventaja de que esperarás un poco más porque es más lento trabajar en disco que en memoria. Para elegir el método page to disk, basta con configurar la opción allowDiskUse a la verdad así:
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
Tenga en cuenta que esta opción no siempre está disponible para los servicios compartidos. Por ejemplo, los clústeres Atlas M0, M2 y M5 desactivan esta opción.
Los documentos devueltos por la consulta de agregación, ya sea como cursor o almacenados mediante $out en otra colección, están limitados a 16MB. Es decir, no pueden ser mayores que el tamaño máximo de un documento de MongoDB.
Si es probable que supere este límite, deberá especificar que la salida de la consulta de agregación será en forma de cursor y no de documento.
Nuestros datos utilizados para los ejemplos agregados de MongoDB
Mostraré ejemplos de agregados MongoDB para las etapas más importantes del pipeline.
Para ilustrar los ejemplos, voy a utilizar dos colecciones. La primera se llama 'universities' y se compone de estos documentos (los datos no son reales):
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
Si desea probar estos ejemplos en su propia instalación, puede insertarlos con el siguiente comando masivo.
use 3tdb
db.universities.insertMany([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
])
La segunda y última colección se llaman 'courses' y tiene este aspecto:
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
}
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
}
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
De nuevo, puede insertarlos de la misma manera, utilizando el siguiente código:
db.courses.insertMany([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
])
Ejemplos de agregados en MongoDB
MongoDB $match
En $match etapa nos permite elegir sólo aquellos documentos de una colección con los que queremos trabajar. Para ello, filtra los que no cumplen nuestros requisitos.
En el siguiente ejemplo, sólo queremos trabajar con aquellos documentos en los que se especifique que Spain es el valor del campo countryy Salamanca es el valor del campo city.
Para obtener una salida legible, voy a añadir .pretty() al final de todos los comandos.
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
]).pretty()
La salida es...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain","city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
]
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdbaa"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "UPSA",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6691191,
17,
40.9631732
]
},
"students" : [
{
"year" : 2014,
"number" : 4788
},
{
"year" : 2015,
"number" : 4821
},
{
"year" : 2016,
"number" : 6550
},
{
"year" : 2017,
"number" : 6125
}
]
}
MongoDB $project
Es raro que necesite recuperar todos los campos de sus documentos. Es una buena práctica devolver sólo los campos que necesita para evitar procesar más datos de los necesarios.
En $project etapa se utiliza para hacer esto y para añadir cualquier campo calculado que necesite.
En este ejemplo, sólo necesitamos los campos country, cityy name.
En el código que sigue, ten en cuenta que:
- Debemos escribir explícitamente
_id : 0cuando este campo no es obligatorio - Aparte del
_idbasta con especificar únicamente los campos que necesitamos obtener como resultado de la consulta
Este etapa ...
db.universities.aggregate([
{ $project : { _id : 0, country : 1, city : 1, name : 1 } }
]).pretty()
.. dará el resultado ...
{ "country" : "Spain", "city" : "Salamanca", "name" : "USAL" }
{ "country" : "Spain", "city" : "Salamanca", "name" : "UPSA" }
MongoDB $group
Con el $group etapapodemos realizar todas las consultas de agregación o resumen que necesitemos, como encontrar recuentos, totales, medias o máximos.
En este ejemplo, queremos saber el número de documentos por universidad en nuestro 'universitiescolección:
La consulta ...
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } }
]).pretty()
..producirá este resultado...
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
Operadores de agregación $group de MongoDB
$group etapa admite determinadas expresiones (operadores) que permiten a los usuarios realizar operaciones aritméticas, array, booleanas y de otro tipo como parte de la cadena de agregación.
| Operador | Significado |
| $count | Calcula la cantidad de documentos del grupo dado. |
| $max | Muestra el valor máximo del campo de un documento en la colección. |
| $min | Muestra el valor mínimo de un campo del documento en la colección. |
| $avg | Muestra el valor medio del campo de un documento de la colección. |
| $suma | Suma los valores especificados de todos los documentos de la colección. |
| empujar | Añade valores adicionales en la dirección array del documento resultante. |
Consulte los operadores de MongoDB en y obtenga más información sobre otros operadores.
MongoDB $out
Se trata de un tipo de etapa poco habitual, ya que permite trasladar los resultados de la agregación a una nueva colección, o a una ya existente tras eliminarla, o incluso añadirlos a los documentos existentes.
En $out etapa debe ser el último etapa de la cadena.
Por primera vez, utilizamos una agregación con más de un etapa. Ahora tenemos dos, a $group y un $out:
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } },
{ $out : 'aggResults' }
])
Ahora, comprobamos el contenido del nuevo 'aggResultscolección:
db.aggResults.find().pretty()
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
Ahora que hemos producido una agregación multietapa , podemos pasar a construir una canalización.
MongoDB $unwind
En $unwind etapa en MongoDB se encuentra comúnmente en un pipeline porque es un medio para un fin.
No se puede trabajar directamente sobre los elementos de un array dentro de un documento con etapas como $group. En $unwind nos permite trabajar con los valores de los campos dentro de un array.
Si en los documentos de entrada hay un campo array , a veces tendrá que imprimir el documento varias veces, una por cada elemento de array.
En cada copia del documento se sustituye el campo array por el elemento sucesivo.
En el siguiente ejemplo, voy a aplicar el etapa sólo al documento cuyo campo name contiene el valor USAL.
Este es el documento:
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
Ahora, aplicamos el $unwind etapa, sobre el array del alumno, y comprobar que obtenemos un documento por cada elemento del array.
El primer documento está formado por los campos del primer elemento del array y el resto de campos comunes.
El segundo documento está formado por los campos del segundo elemento del array y el resto de campos comunes, y así sucesivamente.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
]).pretty()
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
MongoDB $sort
Necesita el $sort etapa para ordenar los resultados por el valor de un campo específico.
Por ejemplo, ordenemos los documentos obtenidos como resultado del $unwind etapa por número de alumnos en orden descendente.
Para obtener un resultado menor, voy a proyectar sólo el año y el número de alumnos.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
]).pretty()
Esto da el resultado ...
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
{ "students" : { "year" : 2016, "number" : 21913 } }
{ "students" : { "year" : 2017, "number" : 21715 } }
MongoDB $limit
¿Y si sólo le interesan los dos primeros resultados de su consulta? Es tan sencillo como
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } },
{ $limit : 2 }
]).pretty()
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
Tenga en cuenta que si necesita limitar el número de documentos ordenados, debe utilizar la opción $limit etapa sólo después de el $sort.
Ahora tenemos un pipeline lleno.
Podemos pegar toda esta consulta agregada de MongoDB y todas sus etapas directamente en el Editor de agregación de Studio 3T.
Sólo se copia y pega la parte que se muestra a continuación:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
])
Se pega copiándolo y pulsando el botón Pegar, como se muestra.
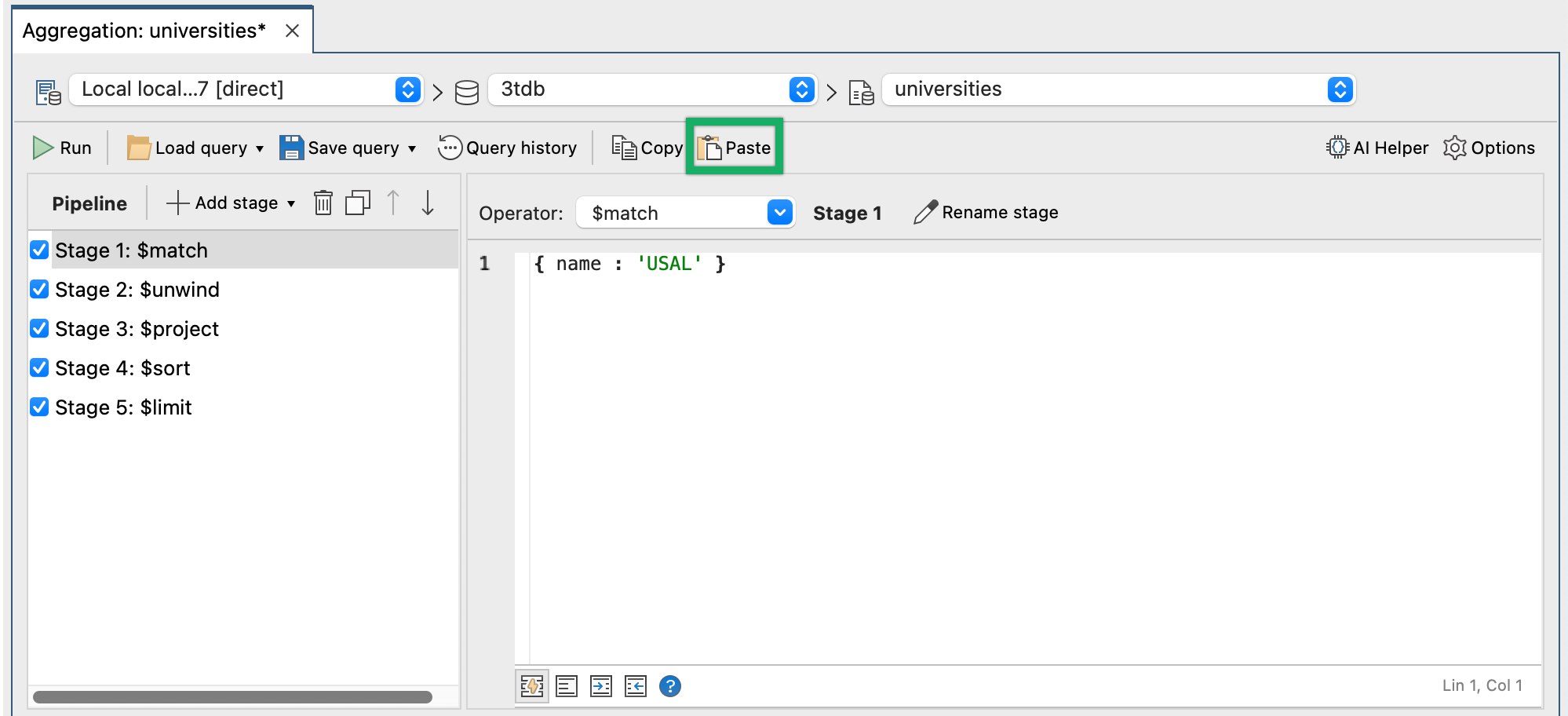
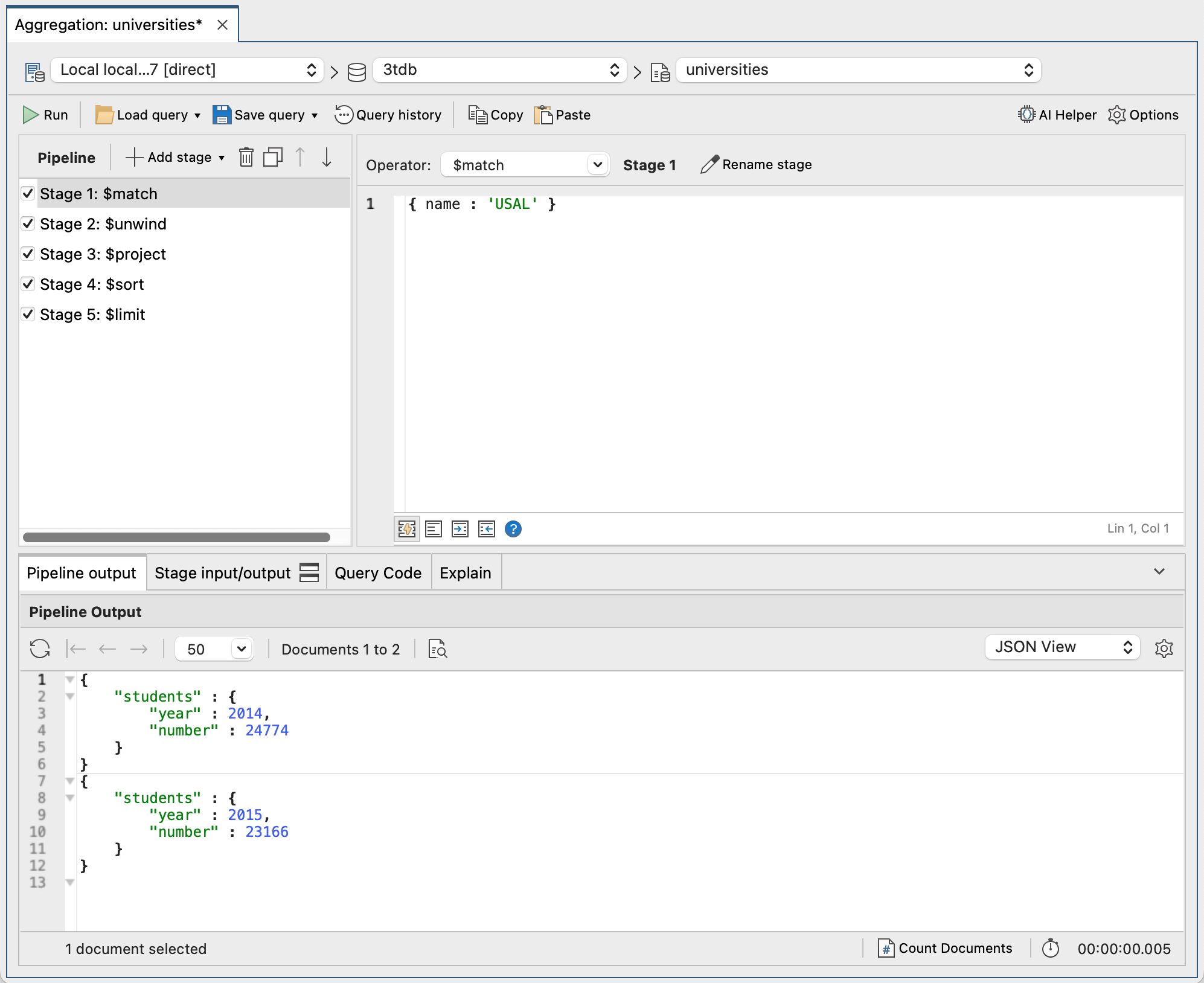
En la siguiente captura de pantalla, podemos ver el pipeline completo en Studio 3T y su salida.
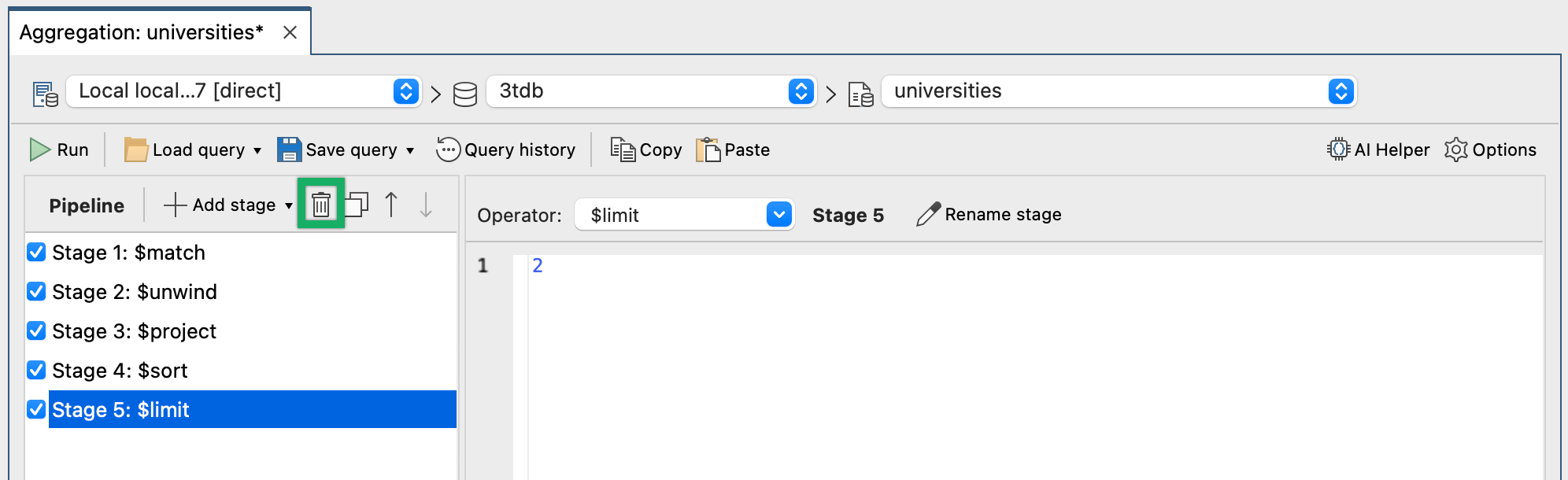
Eliminar etapas en Studio 3T es una simple cuestión de seleccionar la etapa y utilizar el botón que se muestra en la siguiente captura de pantalla.
$addFields
A veces puede que necesite realizar cambios en su salida en forma de nuevos campos. En el siguiente ejemplo, queremos añadir el año de fundación de la universidad.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $addFields : { foundation_year : 1218 } }
]).pretty()
Esto da el resultado ...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
],
"foundation_year" : 1218
}
MongoDB $count
En $count permite comprobar fácilmente el número de documentos obtenidos en la salida de las etapas anteriores del proceso.
Veámoslo en acción:
db.universities.aggregate([
{ $unwind : '$students' },
{ $count : 'total_documents' }
]).pretty()
Así se obtiene el total de los años de los que se conoce el número de estudiantes de la Universidad.
{ "total_documents" : 8 }
MongoDB $lookup
Dado que MongoDB se basa en documentos, podemos darles la forma que necesitemos. Sin embargo, a menudo es necesario utilizar información de más de una colección.
Utilización de $lookupA continuación se muestra una consulta agregada que combina campos de dos colecciones.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $project : { _id : 0, name : 1 } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} }
]).pretty()
Si desea que esta consulta se ejecute rápidamente, necesitará indexar el archivo name en el campo universities y la university en el campo courses colección.
En otras palabras, no se olvide de índice los campos implicados en la $lookup.
{
"name" : "USAL",
"courses" : [
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbab"),
"university" : "USAL",
"name" : "Computer Science",
"level" : "Excellent"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbac"),
"university" : "USAL",
"name" : "Electronics",
"level" : "Intermediate"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbad"),
"university" : "USAL",
"name" : "Communication",
"level" : "Excellent"
}
]
}
MongoDB $sortByCount
Este etapa es un atajo para agrupar, contar y luego ordenar en orden descendente el número de valores diferentes de un campo.
Supongamos que desea conocer el número de cursos por nivel, ordenados de forma descendente. La siguiente es la consulta que tendría que construir:
db.courses.aggregate([
{ $sortByCount : '$level' }
]).pretty()
Este es el resultado:
{ "_id" : "Excellent", "count" : 2 }
{ "_id" : "Intermediate", "count" : 1 }
MongoDB $facet
A veces, al crear un informe sobre datos, uno se encuentra con que necesita hacer el mismo tratamiento preliminar para varios informes, y se enfrenta a tener que crear y mantener una colección intermedia.
Puede, por ejemplo, hacer un resumen semanal de la negociación que sea utilizado por todos los informes posteriores. Tal vez haya deseado que fuera posible ejecutar más de un pipeline simultáneamente sobre la salida de un único pipeline de agregación.
Ahora podemos hacerlo dentro de una única canalización gracias a la función $facet etapa.
Mira este ejemplo:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} },
{ $facet : {
'countingLevels' :
[
{ $unwind : '$courses' },
{ $sortByCount : '$courses.level' }
],
'yearWithLessStudents' :
[
{ $unwind : '$students' },
{ $project : { _id : 0, students : 1 } },
{ $sort : { 'students.number' : 1 } },
{ $limit : 1 }
]
} }
]).pretty()
Lo que hemos hecho es crear dos informes a partir de nuestra base de datos de cursos universitarios: countingLevels y yearWithLessStudents.
Ambas utilizaban la salida de las dos primeras etapas, el $match y el $lookup.
Con una colección grande, esto puede ahorrar una gran cantidad de tiempo de procesamiento al evitar la repetición, y ya no necesitamos escribir una colección temporal intermedia.
{
"countingLevels" : [
{
"_id" : "Excellent",
"count" : 2
},
{
"_id" : "Intermediate",
"count" : 1
}
],
"yearWithLessStudents" : [
{
"students" : {
"year" : 2017,
"number" : 21715
}
}
]
}
Ejercicio
Ahora, intenta resolver el siguiente ejercicio por ti mismo.
¿Cómo obtenemos el número total de estudiantes que han pertenecido alguna vez a cada una de las universidades?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } }
]).pretty()
La salida:
{ "_id" : "UPSA", "totalalumni" : 22284 }
{ "_id" : "USAL", "totalalumni" : 91568 }
Sí, he combinado dos etapas. Pero, ¿cómo construir una consulta que ordena la salida por el totalalumni en orden descendente?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } },
{ $sort : { totalalumni : -1 } }
]).pretty()
Bien, tenemos que aplicar el $sort() etapa a la salida del $group().
Comprobación de nuestra consulta de agregación
Antes he mencionado que es muy fácil, y de hecho esencial, comprobar que las etapas de nuestra consulta funcionan como necesitamos que funcionen.
Con Studio 3T, dispone de dos paneles dedicados para comprobar los documentos de entrada y salida de cualquier etapa.
Rendimiento
El proceso de agregación modifica automáticamente la consulta para mejorar su rendimiento.
Si tiene ambos $sort y $match etapas, siempre es mejor utilizar $match antes del $sort para minimizar el número de documentos que el $sort etapa tiene que lidiar.
Para aprovechar las ventajas de los índices, debes hacerlo en la primera etapa de tu pipeline. Y aquí, usted debe utilizar el $match o el $sort etapas.
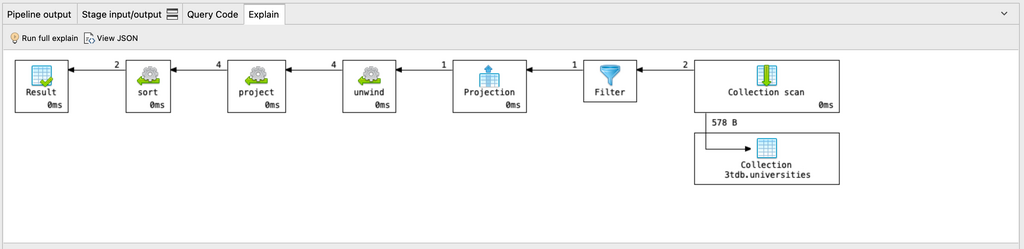
Podemos comprobar si la consulta está utilizando un índice mediante la función explain() método.
pipeline = [...]
db.<collectionName>.aggregate( pipeline, { explain : true })
Siempre puede consultar el explain() plan de cualquier consulta de agregación como diagrama o en JSON haciendo clic en la pestaña Explicar.
Conclusión
He introducido el pipeline de agregación de MongoDB y he demostrado con ejemplos cómo utilizar sólo algunas etapas.
Cuanto más utilice MongoDB, más importante será la canalización de agregación para permitirle realizar todas esas tareas de generación de informes, transformación y consultas avanzadas que son tan esenciales para el trabajo de un desarrollador de bases de datos.
Con los procesos pipeline más complejos, cada vez es más importante comprobar y depurar la entrada y la salida de cada etapa.
Siempre hay un punto en el que necesitas pegar el pipeline de agregación creciente en un IDE para MongoDB como Studio 3T, con un Editor de Agregación incorporado, para que puedas depurar cada etapa independientemente.







