
MongoDB로 작업을 시작할 경우, 일반적으로 다음을 사용합니다. find() 광범위한 쿼리를 수행하는 명령입니다. 그러나 쿼리가 더 고급화되면 MongoDB 집계 에 대해 더 많이 알아야 합니다.
이 글에서는 MongoDB에서 집계 쿼리를 작성하는 주요 원칙과 인덱스를 활용하여 쿼리 속도를 높이는 방법에 대해 설명합니다.
또한 집계 파이프라인의 가장 중요한 단계를, 각 단계를 사용한 간단한 예제 및 파이프라인에 적용하는 방법과 함께 소개합니다.

MongoDB에서 집계란 무엇인가요?
집계 는 컬렉션에 있는 방대한 양의 문서를 여러 단계를 거쳐 처리하는 방법입니다. 이런 단계들이 일명 '파이프라인'이라고 하는 것을 만듭니다. 파이프라인의 각 단계는 파이프라인을 통과하는 문서를 필터링, 정렬, 그룹화, 모양 변경 및 수정합니다.
가장 일반적인 집계 사용 사례 중 하나는 문서 그룹에 대한 집계 값을 계산하는 것입니다. 이는 GROUP BY 절과 COUNT, SUM, AVG 함수를 사용하는 SQL의 기본 집계 유사합니다. 하지만 MongoDB 집계 여기서 더 나아가 관계형 조인, 문서 재구성, 새 컬렉션 생성 및 기존 컬렉션 업데이트 등을 수행할 수도 있습니다.
MongoDB에서 집계 데이터를 얻는 다른 방법도 있지만, 대부분의 작업에는 집계 프레임워크로 접근하는 것을 권장합니다.
다음으로 불리우는 것들입니다. 단일 목적 메서드 예 estimatedDocumentCount(), count()및 distinct() 다음에 추가됩니다. find() 쿼리를 사용하면 빠르게 사용할 수 있지만 범위가 제한됩니다.
MongoDB 맵 축소 프레임워크는 집계 프레임워크의 전신으로, 사용하기가 훨씬 더 복잡합니다.
MongoDB 집계 파이프라인은 어떻게 작동하나요?
다음은 전형적인 MongoDB 집계 파이프라인을 보여주는 그림입니다.
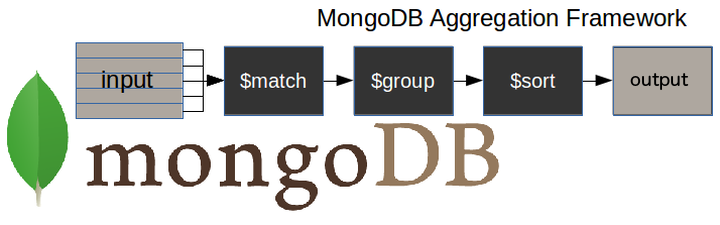
$match단계 - 작업해야 할 문서, 필요에 맞는 문서를 필터링합니다.$group단계 - 집계 작업을 수행합니다.$sort단계 - 결과 문서를 필요한 방식(오름차순 또는 내림차순)으로 정렬합니다.
파이프라인의 입력은 단일 컬렉션일 수 있으며, 다른 컬렉션은 나중에 파이프라인을 따라 병합할 수 있습니다.
그런 다음 파이프라인은 목표가 달성될 때까지 데이터에 대한 연속적인 변환을 수행합니다.
이렇게 하면 복잡한 쿼리를 더 쉬운 단계로 나눌 수 있으며, 각 단계마다 데이터에 대해 다른 작업을 완료할 수 있습니다. 따라서 쿼리 파이프라인이 끝날 때쯤이면 원하는 모든 것을 달성할 수 있습니다.
이 접근 방식을 사용하면 쿼리의 입력과 출력을 모두 검사하여 모든 단계 쿼리가 제대로 작동하는지 확인할 수 있습니다. 각 단계 출력은 다음 단계의 입력이 됩니다.

쿼리에 사용되는 단계 수나 단계를 결합하는 방법에는 제한이 없습니다.
최적의 쿼리 성능을 달성하기 위해 고려해야 할 여러 가지 모범 사례가 있습니다. 이 글의 뒷부분에서 이에 대해 설명하겠습니다.
MongoDB 집계 파이프라인 구문
다음은 집계 쿼리를 작성하는 방법의 예입니다:
db.collectionName.aggregate(pipeline, options),
- collectionName - 컬렉션의 이름입니다,
- 파이프라인 - 집계 단계가 포함된 배열입니다,
- 옵션 - 선택적 매개변수 집계
다음은 집계 파이프라인 구문의 예입니다:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
MongoDB 집계 단계 제한
집계는 메모리에서 작동합니다. 각 단계는 최대 100MB의 RAM을 사용할 수 있습니다. 이 제한을 초과하면 데이터베이스에서 오류가 발생합니다.
피할 수 없는 문제가 발생하면 '디스크로 페이지'를 선택할 수 있지만, 메모리보다 디스크에서 작업하는 속도가 느리기 때문에 조금 더 오래 기다린다는 단점이 있습니다. '디스크로 페이지'하는 방법을 선택하려면 다음 옵션을 설정하기만 하면 됩니다. allowDiskUse 이렇게 참으로 설정합니다:
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
공유 서비스에서 이 옵션을 항상 사용할 수 있는 것은 아닙니다. 예를 들어 Atlas M0, M2 및 M5 클러스터는 이 옵션을 비활성화합니다.
집계 쿼리에서 반환된 문서는 커서 형태로 저장되거나 다음을 통해 저장됩니다. $out 다른 컬렉션에서는 16MB로 제한됩니다. 즉, MongoDB 문서의 최대 크기보다 더 클 수 없습니다.
이 제한을 초과할 가능성이 있는 경우, 집계 쿼리의 출력이 문서가 아닌 커서가 되도록 지정해야 합니다.
MongoDB 집계 예제에 사용된 데이터는 다음과 같습니다.
가장 중요한 파이프라인 단계에 대한 MongoDB 집계 예제를 보여드리겠습니다.
예제를 설명하기 위해 두 가지 컬렉션을 사용하겠습니다. 첫 번째는 다음으로 불립니다. 'universities' 이 문서로 구성되어 있습니다(데이터는 실제가 아님):
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
자체 설치에서 이러한 예제를 테스트하려면 아래의 대량 명령어를 사용하여 삽입할 수 있습니다.
use 3tdb
db.universities.insertMany([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
])
두 번째이자 마지막 컬렉션은 다음으로 불립니다. 'courses' 다음과 같이 표시됩니다:
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
}
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
}
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
다음 코드를 사용하여 같은 방법으로 삽입할 수 있습니다:
db.courses.insertMany([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
])
MongoDB 집계 예제
MongoDB $match
$match 단계를 사용하면 컬렉션에서 작업할 문서만 선택할 수 있습니다. 요구 사항을 따르지 않는 문서를 필터링하여 이를 수행합니다.
다음 예제에서는 다음을 명시하는 문서로만 작업하려고 합니다. Spain 필드의 값입니다. country및 Salamanca 필드의 값입니다. city.
가독성 있는 출력을 얻기 위해 다음과 같이 추가하겠습니다. .pretty() 모든 명령의 끝에 입력합니다.
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
]).pretty()
출력은 다음과 같습니다.
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain","city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
]
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdbaa"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "UPSA",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6691191,
17,
40.9631732
]
},
"students" : [
{
"year" : 2014,
"number" : 4788
},
{
"year" : 2015,
"number" : 4821
},
{
"year" : 2016,
"number" : 6550
},
{
"year" : 2017,
"number" : 6125
}
]
}
MongoDB $project
문서에 있는 모든 필드를 검색해야 하는 경우는 거의 없습니다. 필요 이상의 데이터를 처리하지 않도록 필요한 필드만 반환하는 것이 좋습니다.
$project 단계를 사용하여 이 작업을 수행하고 필요한 계산된 필드를 추가합니다.
이 예제에서는 다음과 같은 필드만 필요합니다. country, city및 name.
다음 코드에서는 다음 사항에 유의하세요:
- 다음과 같이 명시적으로 작성해야 합니다.
_id : 0이 필드가 필수가 아닌 경우 - 다음 이외
_id필드를 사용하는 경우 쿼리 결과로 가져와야 하는 필드만 지정하면 충분합니다.
이 단계 ...
db.universities.aggregate([
{ $project : { _id : 0, country : 1, city : 1, name : 1 } }
]).pretty()
다음의 결과가 나옵니다.
{ "country" : "Spain", "city" : "Salamanca", "name" : "USAL" }
{ "country" : "Spain", "city" : "Salamanca", "name" : "UPSA" }
MongoDB $group
와 $group 단계를 사용하여 개수, 합계, 평균 또는 최대값 찾기와 같이 필요한 모든 집계 또는 요약 쿼리를 수행할 수 있습니다.
이 예에서는 해당 대학에 있는 문서의 수를 알고 싶어합니다.universities:
쿼리 ...
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } }
]).pretty()
이 결과가 나왔습니다.
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
MongoDB $group 집계 연산자
$group 단계는 특정 표현식(연산자)을 지원하여 사용자가 집계 파이프라인의 일부로 산수, 배열, 부울 및 기타 연산을 수행할 수 있습니다.
| 연산자 | 의미 |
| $count | 지정된 그룹에 있는 문서의 양을 계산합니다. |
| $max | 컬렉션에 있는 문서 필드의 최대값을 표시합니다. |
| $min | 컬렉션에 있는 문서 필드의 최소값을 표시합니다. |
| $avg | 컬렉션에 있는 문서 필드의 평균값을 표시합니다. |
| $sum | 컬렉션에 있는 모든 문서의 지정된 값을 합산합니다. |
| $push | 결과 문서의 배열에 다른 값들을 추가합니다. |
MongoDB 운영자 에서 다른 운영자에 대해 자세히 알아보세요.
MongoDB $out
이 단계 집계 결과를 새 컬렉션으로 옮기거나 기존 컬렉션을 삭제한 후 기존 컬렉션으로 옮기거나 기존 문서에 추가할 수 있기 때문에 특이한 유형의 단계 .
$out 단계는 파이프라인에서 마지막 단계이어야 합니다.
처음으로 두 개 이상의 단계가 있는 집계를 사용하고 있습니다. 이제 다음의 두 개가 있습니다. $group 및 $out:
db.universities.aggregate([
{ $group : { _id : '$name', totaldocs : { $sum : 1 } } },
{ $out : 'aggResults' }
])
이제 새로운 컬렉션의 내용을 확인해 보겠습니다.aggResults:
db.aggResults.find().pretty()
{ "_id" : "UPSA", "totaldocs" : 1 }
{ "_id" : "USAL", "totaldocs" : 1 }
이제 여러 단계가 있는 집계를 만들었으니 파이프라인을 구축할 수 있습니다.
MongoDB $unwind
$unwind 단계는 MongoDB에서 끝을 위한 방법이기 때문에 파이프라인에서 흔히 볼 수 있습니다.
다음과 같은 단계가 있는 문서 내 배열 요소에서는 직접 작업할 수 없습니다. $group. $unwind 단계를 사용하면 배열 내의 필드 값으로 작업할 수 있습니다.
입력 문서 내에 배열 필드가 있는 경우 해당 배열의 모든 요소에 대해 한 번씩 문서를 여러 번 출력해야 하는 경우가 있습니다.
문서의 각 사본에는 연속 요소로 대체된 배열 필드가 있습니다.
다음 예제에서는 해당 단계가 특정 필드가 있는 문서에만 적용하도록 해보겠습니다. name 다음 값이 포함되어 있습니다. USAL.
문서입니다:
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
이제 다음을 적용합니다. $unwind 단계 이동하여 학생의 배열을 살펴보고 배열의 각 요소에 대한 문서가 표시되는지 확인합니다.
첫 번째 문서는 배열의 첫 번째 요소에 있는 필드와 나머지 공통 필드로 구성됩니다.
두 번째 문서는 배열의 두 번째 요소에 있는 필드와 나머지 공통 필드 등으로 구성됩니다.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
]).pretty()
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
MongoDB $sort
다음이 필요합니다. $sort 단계를 사용하여 특정 필드의 값을 기준으로 결과를 정렬할 수 있습니다.
예를 들어, 다음의 결과로 얻은 문서를 정렬해 보겠습니다. $unwind 단계를 학생 수에 따라 내림차순으로 정렬합니다.
출력 줄이기 위해 연도와 학생 수만 도출해 보겠습니다.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
]).pretty()
결과를 제공합니다 ...
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
{ "students" : { "year" : 2016, "number" : 21913 } }
{ "students" : { "year" : 2017, "number" : 21715 } }
MongoDB $limit
쿼리의 처음 두 결과에만 관심이 있다면 어떻게 해야 하나요? 간단합니다:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } },
{ $limit : 2 }
]).pretty()
{ "students" : { "year" : 2014, "number" : 24774 } }
{ "students" : { "year" : 2015, "number" : 23166 } }
정렬된 문서의 수를 제한해야 할 경우 다음을 사용해야 합니다. $limit 단계 이후 $sort.
이제 전체 파이프라인이 완성되었습니다.
이 전체 MongoDB 집계 쿼리와 모든 단계를 Studio 3T 집계 편집기 바로 붙여넣을 수 있습니다.
아래 표시된 부분만 복사하여 붙여넣습니다:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $sort : { 'students.number' : -1 } }
])
그림과 같이 복사한 후 붙여넣기 버튼 클릭하여 붙여넣습니다.
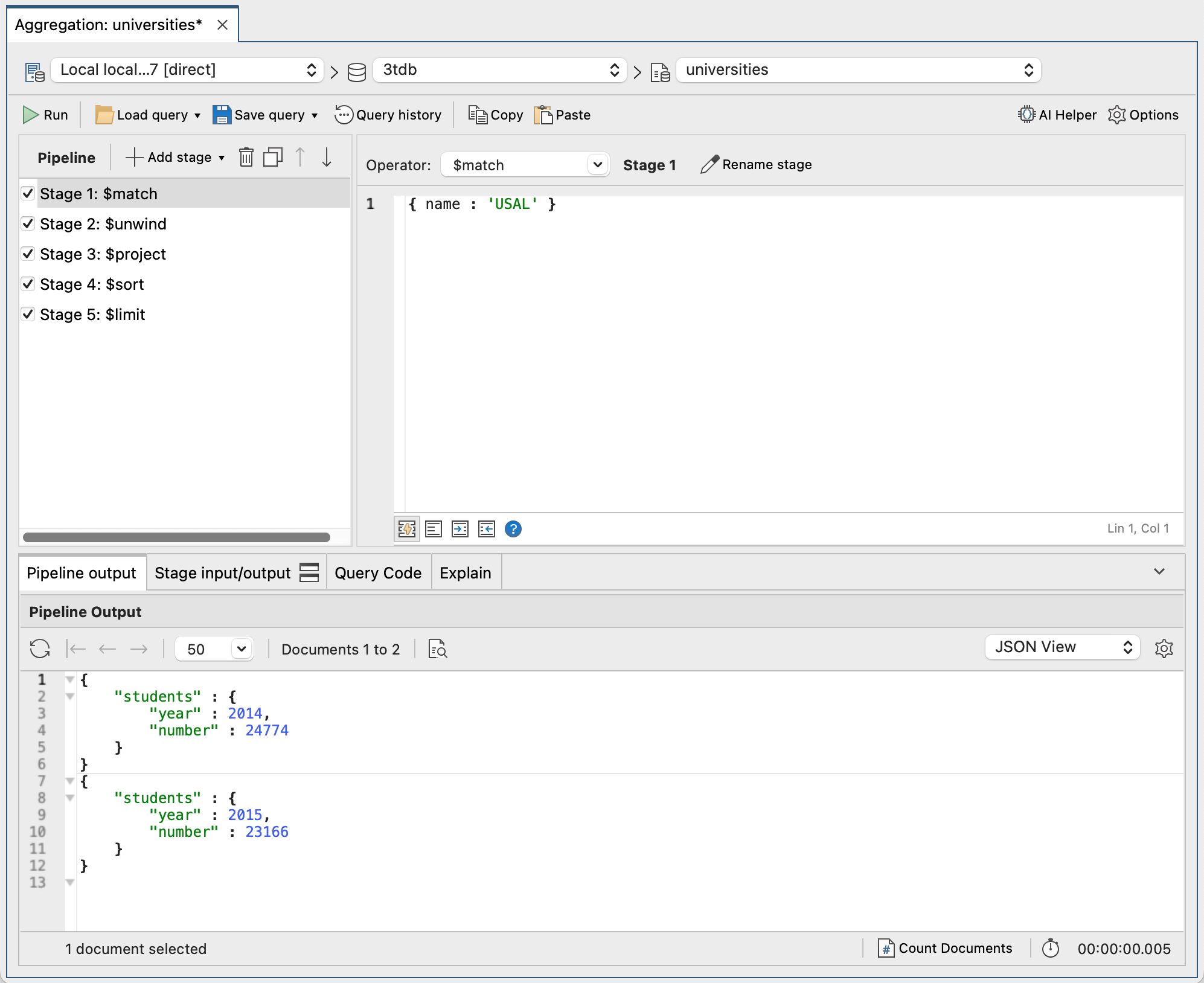
다음 스크린샷에서는 Studio 3T의 전체 파이프라인과 그 출력을 확인할 수 있습니다.
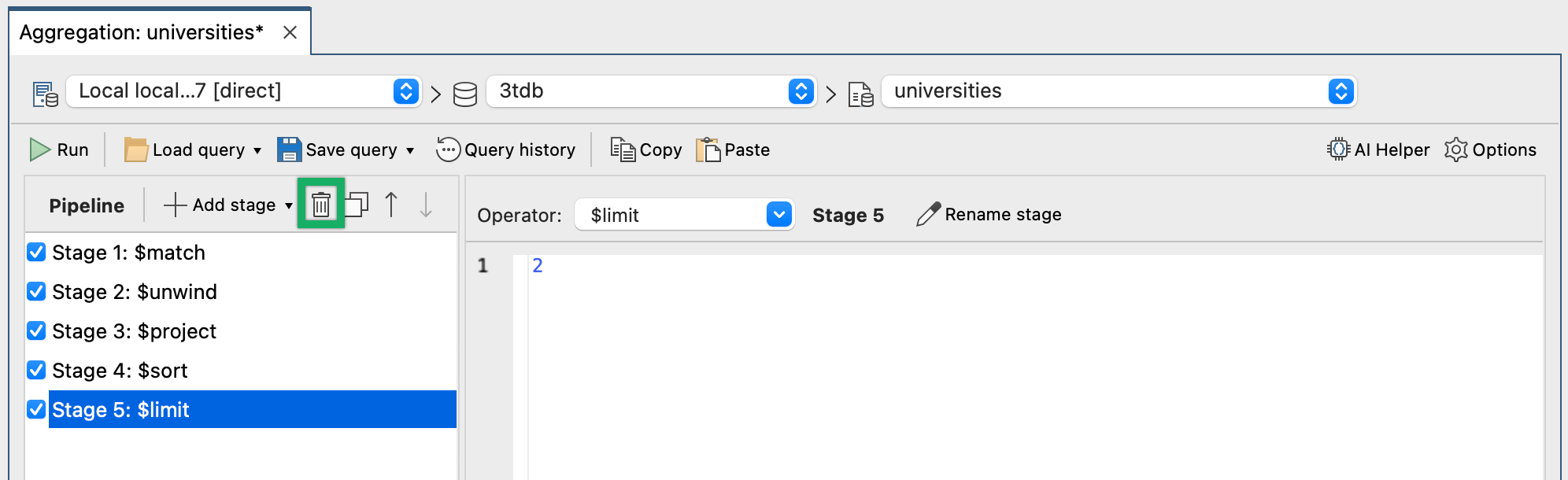
Studio 3T 스테이지를 제거하려면 단계 선택하고 다음 스크린샷에 표시된 버튼 사용하기만 하면 됩니다.
$addFields
때로는 새로운 필드를 추가하는 방식으로 출력을 변경해야 할 수도 있습니다. 다음 예에서는 대학 설립 연도를 추가하려고 합니다.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $addFields : { foundation_year : 1218 } }
]).pretty()
결과를 제공합니다 ...
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : [
{
"year" : 2014,
"number" : 24774
},
{
"year" : 2015,
"number" : 23166
},
{
"year" : 2016,
"number" : 21913
},
{
"year" : 2017,
"number" : 21715
}
],
"foundation_year" : 1218
}
MongoDB $count
$count 단계는 파이프라인의 이전 단계 출력에 있는 문서 수를 쉽게 확인할 수 있는 방법을 제공합니다.
실제로 확인해 보겠습니다:
db.universities.aggregate([
{ $unwind : '$students' },
{ $count : 'total_documents' }
]).pretty()
이는 대학의 재학생 수를 알고 있는 연도의 총계를 제공합니다.
{ "total_documents" : 8 }
MongoDB $lookup
MongoDB는 문서 기반이므로 필요한 방식으로 문서를 구성할 수 있습니다. 하지만 둘 이상의 컬렉션에 있는 정보를 사용해야 하는 경우가 종종 있습니다.
다음 사용 $lookup두 컬렉션의 필드를 병합하는 집계 쿼리입니다.
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $project : { _id : 0, name : 1 } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} }
]).pretty()
이 쿼리가 빠르게 실행되도록 하려면 다음을 인덱스해야 합니다. name 다음에 있는 필드 universities 컬렉션 및 university 다음에 있는 필드 courses collection.
즉 다음에 포함된 필드를 인덱스하는 것을 잊지 마세요. $lookup.
{
"name" : "USAL",
"courses" : [
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbab"),
"university" : "USAL",
"name" : "Computer Science",
"level" : "Excellent"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbac"),
"university" : "USAL",
"name" : "Electronics",
"level" : "Intermediate"
},
{
"_id" : ObjectId("5b7d9ea5fbc9884f689cdbad"),
"university" : "USAL",
"name" : "Communication",
"level" : "Excellent"
}
]
}
MongoDB $sortByCount
이 단계는 필드에 있는 여러 값의 수를 그룹화하여 계산한 다음 내림차순으로 정렬하는 바로 가기입니다.
내림차순으로 정렬된 레벨별 코스 수를 알고 싶다고 가정해 보겠습니다. 다음은 작성해야 하는 쿼리입니다:
db.courses.aggregate([
{ $sortByCount : '$level' }
]).pretty()
출력입니다:
{ "_id" : "Excellent", "count" : 2 }
{ "_id" : "Intermediate", "count" : 1 }
MongoDB $facet
데이터에 대한 보고서를 만들 때 여러 보고서에 대해 동일한 예비 처리를 수행해야 하고 중간 컬렉션을 만들고 유지 관리해야 하는 상황에 직면하는 경우가 있습니다.
예를 들어 모든 후속 보고서에서 사용되는 주간 거래 요약을 작성할 수 있습니다. 하나의 집계 파이프라인 출력에 대해 둘 이상의 파이프라인을 동시에 실행할 수 있으면 좋겠다고 생각할지도 모릅니다.
이제 단일 파이프라인 내에서 작업을 수행할 수 있습니다. $facet stage.
이 예를 살펴보세요:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $lookup : {
from : 'courses',
localField : 'name',
foreignField : 'university',
as : 'courses'
} },
{ $facet : {
'countingLevels' :
[
{ $unwind : '$courses' },
{ $sortByCount : '$courses.level' }
],
'yearWithLessStudents' :
[
{ $unwind : '$students' },
{ $project : { _id : 0, students : 1 } },
{ $sort : { 'students.number' : 1 } },
{ $limit : 1 }
]
} }
]).pretty()
대학 과정 데이터베이스에서 카운팅 레벨과 학년별 학생 수라는 두 가지 보고서를 만들었습니다.
모두 처음 두 단계의 출력을 사용했습니다. $match 및 $lookup.
대규모 컬렉션의 경우 반복을 방지하여 처리 시간을 크게 절약할 수 있으며, 더 이상 중간 임시 컬렉션을 작성할 필요가 없습니다.
{
"countingLevels" : [
{
"_id" : "Excellent",
"count" : 2
},
{
"_id" : "Intermediate",
"count" : 1
}
],
"yearWithLessStudents" : [
{
"students" : {
"year" : 2017,
"number" : 21715
}
}
]
}
연습
이제 다음 연습 문제를 혼자서 해결해 보세요.
각 대학에 소속된 총 학생 수는 어떻게 구할까요?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } }
]).pretty()
출력:
{ "_id" : "UPSA", "totalalumni" : 22284 }
{ "_id" : "USAL", "totalalumni" : 91568 }
예, 두 단계를 결합했습니다. 하지만 다음을 기준으로 출력을 정렬하는 쿼리를 작성하려면 어떻게 해야 하나요? totalalumni 필드가 내림차순입니까?
db.universities.aggregate([
{ $unwind : '$students' },
{ $group : { _id : '$name', totalalumni : { $sum : '$students.number' } } },
{ $sort : { totalalumni : -1 } }
]).pretty()
다음을 적용해야 합니다. $sort() 다음 출력의 단계 $group().
집계 쿼리 확인
앞서 쿼리 단계가 필요한 방식으로 수행되고 있는지 확인하는 것은 매우 쉽고 실제로 필수적이라고 말씀드렸습니다.
Studio 3T에는 특정 단계의 입력 및 출력 문서를 확인 할 수 있는 두 개의 전용 패널이 있습니다.
성능
집계 파이프라인은 성능 향상을 목표로 쿼리를 자동으로 재구성합니다.
두 가지 모두 있는 경우 $sort 및 $match 단계. 다음을 사용하는 것이 좋습니다. $match 이전 $sort 문서 수를 최소화하기 위해 $sort 단계는 처리되어야 합니다.
인덱스를 활용하려면 파이프라인의 첫 번째 단계에서 해야 합니다. 그리고 여기에서 다음을 사용해야 합니다. $match 또는 $sort 단계.
다음을 통해 쿼리가 인덱스를 사용하는지 여부를 확인할 수 있습니다. explain() method.
pipeline = [...]
db.<collectionName>.aggregate( pipeline, { explain : true })
언제든지 다음을 검토할 수 있습니다. explain() Explain 탭을 클릭하여 집계 쿼리의 계획을 다이어그램 또는 JSON으로 표시합니다.
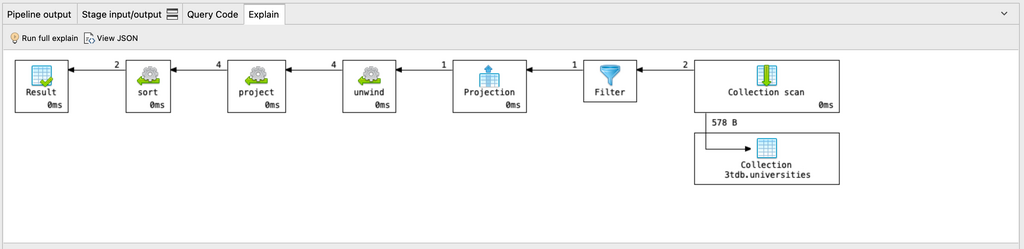
결론
MongoDB 집계 파이프라인을 소개하고 일부 단계만 사용하는 방법을 예제를 통해 시연해 보았습니다.
MongoDB를 많이 사용할수록, 데이터베이스 개발자의 업무에 필수적인 보고, 변환 및 고급 쿼리 작업을 모두 수행하는 집계 파이프라인이 더 중요해집니다.
파이프라인 프로세스가 더욱 복잡해짐에 따라 모든 단계의 입력 및 출력을 확인하고 디버깅하는 것이 점점 더 중요해집니다.
모든 단계 독립적으로 디버깅할 수 있도록 집계 편집기 내장된 Studio 3T 같은 MongoDB IDE에 증가하는 집계 파이프라인을 붙여넣어야 하는 시점이 항상 존재합니다.







