
¿Quieres saber la forma más rápida de averiguar qué índices tienes en una colección o crear nuevos fácilmente? Prueba el administrador índice , donde puedes ocultar y mostrar índices con un solo clic, eliminando la espera a que se reconstruyan. Consulta rápidamente la frecuencia con la que se usan tus índices. Incluso puedes obtener una comparación de índices en diferentes bases de datos.

¿Qué son los índices en MongoDB y por qué los necesitamos?
Los índices hacen que la consulta de datos sea más eficiente. Sin índices, MongoDB realiza una exploración de la colección que lee todos los documentos de la colección para determinar si los datos coinciden con las condiciones especificadas en la consulta. Los índices limitan el número de documentos que MongoDB lee y con los índices adecuados se puede mejorar el rendimiento. Los índices almacenan el valor de un campo o un conjunto de campos, ordenados por el valor del campo.
Mostrando el índice Gerente
Para ver los índices de una colección, localícela en el árbol de conexión y expándala. Puede expandir la sección Índices para ver los... índice nombres:
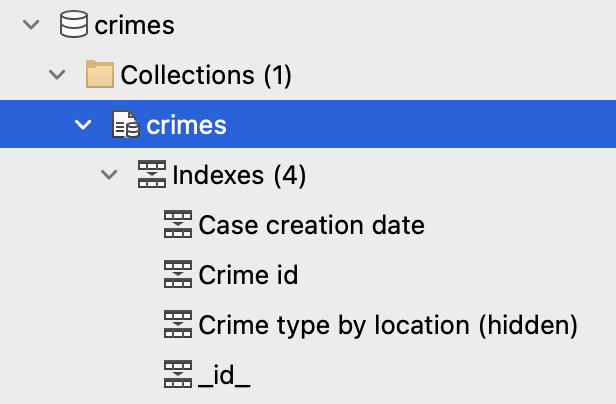
Para visualizar el índice Administrador, haga doble clic en la entrada Índices en la parte superior de la sección índices.
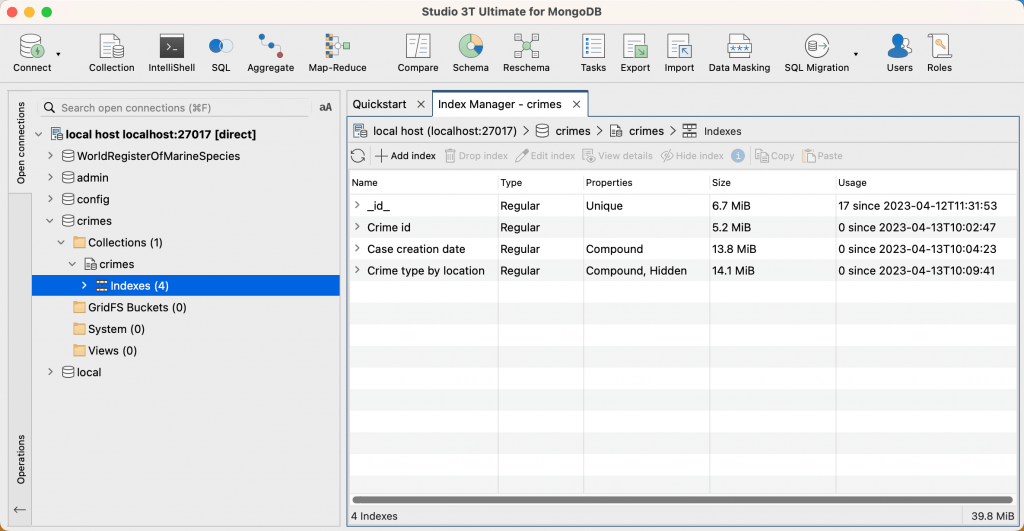
El índice El administrador muestra una lista de todos los índices de la colección:
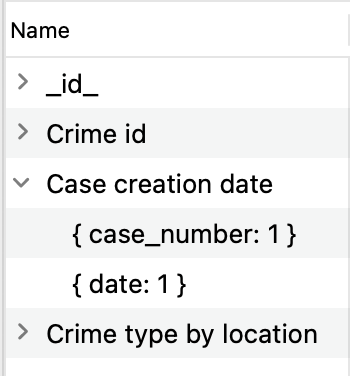
Para ver los campos de 인덱싱된 y su orden de clasificación, haga clic en la flecha del campo Nombre:
índice tamaño
Para obtener el mejor rendimiento, asegúrese de que todos los índices de todas sus colecciones quepan en la RAM de su servidor MongoDB para evitar leerlos desde el disco. En algunos casos, los índices solo almacenan valores recientes en la RAM; para más información, consulte la documentación de MongoDB . El campo Tamaño muestra el tamaño de cada índice. índice en la colección seleccionada. El total índice El tamaño (suma de todos los índices) de la colección se muestra en la esquina inferior derecha de la índice Gerente.
índice uso
El uso te muestra cuántas veces un índice Se ha utilizado desde la índice fue creado o desde la última vez que se reinició el servidor.
índice El administrador muestra información de uso solo si el usuario tiene privilegios para el comando $indexStats de MongoDB. Para obtener más información sobre índice estadísticas, consulte la documentación de MongoDB .
Si un índice No se utiliza, debe eliminarlo para eliminar los gastos generales asociados con el mantenimiento del índice cuando se actualizan los valores de campo y el espacio en disco.
Añadiendo un índice
En el árbol de conexión, haga clic con el botón derecho en una colección y luego seleccione Agregar índice .
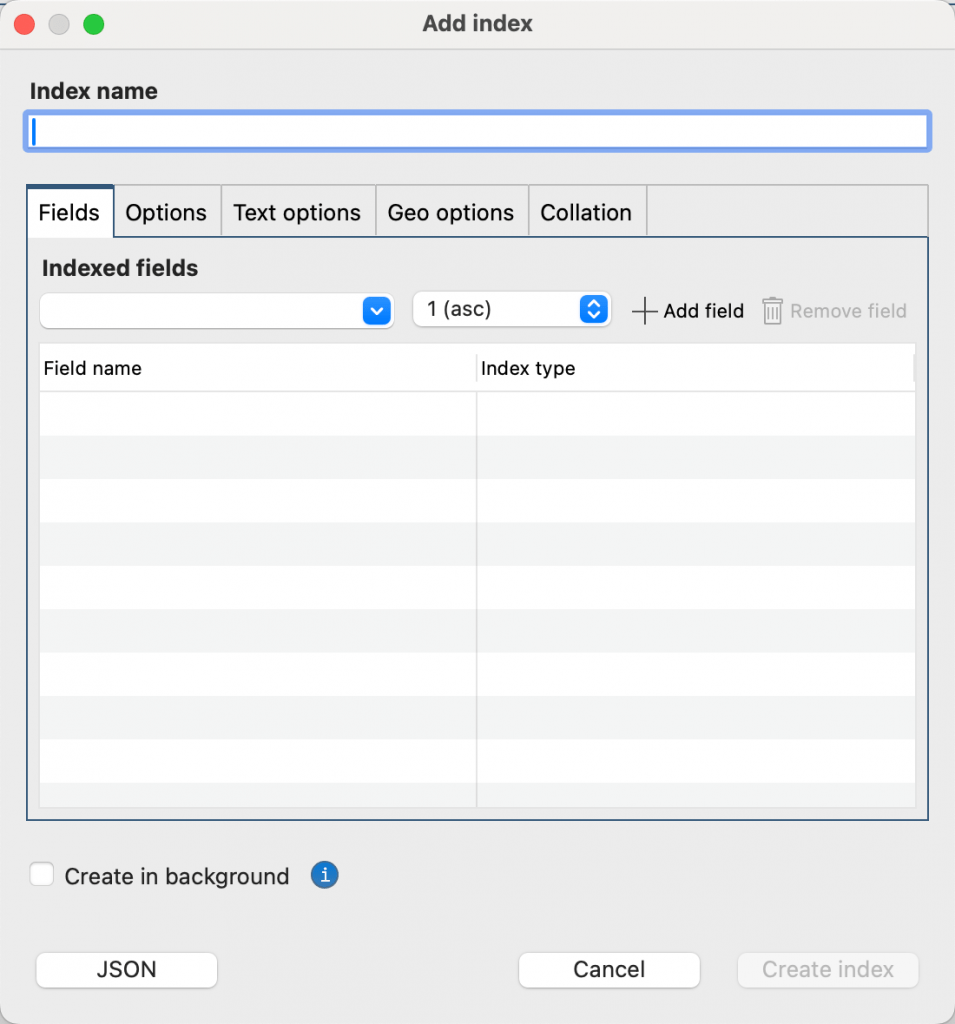
En el cuadro de diálogo Agregar índice , escriba el nombre de su índice en el cuadro de nombre índice . Si deja el cuadro de nombre índice vacío, Studio 3T crea un valor predeterminado índice nombre para usted, en función de los nombres de los campos que seleccione y el índice tipo.
Añade los campos obligatorios a tu índice Para ello, seleccione el campo de la lista Campos indexados , luego seleccione el orden de clasificación (1 ascendente o -1 descendente) o el tipo de índice . Para saber más sobre índice Tipos y propiedades, consulte Tipos índice de MongoDB y Propiedades índice de MongoDB . Haga clic en Agregar campo .
De forma predeterminada, MongoDB crea índices en primer plano, lo que evita todas las operaciones de lectura y escritura en la base de datos mientras índice Esto da como resultado una construcción compacta. índice tamaños y toma menos tiempo para construirse. Para permitir que las operaciones de lectura y escritura continúen mientras se construye el índice , seleccione la casilla de verificación Crear en segundo plano . Esto resulta en una imagen menos compacta. índice tamaños y tarda más en construirse.
Sin embargo, con el tiempo el tamaño convergerá como si hubieras construido el índice En primer plano. Para más información sobre la creación de índices, consulte la documentación de MongoDB .
Cuando haya terminado de agregar campos a su índice Haga clic en Crear índice .
MongoDB índice tipos
Índices de campo único
Al especificar campos indexados, se aplica un orden de clasificación para cada campo. En un solo campo índice El orden de clasificación no es importante porque MongoDB puede recorrer los datos en ambas direcciones.
Índices compuestos
Los índices compuestos especifican varios campos 인덱싱된 . El orden en el que se especifican los campos es importante. MongoDB recomienda seguir la regla ESR (Equality, Search, Range):
- en primer lugar, añada los campos contra los que se ejecutan las consultas de igualdad, es decir, las coincidencias exactas de un único valor
- a continuación, añada campos que reflejen el orden de la consulta
- por último, añada campos para filtros de rango
Índices multiclave
Los índices multiclave se utilizan para campos que contienen matrices. Solo necesita especificar el campo que contiene la clave. array y MongoDB crea automáticamente un índice clave para cada elemento del array .
Índices de texto
Los índices de texto admiten búsquedas en campos que son cadenas o un array de elementos de cadena. Puedes crear un texto índice por colección. Un texto índice Puede contener varios campos.
índice versión : hay tres versiones, siendo 3 la predeterminada.
Idioma por defecto: el idioma por defecto es el inglés. El idioma que seleccione determina las reglas que se utilizan para analizar las raíces de las palabras (sufijo-tallo) y define las palabras de parada que se filtran. Por ejemplo, en inglés, las raíces sufijales incluyen -ing y -ed, y las palabras de parada incluyen the y a.
Sustitución de idioma: especifique un nombre de campo diferente para sustituir el campo de idioma.
Pesos de campo: para cada campo de 인덱싱된 , MongoDB multiplica el número de coincidencias por el peso y suma los resultados. MongoDB utiliza esta suma para calcular la puntuación del documento. Seleccione un campo de la lista, especifique su peso en la casilla y haga clic en Añadir campo. El peso de campo por defecto es 1.
Índices comodín
Los índices comodín admiten consultas donde se desconocen los nombres de los campos, por ejemplo, en estructuras de datos arbitrarias definidas por el usuario donde el esquema es dinámico. Un índice sin comodín... índice Solo admite consultas sobre los valores de estructuras de datos definidas por el usuario. Los índices comodín filtran todos los campos coincidentes.
Para agregar un comodín índice en todos los campos de cada documento de una colección, seleccione $** (todos los campos) en la lista Campos indexados :

Índices geoespaciales
Índices 2d
Los índices 2d se utilizan para datos que se almacenan como puntos en un plano bidimensional. Los índices 2d están pensados para pares de coordenadas heredados en MongoDB 2.2 y versiones anteriores. Límite inferior y Límite superior permite especificar un rango de ubicación, en lugar de los valores predeterminados de -180 (incluido) para la longitud y 180 (no incluido) para la latitud. Precisión en bits permite establecer el tamaño en bits de los valores de localización, hasta 32 bits de precisión. El valor por defecto es de 26 bits, lo que equivale aproximadamente a 60 centímetros de precisión, cuando se utiliza el rango de localización por defecto.
2d esfera
Los índices de esfera 2d admiten consultas que calculan geometrías en una esfera similar a la Tierra.
Geo pajar
Los índices geoHaystack mejoran el rendimiento en consultas que utilizan geometría plana. Los índices geoHaystack quedaron obsoletos en MongoDB 4.4 y se eliminaron en MongoDB 5.0. Crean grupos de documentos de la misma área geográfica. Debe especificar el tamaño del grupo . Por ejemplo, un tamaño de grupo de 5 crea un... índice que agrupa valores de ubicación que se encuentran dentro de 5 unidades de la longitud y latitud dadas. El tamaño del contenedor también determina la granularidad de la índice .
MongoDB índice propiedades
Índices únicos
Los índices únicos impiden que se inserten documentos si ya existe un documento que contiene ese valor para el campo 인덱싱된 .
Índices dispersos
Los índices dispersos omiten los documentos que no contienen el campo 인덱싱된 , a menos que el valor del campo sea nulo. Los índices dispersos no contienen todos los documentos de la colección.
Índices ocultos
Los índices ocultos se ocultan del plan de consulta. Esta opción establece el índice como oculto al crearlo. Puedes configurarlo índice como no oculto en el índice Gerente, consulte Ocultar un índice para obtener más información.
Índices TTL
Los índices TTL son índices de campo único que caducan documentos y ordenan a MongoDB que elimine documentos de la base de datos tras un periodo de tiempo determinado. El campo 인덱싱된 debe ser de tipo fecha. Introduzca el tiempo de expiración en segundos.
Índices parciales
Los índices parciales sólo incluyen los documentos que cumplen una expresión de filtro.
Índices sin distinción entre mayúsculas y minúsculas
Los índices que no distinguen entre mayúsculas y minúsculas admiten consultas que ignoran las mayúsculas y minúsculas al comparar cadenas. El uso de un índice que no distingue entre mayúsculas y minúsculas... índice no afecta los resultados de una consulta. Para utilizar el índice , las consultas deben especificar lo mismo intercalación .
Define índices que no distinguen entre mayúsculas y minúsculas utilizando intercalación . intercalación Permite especificar reglas específicas del idioma para la comparación de cadenas, como reglas para acentos. Puede especificar intercalación en la recogida o índice nivel. Si una colección tiene un nivel definido intercalación , todos los índices heredan esa colección a menos que especifique uno personalizado intercalación .
Para especificar un intercalación en índice Nivel, seleccione la casilla Usar intercalación personalizada . La configuración regional es obligatoria y determina las reglas del idioma. Configure Intensidad en 1 o 2 para que no distinga entre mayúsculas y minúsculas. intercalación Todas las demás configuraciones son opcionales y sus valores predeterminados varían según la configuración regional que especifique. Para obtener más información sobre intercalación Configuración, consulte la documentación de MongoDB .
Dejando caer un índice
Los índices no utilizados afectan el rendimiento de una base de datos porque MongoDB tiene que mantenerlos índice cada vez que se insertan o actualizan documentos. La columna Uso en el índice El administrador le muestra cuántas veces un índice Se ha utilizado.
Antes de dejar caer un índice Deberías probar qué tan bien funciona índice Está respaldando las consultas ocultándolas . Si observa una disminución en el rendimiento, muestre el... índice , para que las consultas puedan utilizarlo nuevamente.
No puedes eliminar el _id predeterminado índice que MongoDB crea cuando agrega una nueva colección.
Para dejar caer un índice , realice una de las siguientes acciones:
- En el árbol de conexión, haga clic derecho en el índice y seleccione Drop índice .
- En el árbol de conexión, seleccione el índice y presione Ctrl + Retroceso (Windows) o fn + Supr (Mac)
- Seleccione el índice en el índice Administrador y haga clic en el botón Soltar índice .
- Haga clic derecho en el índice en el índice Administrador y seleccione Drop índice .
Dejar caer más de uno índice , seleccione los índices requeridos en el árbol de conexión, haga clic derecho y seleccione Eliminar índices .
Editando un índice
Editando un índice le permite modificar un existente índice , por ejemplo para cambiar los campos indexados. El índice El gerente deja caer el índice para ti y recrea el índice con los cambios que usted especificó.
Para editar un índice , realice una de las siguientes acciones para abrir el cuadro de diálogo Editar índice :
- En el árbol de conexión, haga clic derecho en el índice y seleccione Editar índice .
- En el árbol de conexión, seleccione el índice y presione la tecla Enter.
- Seleccione el índice en el índice Administrador y haga clic en el botón Editar índice .
- Haga clic derecho en el índice en el índice Administrador y seleccione Editar índice .
Realice los cambios necesarios y haga clic en Eliminar y volver a crear índice .
Tenga en cuenta que si la única modificación que realiza es la índice es ocultar o mostrar el índice , el índice El administrador no necesita eliminar y volver a crear el índice , por lo que haces clic en Aplicar cambios para realizar esta modificación.
Visita índice detalles
Puede ver una versión de solo lectura del índice detalles para que no cambies accidentalmente ninguna de las configuraciones.
Para ver los detalles de un índice , realice una de las siguientes acciones:
- Seleccione el índice en el índice Administrador y haga clic en el botón Ver detalles .
- Haga clic derecho en el índice en el índice Administrador y seleccione Ver detalles .
Escondiendo un índice
Puedes ocultar un índice del plan de consulta. Ocultar un índice Le permite evaluar el impacto de dejar caer un índice Ocultar un índice te ahorra tener que soltar el índice y luego crearlo de nuevo. Puede comparar el rendimiento de las consultas con y sin el índice ejecutando la consulta con el índice y luego esconderlo índice y ejecutar la consulta nuevamente.
Cuando escondes un índice Sus características aún se aplican; por ejemplo, los índices únicos aún aplican restricciones únicas a los documentos y los índices TTL aún expiran los documentos. El elemento oculto índice Sigue consumiendo espacio en disco y memoria, por lo que si no mejora el rendimiento, debería considerar abandonarlo. índice .
Los índices ocultos son compatibles con MongoDB 4.4 o superior. Asegúrese de que featureCompatibilityVersion sea 4.4 o superior.
Para ocultar un índice , realice una de las siguientes acciones:
- En el árbol de conexión, haga clic derecho en el índice y seleccione Ocultar índice . El índice está marcado como oculto.
- Seleccione el índice en el índice Administrador y haga clic en el botón Ocultar índice . La columna Propiedades en el índice El gerente demuestra que el índice está oculto
- Haga clic derecho en el índice en el índice Administrador y seleccione Ocultar índice .
Para mostrar un índice , realice una de las siguientes acciones:
- En el árbol de conexión, haga clic derecho en el índice y seleccione Mostrar índice .
- Seleccione el índice en el índice Administrador y haga clic en el botón Ocultar índice .
- Haga clic derecho en el índice en el índice Manager y seleccione Mostrar índice .
Copiar un índice
Puedes copiar un índice de una base de datos y pegar sus propiedades en otra base de datos.
Para copiar un índice , realice una de las siguientes acciones:
- En el árbol de conexión, haga clic derecho en el índice y seleccione Copiar índice .
- Seleccione el índice en el índice Administrador y haga clic en el botón Copiar .
- Haga clic derecho en el índice en el índice Administrador y seleccione Copiar índice .
Para pegar el índice , en el árbol de conexión, haga clic con el botón derecho en la colección de destino y seleccione Pegar índice .
Para copiar más de uno índice Seleccione los índices necesarios en el árbol de conexión, haga clic con el botón derecho y seleccione "Copiar índices" . En el árbol de conexión, haga clic con el botón derecho en la colección de destino y seleccione "Pegar índices" .
Uso de los índices de MongoDB (Tutorial)
Aunque es posible almacenar una gran cantidad de información en una base de datos MongoDB, se necesita una estrategia de indexación eficaz para obtener rápida y eficientemente la información que se necesita de ella.
En este tutorial, voy a ejecutar a través de algunos de los fundamentos de la utilización de índices MongoDB con consultas simples, dejando de lado las actualizaciones y las inserciones.
Esto pretende ser un enfoque práctico con sólo la teoría suficiente para permitirle probar los ejemplos. La intención es permitir al lector utilizar sólo el shell, aunque todo es mucho más fácil en la GUI de MongoDB que utilicé, Studio 3T.
Introducción a los índices en MongoDB
Cuando MongoDB importa sus datos a una colección, creará una clave primaria que será reforzada por un índice.
Pero no puede adivinar los otros índices que necesitarías porque no hay forma de que pueda predecir el tipo de búsquedas, ordenaciones y agregaciones que querrás hacer en estos datos.
Sólo proporciona un identificador único para cada documento de su colección, que se conserva en todos los índices posteriores. MongoDB no permite heaps. - datos no indexados unidos meramente por punteros hacia adelante y hacia atrás.
MongoDB le permite crear índices adicionales que son similares al diseño de los que se encuentran en las bases de datos relacionales, y estos necesitan una cierta cantidad de administración.
Al igual que en otros sistemas de bases de datos, existen índices especiales para datos dispersos, para buscar en el texto o para seleccionar información espacial.
Por lo general, cualquier consulta o actualización utilizará un único índice si hay uno adecuado disponible. Un índice suele mejorar el rendimiento de cualquier operación de datos, pero no siempre es así.
Es posible que te sientas tentado a probar el enfoque de la "dispersión" -crear muchos índices diferentes, para asegurarte de que habrá uno que probablemente sea adecuado-, pero el inconveniente es que cada índice consume recursos y necesita ser mantenido por el sistema cada vez que cambian los datos.
Si te excedes con los índices, llegarán a dominar las páginas de memoria y provocarán un exceso de E/S en disco. Lo mejor es un número reducido de índices muy eficaces.
Es probable que una colección pequeña quepa en la caché, por lo que el trabajo de proporcionar índices y afinar las consultas no parecerá tener mucha influencia en el rendimiento general.
Sin embargo, a medida que aumenta el tamaño de los documentos y crece su número, ese trabajo se pone en marcha. Tu base de datos escalará bien.
Creación de una base de datos de prueba
Para ilustrar algunos de los fundamentos del índice, cargaremos 70.000 clientes en MongoDB a partir de un archivo JSON. Cada documento registra el nombre de los clientes, direcciones, números de teléfono, detalles de la tarjeta de crédito y "notas de archivo". Estos se han generado a partir de números aleatorios.
Esta carga puede realizarse desde mongoimport o desde una herramienta como Studio 3T.
Especificar la intercalación en las colecciones de MongoDB
Antes de crear una colección, hay que tener en cuenta intercalaciónla forma en que se realiza la búsqueda y la ordenación (intercalación no está soportado antes de MongoDB 3.4).
Cuando ves las cadenas ordenadas, ¿quieres ver las minúsculas ordenadas después de las mayúsculas, o la ordenación debe ignorar las mayúsculas? ¿Consideras que un valor representado por una cadena es diferente según los caracteres que estén en mayúsculas? ¿Cómo tratar los caracteres acentuados? Por defecto, las colecciones tienen un binario intercalación que probablemente no es lo que se necesita en el mundo del comercio.
Para averiguar qué intercalación se utiliza en su colección, si es que se utiliza alguna, puede utilizar este comando (aquí para nuestra colección "Clientes").
db.getCollectionInfos({name: 'Customers'})

Esto muestra que he configurado la colección Customers con la intercalación 'en'.
Si me desplazo hacia abajo por la salida del intérprete de comandos, veré que todos los índices de MongoDB tienen el mismo intercalación, lo cual es bueno.
Lamentablemente, no se puede cambiar la intercalación de una colección existente. Es necesario crear la colección antes de añadir los datos.
A continuación se muestra cómo crear una colección "Clientes" con un intercalación en inglés. En Studio 3T, puede definir la intercalación tanto a través de la interfaz de usuario como de la IntelliShell integrada.
Esta es la pestaña de intercalación de la ventana "Añadir nueva intercalación", a la que se accede haciendo clic con el botón derecho en el nombre de la base de datos y haciendo clic en "Añadir nueva intercalación...".

Puede conseguir lo mismo en IntelliShell utilizando el comando:
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

Como alternativa, puede añadir información de intercalación a cualquier búsqueda, ordenación o comparación de cadenas que realice.
En mi experiencia, es más ordenado, seguro y fácil de cambiar si se hace a nivel de colección. Si la intercalación de un índice no coincide con la intercalación de la búsqueda u ordenación que se realiza, MongoDB no puede utilizar el índice.
Si está importando un documento, lo mejor es que su orden natural esté preclasificado según la intercalación especificada en el orden del atributo más comúnmente indexado. Esto hace que la clave primaria esté "agrupada" en el sentido de que el índice puede tener menos bloques de páginas que visitar por cada búsqueda de clave de índice, y el sistema obtendrá una tasa de aciertos mucho mayor.
Entendiendo el esquema
Una vez cargado el modelo de datos, podemos ver su esquema simplemente examinando el primer documento
db.Customers.find({}).limit(1);
En Studio 3T, puede verlo en la pestaña Colección:

Índices MongoDB para consultas sencillas
Acelerar una consulta muy sencilla
Ahora ejecutaremos una sencilla consulta en nuestra base de datos recién creada para encontrar todos los clientes cuyo apellido sea 'Johnston'.
Deseamos realizar una proyección sobre, o seleccionar, 'Nombre' y 'Apellido', ordenados por 'Apellido'. La línea "_id" : NumberInt(0), sólo significa 'por favor, no devuelva el ID'.
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

Una vez que estamos seguros de que la consulta devuelve el resultado correcto, podemos modificarla para que devuelva las estadísticas de ejecución.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
Según las estadísticas de ejecución de 'Explain', esto lleva 59 ms en mi máquina (ExecutionTimeMillis). Esto implica un COLLSCAN, lo que significa que no hay ningún índice disponible, por lo que mongo debe escanear toda la colección.
Esto no es necesariamente algo malo con una colección razonablemente pequeña, pero a medida que el tamaño aumenta y más usuarios acceden a los datos, es menos probable que la colección quepa en la memoria paginada, y la actividad del disco aumentará.
La base de datos no escalará bien si se ve obligada a realizar un gran porcentaje de COLLSCANs. Es una buena idea minimizar los recursos utilizados por las consultas que se ejecutan con frecuencia.
Bueno, es obvio que si un índice va a reducir el tiempo empleado, es probable que tenga que ver con Nombre.Apellido.
Empecemos con eso, haciéndolo un índice ascendente ya que queremos que el orden sea ascendente:
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
Ahora tarda 4 ms en mi máquina (ExecutionTimeMillis). Esto implica un IXSCAN (un escaneo de índice para obtener claves) seguido de un FETCH (para recuperar los documentos).
Podemos mejorar esto porque la consulta tiene que obtener el nombre de pila.
Si agregamos el Nombre.Nombre en el índice , entonces el motor de base de datos puede usar el valor en el índice en lugar de tener que realizar el paso adicional de tomarlo de la base de datos.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
Con esto en su lugar, la consulta tarda menos de 2 ms.
Debido a que el índice 'cubría' la consulta, MongoDB fue capaz de hacer coincidir las condiciones de la consulta y devolver los resultados utilizando únicamente las claves del índice; sin necesidad siquiera de examinar documentos de la colección para devolver los resultados. (Si ve una etapa IXSCAN que no es hija de una etapa FETCH, en el plan de ejecución entonces el índice 'cubrió' la consulta).
Notará que nuestra ordenación era ascendente, A-Z. Lo especificamos con un 1 como valor para la ordenación. ¿Qué pasa si el resultado final necesita ser de Z-A (descendente) especificado por -1? No hay diferencia detectable con este corto conjunto de resultados.
Esto parece un progreso. Pero, ¿y si te equivocas de índice? Eso puede causar problemas.
Si se cambia el orden de los dos campos en el índice para que Nombre.PrimerNombre vaya antes que Nombre.Apellido, el tiempo de ejecución se dispara a 140 ms, un incremento enorme.
Esto parece extraño porque el índice En realidad, ha ralentizado la ejecución de modo que tarda más del doble del tiempo que tardaba con solo la primaria predeterminada. índice (entre 40 y 60 Ms). MongoDB ciertamente verifica las posibles estrategias de ejecución para encontrar una buena, pero a menos que haya proporcionado una adecuada índice , le resulta difícil seleccionar el correcto.
¿Qué hemos aprendido hasta ahora?
Parece que las consultas sencillas se benefician más de los índices que intervienen en los criterios de selección, y con la misma intercalación.
En nuestro ejemplo anterior, ilustramos una verdad general sobre los índices de MongoDB: si el primer campo del índice no forma parte de los criterios de selección, no es útil ejecutar la consulta.
Acelerar las consultas unSARGable
¿Qué ocurre si tenemos dos criterios, uno de los cuales implica una coincidencia de cadena dentro del valor?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
Queremos encontrar a un cliente llamado Wiggins que vive en Rutland. Se necesitan 50 ms sin ningún índice de apoyo.
Si excluimos el nombre de la búsqueda, el tiempo de ejecución se duplica.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
Si ahora introducimos un índice compuesto que comienza con el nombre y luego añade la dirección, descubrimos que la consulta fue tan rápida que se registraron 0 ms.
Esto se debe a que el índice permitió a MongoDB encontrar sólo esos 52 Wiggins en la base de datos y hacer la búsqueda a través de sólo esas direcciones. Parece suficiente.
¿Qué ocurre si cambiamos los dos criterios? Sorprendentemente, el criterio "explicar" reporta 72 ms.
Ambos son criterios válidos especificados en la consulta, pero si se utiliza el incorrecto la consulta es peor que inútil hasta 20 ms.
La razón de la diferencia es obvia. El índice puede impedir una exploración a través de todos los datos, pero no puede ayudar a la búsqueda, ya que implica una expresión regular.
Aquí hay dos principios generales.
Una búsqueda compleja debe reducir al máximo los candidatos a la selección con el primer elemento de la lista de índices. "Cardinalidad" es el término utilizado para este tipo de selectividad. Un campo con baja cardinalidad, como el género, es mucho menos selectivo que el apellido.
En nuestro ejemplo, el apellido es lo suficientemente selectivo como para ser la elección obvia para el primer campo que aparece en un índice, pero no muchas consultas son tan obvias.
La búsqueda que ofrece el primer campo en un campo utilizable índice debería ser SARGable. Esto es una forma abreviada de decir que el índice El campo debe ser Argumentable de búsqueda .
En el caso de la búsqueda de la palabra "rutland", el término buscado no guardaba relación directa con lo que aparecía en el índice ni con el orden de clasificación del mismo.
Pudimos utilizarlo eficazmente sólo porque utilizamos el orden del índice para persuadir a MongoDB de la mejor estrategia para encontrar los veinte 'Wiggins' probables en la base de datos y luego utilizar la copia de la dirección completa en el índice en lugar del propio documento.
A continuación, podría buscar esas veinte direcciones completas muy rápidamente, sin ni siquiera tener que obtener los datos de los veinte documentos. Por último, gracias a la clave primaria del índice, podía obtener rápidamente el documento correcto de la colección.
Incluir una matriz embebida en una búsqueda
Intentemos una consulta un poco más compleja.
Queremos buscar por el apellido y la dirección de correo electrónico del cliente.
Nuestra colección de documentos permite a nuestro "cliente" tener una o varias direcciones de correo electrónico. Éstas se encuentran en una matriz embebida.
Sólo queremos encontrar a alguien con un apellido en concreto, "Barker" en nuestro ejemplo, y una dirección de correo electrónico determinada, "[email protected]" en nuestro ejemplo.
Queremos devolver sólo la dirección de correo electrónico que coincide y sus detalles (cuándo se registró y cuándo dejó de ser válida). Ejecutaremos esto desde el shell y examinaremos las estadísticas de ejecución.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Lo que da:
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
Esto nos indica que Cassie Barker tuvo la dirección de correo electrónico [email protected] desde el 11 de enero de 2016 hasta el 25 de enero de 2018. Cuando ejecutamos la consulta, tardó 240 ms porque no había ningún índice útil (examinó los 40000 documentos en un COLLSCAN).
Para ello, podemos crear un índice:
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
Este índice redujo el tiempo de ejecución a 6 ms.
El índice Nad que era el único disponible para la colección estaba sólo en el campo Nombre.Apellido.
Para la fase de entrada, se utilizó la estrategia IXSCAN, que devolvió rápidamente 33 documentos coincidentes.
A continuación, se filtran los documentos coincidentes para obtener la matriz EmailAddresses de la dirección, que se devolvía en la etapa de proyección. En total se utilizaron 3 ms, frente a los 70 ms que se necesitaron.
La adición de otros campos en el índice no tuvo ningún efecto perceptible. Ese primer campo del índice es el que determina el éxito.
¿Y si sólo quisiéramos saber quién utiliza una determinada dirección de correo electrónico?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Aquí, un índice en el campo emailAddress hace maravillas. Sin un índice adecuado, hace un COLLSCAN que tarda unos 70 ms en mi servidor de desarrollo.
Con un índice...
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
... el tiempo empleado ahora es demasiado rápido para medirlo.
Habrás observado que, para indexar un campo que contiene un valor de matriz, MongoDB crea una clave de índice para cada elemento de la matriz.
Podríamos hacerlo aún más rápido si asumiéramos que las direcciones de correo electrónico son únicas (en estos datos falsos no lo son, y en la vida real es una suposición peligrosa).
También podemos utilizar el índice para "cubrir" la recuperación del campo "Nombre completo", de forma que MongoDB pueda recuperar este valor del índice en lugar de recuperarlo de la base de datos, pero la proporción de tiempo ahorrado será escasa.
Una de las razones por las que las recuperaciones de índices funcionan tan bien es que tienden a obtener tasas de acierto en caché mucho mejores que las exploraciones de colecciones completas. Sin embargo, si toda la colección cabe en la caché, el escaneo de la colección se acercará más a la velocidad de los índices.
Uso de agregaciones
Veamos cuáles son los nombres más populares de nuestra lista de clientes, utilizando una agregación. Proporcionaremos un índice sobre "Nombre.Apellido".
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
Así que en nuestro top ten, tenemos mucho de la familia Snyder:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
Esto llevó sólo 8 ms a pesar de hacer un COLLSCAN porque toda la base de datos podía mantenerse en memoria caché.
Utiliza el mismo plan de consulta incluso si realiza la agregación en un campo no indexado. (Elisha, Eric, Kim y Lee son los nombres de pila más populares).
Me pregunto qué nombres de pila suelen atraer más notas en su expediente.
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
En mis datos falsos, las personas llamadas Charisse son las que reciben más notas. Aquí sabemos que un COLLSCAN es inevitable ya que el número de notas cambiará en un sistema vivo. Algunas bases de datos permiten índices en columnas calculadas, pero esto no sería de ayuda en este caso.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
El rendimiento de las agregaciones puede mejorarse mediante un índice porque pueden abarcar la agregación. Sólo los operadores de canalización $match y $sort pueden aprovechar un índice directamente, y sólo si se producen al principio de la canalización.
El generador de datos SQL se utilizó para generar los datos de prueba de este tutorial.
Conclusiones
- Cuando desarrolle una estrategia de indexación para MongoDB, descubrirá que hay una serie de factores a tener en cuenta, como la estructura de los datos, el patrón de uso y la configuración de los servidores de bases de datos.
- MongoDB generalmente utiliza un solo índice cuando ejecuta una consulta, tanto para buscar como para ordenar; y si puede elegir una estrategia, muestreará los mejores índices candidatos.
- La mayoría de las colecciones de datos tienen algunos candidatos bastante buenos para los índices, que probablemente diferencien claramente entre los documentos de la colección, y que probablemente sean populares a la hora de realizar búsquedas.
- Es una buena idea ser parsimonioso con los índices porque tienen un coste menor en términos de recursos. Un peligro mayor es olvidar lo que ya existe, aunque afortunadamente no es posible crear índices duplicados en MongoDB.
- Aún es posible crear varios índices compuestos muy parecidos en su constitución. Si un índice no se utiliza, es mejor eliminarlo.
- Los índices compuestos son muy útiles para realizar consultas. Utilizan el primer campo para realizar la búsqueda y, a continuación, utilizan los valores de los demás campos para devolver los resultados, en lugar de tener que obtener los valores de los documentos. También admiten ordenaciones que utilizan más de un campo, siempre que estén en el orden correcto.
- Para que los índices sean eficaces en las comparaciones de cadenas, deben utilizar la misma intercalación.
- Merece la pena vigilar el rendimiento de las consultas. Además de utilizar los valores devueltos por explain(), merece la pena cronometrar las consultas y comprobar si se producen consultas de larga duración activando la creación de perfiles y examinando las consultas lentas. A menudo es sorprendentemente fácil transformar la velocidad de estas consultas proporcionando el índice adecuado.
Preguntas frecuentes sobre los índices de MongoDB
Los índices no ralentizan las consultas en MongoDB. Sin embargo, cuando se crea, actualiza o elimina un documento, los índices asociados también deben actualizarse y esto afecta al rendimiento de escritura.
Debería evitar la indexación en MongoDB cuando tenga una colección pequeña o cuando tenga una colección que no se consulte con frecuencia.
Porque MongoDB crea un archivo para cada índice Demasiados índices pueden afectar el rendimiento. Al iniciarse el motor de almacenamiento de MongoDB, abre todos los archivos, por lo que el rendimiento disminuye si hay demasiados índices.
Haga doble clic en la sección Índices del árbol de conexión de las colecciones que desee comparar para tener dos pestañas del Administrador índice . Haga clic con el botón derecho en la parte superior de una de las pestañas y seleccione Dividir verticalmente . Las pestañas se muestran en paralelo para que pueda comparar los índices de ambas bases de datos.
Ejecute su consulta en la pestaña Colecciones y abra la pestaña Explicar para ver una representación visual de cómo MongoDB la ha procesado. Si la consulta ha utilizado un índice , verá una etapa de escaneo de índice etapa de lo contrario, verá una etapa de escaneo de colección etapa Para obtener información sobre el uso de la pestaña Explicar, consulte el artículo de la base de conocimientos Explicación visual | MongoDB Explain, Visualizado .
Busque la colección en el árbol de Conexión y haga doble clic en la sección Índices para abrirla. índice Gerente. El índice El administrador muestra la información de tamaño para cada uno índice en la colección.
Busque la colección en el árbol de conexión. Los índices se listan en la sección Índices, debajo del nombre de la colección. Haga doble clic en un índice para ver una versión de solo lectura de sus detalles. Los detalles de tamaño y uso se muestran en el índice Pestaña Administrador en la pestaña Colecciones.
Cuando MongoDB crea un índice , bloquea temporalmente la colección, lo que impide todas las operaciones de lectura y escritura en los datos de dicha colección. MongoDB crea metadatos índice , una tabla temporal de claves y una tabla temporal de violaciones de restricciones. El bloqueo de la colección se reduce y se permiten operaciones de lectura y escritura periódicamente. MongoDB escanea los documentos de la colección y escribe en las tablas temporales. Mientras MongoDB crea el índice , hay varios pasos en el proceso donde la colección se bloquea exclusivamente. Para obtener más información sobre el proceso de compilación, consulte la documentación de MongoDB . Una vez creado el índice , MongoDB actualiza los metadatos índice y libera el bloqueo.
En un entorno de producción, si su colección tiene una gran carga de escritura, debería considerar construir su propia índice durante períodos de operaciones reducidas, por ejemplo durante períodos de mantenimiento, para que el rendimiento no se vea afectado y índice El tiempo de construcción es más corto.
Cuando creas un índice En MongoDB, el dígito 1 especifica que desea crear el índice en orden ascendente. Para crear un índice En orden descendente, se utiliza -1.
Más información sobre los índices de MongoDB
¿Le interesa saber más sobre los índices de MongoDB? Consulte estos artículos de la base de conocimientos relacionados:
Cómo optimizar las consultas de MongoDB mediante find() e índices
Cómo utilizar MongoDB Profiler y explain() para encontrar consultas lentas
Visual Explain | MongoDB Explain, Visualizado
Este artículo fue publicado originalmente por Phil Factor y ha sido actualizado.







