
Présentation du nouveau gestionnaire de Studio 3T 인덱스
Vous voulez connaître le moyen le plus rapide de savoir quels index vous avez sur une collection ou d'en créer facilement de nouveaux ? Essayez le nouveau gestionnaire 인덱스 amélioré, qui vous permet de masquer et d'effacer des index en cliquant sur un bouton, ce qui élimine le temps d'attente nécessaire à la reconstruction de vos index. Voyez en un coup d'œil la fréquence d'utilisation de vos index. Vous pouvez même obtenir une comparaison côte à côte des index sur différentes bases de données.
Essayez Studio 3T gratuitementQue sont les index dans MongoDB et pourquoi en avons-nous besoin ?
Les index rendent l'interrogation des données plus efficace. Sans index, MongoDB effectue un balayage de la collection qui lit tous les documents de la collection pour déterminer si les données correspondent aux conditions spécifiées dans la requête. Les index limitent le nombre de documents lus par MongoDB et, en choisissant les bons index, vous pouvez améliorer les performances. Les index stockent la valeur d'un champ ou d'un ensemble de champs, classés en fonction de la valeur du champ.

Affichage du gestionnaire 인덱스
Pour afficher les index d'une collection, localisez la collection dans l'arbre des connexions et développez-la. Vous pouvez développer la section Index pour voir les noms 인덱스 :
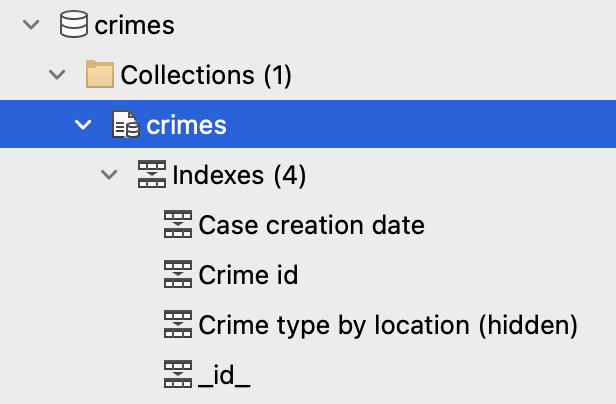
Pour afficher le gestionnaire 인덱스 , double-cliquez sur l'entrée Index en haut de la section Index.
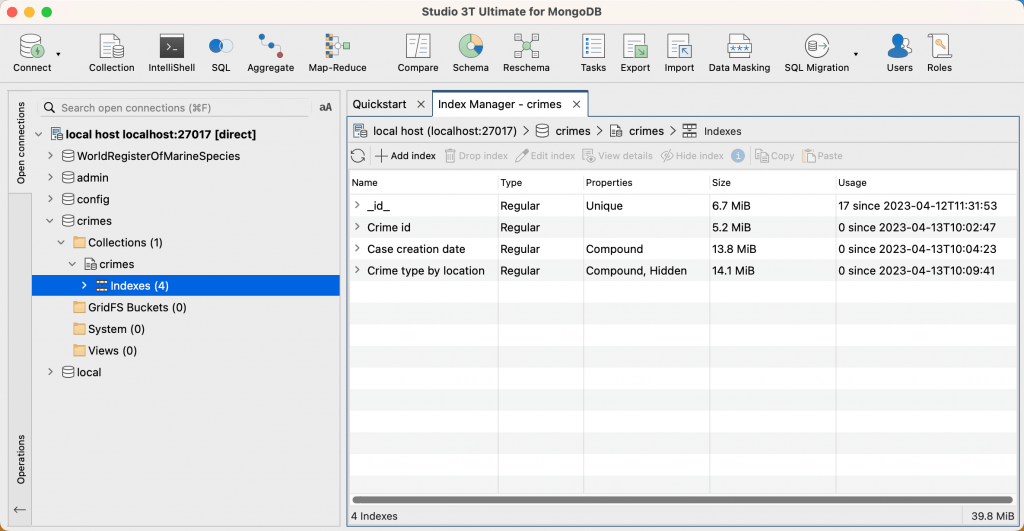
Le gestionnaire 인덱스 affiche une liste de tous les index de la collection :
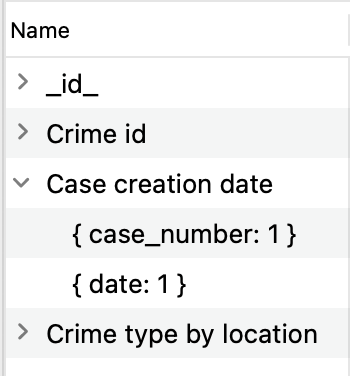
Pour afficher les champs 인덱싱된 et leur ordre de tri, cliquez sur la flèche du champ Nom:
인덱스 taille
Pour de meilleures performances, assurez-vous que tous vos index sur toutes vos collections tiennent dans la RAM de votre serveur MongoDB afin d'éviter de lire les index sur le disque. Dans certains cas, les index ne stockent que les valeurs récentes dans la RAM. Pour plus d'informations, consultez la documentation de MongoDB. Le champ Taille indique la taille de chaque 인덱스 dans la collection sélectionnée. La taille totale de 인덱스 (somme de tous les index) pour la collection est affichée dans le coin inférieur droit du gestionnaire 인덱스 .
인덱스 utilisation
인덱스 Usage indique combien de fois un site 인덱스 a été utilisé depuis sa création ou depuis le dernier redémarrage du serveur.
인덱스 Manager n'affiche des informations sur l'utilisation que si votre utilisateur dispose de privilèges pour la commande $indexStats de MongoDB. Pour plus d'informations sur les statistiques 인덱스 , consultez la documentation de MongoDB.
Si un site 인덱스 n'est pas utilisé, il convient de le supprimer afin d'éliminer les frais généraux liés à la maintenance du site 인덱스 lorsque les valeurs des champs sont mises à jour, ainsi que l'espace disque.
Ajouter un 인덱스
Dans l'arbre des connexions, cliquez avec le bouton droit de la souris sur une collection, puis sélectionnez Ajouter 인덱스.
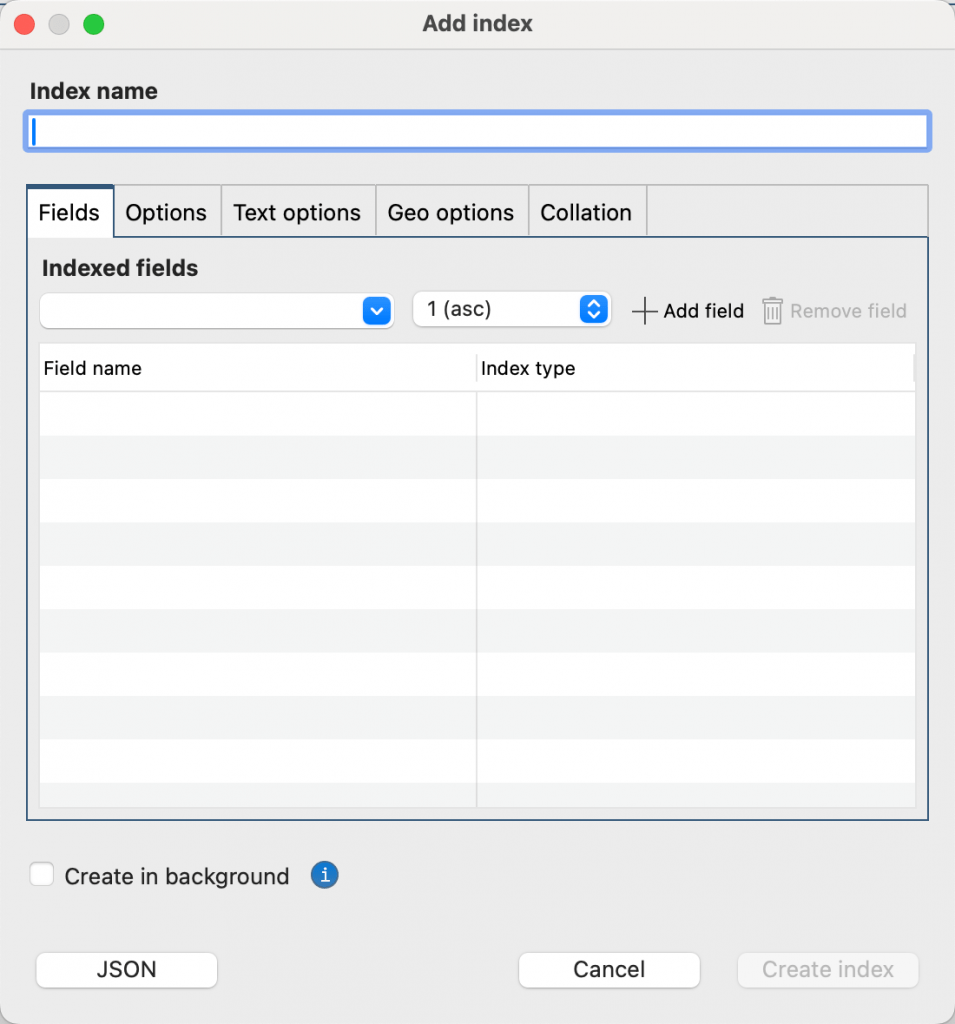
Dans la boîte de dialogue Ajouter 인덱스, tapez le nom de votre 인덱스 dans la case 인덱스 name. Si vous laissez la case 인덱스 vide, Studio 3T crée un nom 인덱스 par défaut, basé sur les noms des champs que vous sélectionnez et sur le type 인덱스 .
Ajoutez les champs requis à votre 인덱스. Pour ce faire, sélectionnez le champ dans la liste des champs인덱싱된 , puis sélectionnez l'ordre de tri (1 asc ou -1 desc) ou le type de 인덱스. Pour en savoir plus sur les types et les propriétés 인덱스 , voir MongoDB 인덱스 types et MongoDB 인덱스 properties. Cliquez sur Ajouter un champ.
Par défaut, MongoDB construit les index au premier plan, ce qui empêche toutes les opérations de lecture et d'écriture dans la base de données pendant la construction de 인덱스 . Cela permet d'obtenir des tailles compactes et prend moins de temps. 인덱스 Pour permettre aux opérations de lecture et d'écriture de se poursuivre pendant la construction de 인덱스, cochez la case Créer en arrière-plan. La taille de 인덱스 est alors moins compacte et la construction prend plus de temps.
Cependant, au fil du temps, la taille convergera comme si vous aviez construit le site 인덱스 au premier plan. Pour plus d'informations sur la création d'index, consultez la documentation de MongoDB.
Lorsque vous avez fini d'ajouter des champs à votre 인덱스 , cliquez sur Créer 인덱스.
MongoDB 인덱스 types
Index à champ unique
Lorsque vous spécifiez les champs 인덱싱된 , vous appliquez un ordre de tri à chaque champ. Dans un champ unique 인덱스, l'ordre de tri n'est pas important car MongoDB peut parcourir les données dans les deux sens.
Indices composés
Les index composés spécifient plusieurs champs 인덱싱된 . L'ordre dans lequel vous spécifiez les champs est important. MongoDB recommande de suivre la règle ESR (Equality, Search, Range) :
- ajoutez tout d'abord les champs pour lesquels des requêtes d'égalité sont exécutées, c'est-à-dire des correspondances exactes sur une seule valeur
- ensuite, ajouter des champs qui reflètent l'ordre de tri de la requête
- enfin, ajouter des champs pour les filtres de plage
Index à clés multiples
Les index multi-clés sont utilisés pour les champs qui contiennent des tableaux. Il vous suffit de spécifier le champ qui contient le tableau et MongoDB crée automatiquement une clé 인덱스 pour chaque élément du tableau.
Index des textes
Les index de texte permettent d'effectuer des recherches sur des champs qui sont des chaînes de caractères ou un tableau d'éléments de chaînes de caractères. Vous pouvez créer un texte 인덱스 par collection. Un texte 인덱스 peut contenir plusieurs champs.
인덱스 version: il existe trois versions, la version 3 étant la version par défaut.
Langue par défaut : la langue par défaut est l'anglais. La langue que vous sélectionnez détermine les règles utilisées pour analyser les racines des mots (suffixe) et définit les mots d'arrêt qui sont filtrés. Par exemple, en anglais, les suffixes comprennent -ing et -ed, et les mots vides comprennent the et a.
Remplacement de la langue: spécifier un nom de champ différent pour remplacer le champ de la langue.
Poids des champs: pour chaque champ 인덱싱된 , MongoDB multiplie le nombre de correspondances par le poids et additionne les résultats. MongoDB utilise cette somme pour calculer un score pour le document. Sélectionnez un champ dans la liste, indiquez son poids dans la case et cliquez sur Ajouter un champ. Le poids du champ par défaut est de 1.
Index de caractères génériques
Les index Wildcard prennent en charge les requêtes lorsque les noms des champs sont inconnus, par exemple dans des structures de données arbitraires définies par l'utilisateur et dont le schéma est dynamique. Un index non générique 인덱스 ne prend en charge que les requêtes portant sur les valeurs des structures de données définies par l'utilisateur. Les index Wildcard filtrent tous les champs correspondants.
Pour ajouter un joker 인덱스 sur tous les champs de chaque document d'une collection, sélectionnez $** (tous les champs) dans la liste des champs인덱싱된 :

Index géospatiaux
Index 2d
Les index 2d sont utilisés pour les données stockées sous forme de points sur un plan bidimensionnel. Les index 2d sont destinés aux paires de coordonnées héritées de MongoDB 2.2 et antérieures. Lower bound (limite inférieure ) et Upper bound (limite supérieure ) vous permettent de spécifier une plage d'emplacement, au lieu des paramètres par défaut de -180 (inclus) pour la longitude et 180 (non inclus) pour la latitude. La précision des bits vous permet de définir la taille en bits des valeurs d'emplacement, jusqu'à 32 bits de précision. La valeur par défaut est de 26 bits, ce qui correspond à une précision d'environ 60 centimètres, lorsque l'on utilise la plage d'emplacements par défaut.
2d sphère
Les index 2d sphere supportent les requêtes qui calculent les géométries sur une sphère de type terrestre.
Botte de foin géo
Les index geoHaystack améliorent les performances des requêtes qui utilisent une géométrie plate. Les index geoHaystack étaient obsolètes dans MongoDB 4.4 et ont été supprimés dans MongoDB 5.0. Les index geoHaystack créent des groupes de documents provenant de la même zone géographique. Vous devez spécifier la taille du panier. Par exemple, une taille de 5 crée un index 인덱스 qui regroupe les valeurs de localisation situées dans un rayon de 5 unités autour de la longitude et de la latitude données. La taille du seau détermine également la granularité de 인덱스.
Propriétés de MongoDB 인덱스
Index uniques
Les index uniques empêchent l'insertion de documents s'il existe déjà un document contenant cette valeur pour le champ 인덱싱된 .
Index clairsemés
Les index épars sautent les documents qui ne contiennent pas le champ 인덱싱된 , sauf si la valeur du champ est nulle. Les index épars ne contiennent pas tous les documents de la collection.
Index cachés
Les index cachés sont cachés dans le plan de requête. Cette option définit l'index 인덱스 comme étant caché lors de sa création. Vous pouvez définir l'index 인덱스 comme non caché dans le gestionnaire 인덱스 , voir Masquer un 인덱스 pour plus d'informations.
Index TTL
Les index TTL sont des index à champ unique qui expirent les documents et demandent à MongoDB de supprimer les documents de la base de données après une période donnée. Le champ 인덱싱된 doit être de type date. Saisissez le délai d'expiration en secondes.
Index partiels
Les index partiels n'incluent que les documents qui répondent à une expression de filtre.
Index insensibles à la casse
Les index insensibles à la casse prennent en charge les requêtes qui ignorent la casse lors de la comparaison des chaînes de caractères. L'utilisation d'un index insensible à la casse 인덱스 n'affecte pas les résultats d'une requête. Pour utiliser l'index insensible à la casse 인덱스, les requêtes doivent spécifier la même collation.
Vous définissez des index insensibles à la casse à l'aide de la collation. La collation vous permet de spécifier des règles spécifiques à la langue pour la comparaison des chaînes, telles que des règles pour les accents. Vous pouvez spécifier la collation au niveau de la collection ou de 인덱스 . Si une collection a une collation définie, tous les index héritent de cette collection, à moins que vous ne spécifiiez une collation personnalisée.
Pour spécifier une collation au niveau de 인덱스 , cochez la case Utiliser une collation personnalisée. Le paramètre Locale est obligatoire et détermine les règles linguistiques. Attribuez la valeur 1 ou 2 à Strength pour une collation insensible à la casse. Tous les autres paramètres sont facultatifs et leurs valeurs par défaut varient en fonction des paramètres régionaux spécifiés. Pour plus d'informations sur les paramètres de collation, consultez la documentation de MongoDB.
Déposer un 인덱스
Les index inutilisés ont un impact sur les performances d'une base de données car MongoDB doit maintenir le site 인덱스 à chaque fois que des documents sont insérés ou mis à jour. La colonne Usage du gestionnaire 인덱스 indique combien de fois un index 인덱스 a été utilisé.
Avant d'abandonner un site 인덱스, vous devez tester l'efficacité du site 인덱스 en le masquant. Si vous observez une diminution des performances, libérez le site 인덱스, afin que les requêtes puissent à nouveau l'utiliser.
Vous ne pouvez pas supprimer l'identifiant par défaut _id 인덱스 que MongoDB crée lorsque vous ajoutez une nouvelle collection.
Pour abandonner un site 인덱스, effectuez l'une des opérations suivantes :
- dans l'arbre des connexions, cliquez avec le bouton droit de la souris sur 인덱스 et sélectionnez Drop 인덱스.
- dans l'arbre des connexions, sélectionnez le site 인덱스 et appuyez sur Ctrl + Backspace (Windows) ou fn + Delete (Mac)
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Drop 인덱스.
- Cliquez avec le bouton droit de la souris sur le site 인덱스 dans le gestionnaire 인덱스 et sélectionnez Drop 인덱스.
Pour supprimer plusieurs 인덱스, sélectionnez les index requis dans l'arborescence des connexions, cliquez avec le bouton droit de la souris et sélectionnez Supprimer les index.
Modification d'un 인덱스
L'édition d'un 인덱스 vous permet de modifier un 인덱스 existant, par exemple pour changer les champs du 인덱싱된 . Le gestionnaire 인덱스 supprime le 인덱스 pour vous et recrée le 인덱스 avec les modifications que vous avez spécifiées.
Pour éditer un site 인덱스, effectuez l'une des opérations suivantes pour ouvrir la boîte de dialogue Editer 인덱스:
- dans l'arbre des connexions, cliquez avec le bouton droit de la souris sur 인덱스 et sélectionnez Editer 인덱스.
- dans l'arborescence des connexions, sélectionnez le site 인덱스 et appuyez sur la touche Entrée.
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Modifier 인덱스.
- cliquez avec le bouton droit de la souris sur le site 인덱스 dans le gestionnaire 인덱스 et sélectionnez Modifier 인덱스.
Apportez les modifications nécessaires et cliquez sur Déposer et recréer 인덱스.
Notez que si la seule modification que vous apportez au site 인덱스 est de masquer ou d'enlever le site 인덱스, le gestionnaire 인덱스 n'a pas besoin de déposer et de recréer le site 인덱스, vous devez donc cliquer sur Appliquer les modifications pour effectuer cette modification.
Visualisation des détails de 인덱스
Vous pouvez afficher une version en lecture seule des détails du site 인덱스 afin de ne pas modifier accidentellement les paramètres.
Pour afficher les détails d'un site 인덱스, effectuez l'une des opérations suivantes :
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Afficher les détails.
- cliquez avec le bouton droit de la souris sur le site 인덱스 dans le gestionnaire 인덱스 et sélectionnez View details.
Cacher un 인덱스
Vous pouvez masquer un 인덱스 dans le plan de requête. Le fait de cacher un 인덱스 vous permet d'évaluer l'impact de l'abandon d'un 인덱스. Le fait de cacher un 인덱스 vous évite de devoir abandonner le 인덱스 et de le créer à nouveau. Vous pouvez comparer les performances des requêtes avec et sans 인덱스 en exécutant la requête avec 인덱스 , puis en masquant 인덱스 et en exécutant à nouveau la requête.
Lorsque vous masquez un site 인덱스, ses caractéristiques restent valables ; par exemple, les index uniques continuent d'appliquer des contraintes uniques aux documents et les index TTL continuent d'expirer les documents. Le site 인덱스 caché continue de consommer de l'espace disque et de la mémoire. Si cela n'améliore pas les performances, vous devriez envisager d'abandonner le site 인덱스.
Les index cachés sont pris en charge à partir de la version 4.4 de MongoDB. Assurez-vous que la valeur de featureCompatibilityVersion est égale ou supérieure à 4.4.
Pour masquer un site 인덱스, effectuez l'une des opérations suivantes :
- dans l'arborescence des connexions, cliquez avec le bouton droit de la souris sur 인덱스 et sélectionnez Hide 인덱스. Le site 인덱스 est marqué comme étant caché.
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Hide 인덱스. La colonne Propriétés du gestionnaire 인덱스 indique que le site 인덱스 est masqué.
- cliquez avec le bouton droit de la souris sur 인덱스 dans le gestionnaire 인덱스 et sélectionnez Hide 인덱스.
Pour supprimer le cache d'une page 인덱스, effectuez l'une des opérations suivantes :
- dans l'arbre des connexions, cliquez avec le bouton droit de la souris sur 인덱스 et sélectionnez Unhide 인덱스.
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Hide 인덱스.
- Cliquez avec le bouton droit de la souris sur le site 인덱스 dans le gestionnaire 인덱스 et sélectionnez Unhide 인덱스.
Copier un 인덱스
Vous pouvez copier un site 인덱스 d'une base de données et coller ses propriétés dans une autre base de données.
Pour copier un site 인덱스, effectuez l'une des opérations suivantes :
- dans l'arbre des connexions, cliquez avec le bouton droit de la souris sur 인덱스 et sélectionnez Copier 인덱스.
- sélectionnez le site 인덱스 dans le gestionnaire 인덱스 et cliquez sur le bouton Copier.
- cliquez avec le bouton droit de la souris sur le site 인덱스 dans le gestionnaire 인덱스 et sélectionnez Copier 인덱스.
Pour coller le site 인덱스, dans l'arborescence des connexions, cliquez avec le bouton droit de la souris sur la collection cible et sélectionnez Coller 인덱스.
Pour copier plusieurs 인덱스, sélectionnez les index requis dans l'arborescence des connexions, cliquez avec le bouton droit de la souris et sélectionnez Copier les index. Dans l'arborescence des connexions, cliquez avec le bouton droit de la souris sur la collection cible et sélectionnez Coller les index.
Utiliser les index de MongoDB (Tutoriel)
Bien qu'il soit possible de stocker un grand nombre d'informations dans une base de données MongoDB, vous avez besoin d'une stratégie d'indexation efficace pour obtenir rapidement et efficacement les informations dont vous avez besoin.
Dans ce tutoriel, je vais passer en revue certaines des bases de l'utilisation des index MongoDB avec des requêtes simples, en laissant de côté les mises à jour et les insertions.
Il s'agit d'une approche pratique avec juste assez de théorie pour vous permettre d'essayer les exemples. L'intention est de permettre au lecteur de n'utiliser que le shell, bien que tout soit beaucoup plus facile dans l'interface graphique MongoDB que j'ai utilisée, Studio 3T.
Une introduction aux index de MongoDB
Lorsque MongoDB importe vos données dans une collection, il crée une clé primaire qui est renforcée par un index.
Mais il ne peut pas deviner les autres index dont vous aurez besoin, car il ne peut en aucun cas prédire le type de recherches, de tris et d'agrégations que vous voudrez effectuer sur ces données.
Il fournit simplement un identifiant unique pour chaque document de votre collection, qui est conservé dans tous les index ultérieurs. MongoDB n'autorise pas les tas. - des données non indexées liées simplement par des pointeurs avant et arrière.
MongoDB vous permet de créer des index supplémentaires qui sont similaires à ceux des bases de données relationnelles et qui nécessitent une certaine administration.
Comme pour les autres systèmes de base de données, il existe des index spéciaux pour les données éparses, pour la recherche dans le texte ou pour la sélection d'informations spatiales.
S'il existe un index approprié, une requête ou une mise à jour n'utilisera généralement qu'un seul index . Un index peut généralement améliorer les performances d'une opération sur les données, mais ce n'est pas toujours le cas.
Vous pouvez être tenté d'adopter l'approche du "saupoudrage", c'est-à-dire de créer de nombreux index différents, afin de s'assurer qu'il y en aura toujours un qui conviendra, mais l'inconvénient est que chaque index utilise des ressources et doit être maintenu par le système à chaque fois que les données changent.
Si vous avez trop d'index, ils finiront par dominer les pages de la mémoire et entraîneront des entrées/sorties excessives sur le disque. Il est préférable d'avoir un petit nombre d'index très efficaces.
Une petite collection est susceptible de tenir dans la mémoire cache, de sorte que le travail de création d'index et d'ajustement des requêtes ne semble pas avoir beaucoup d'influence sur les performances globales.
Toutefois, à mesure que la taille des documents augmente et que le nombre de documents s'accroît, ce travail se met en place. Votre base de données s'adaptera bien.
Création d'une base de données de test
Pour illustrer certaines des fonctions de base de l'index, nous allons charger 70 000 clients dans MongoDB à partir d'un fichier JSON. Chaque document contient le nom, l'adresse, le numéro de téléphone, les détails de la carte de crédit et les "notes de dossier" des clients. Ces dernières ont été générées à partir de nombres aléatoires.
Ce chargement peut être effectué soit à partir de Mongoimport, soit à partir d'un outil tel que Studio 3T.
Spécifier la collation dans les collections MongoDB
Avant de créer une collection, vous devez tenir compte de la collation, c'est-à-dire de la manière dont la recherche et le tri sont effectués (la collation n'est pas prise en charge avant MongoDB 3.4).
Lorsque vous voyez des chaînes de caractères dans l'ordre, voulez-vous que les minuscules soient triées après les majuscules ou votre tri doit-il ignorer la casse ? Considérez-vous qu'une valeur représentée par une chaîne de caractères est différente en fonction des majuscules ? Comment traiter les caractères accentués ? Par défaut, les collections ont une collation binaire qui n'est probablement pas ce qui est requis dans le monde du commerce.
Pour savoir quelle collation est utilisée, le cas échéant, pour votre collection, vous pouvez utiliser cette commande (ici pour notre collection "Clients").
db.getCollectionInfos({name: 'Customers'})

Cela montre que j'ai défini la collection Clients avec la collation "en".
Si je fais défiler la sortie du shell, je vois que tous les index MongoDB ont la même collation, ce qui est une bonne chose.
Malheureusement, vous ne pouvez pas modifier la collation d'une collection existant déjà. Vous devez créer la collection avant d'ajouter les données.
Voici comment créer une collection 'Customers' avec une collation anglaise. Dans Studio 3T, vous pouvez définir la collation via l'interface utilisateur et l'IntelliShell intégré.
Voici l'onglet Collation de la fenêtre "Ajouter une nouvelle collation" que l'on obtient en cliquant avec le bouton droit de la souris sur le nom de la base de données et en cliquant sur "Ajouter une nouvelle collation...".

Vous pouvez réaliser la même opération dans IntelliShell à l'aide de la commande :
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

Vous pouvez également ajouter des informations de collation à toute recherche, tout tri ou toute comparaison de chaînes de caractères que vous effectuez.
D'après mon expérience, il est plus net, plus sûr et plus facile à modifier si vous le faites au niveau de la collection. Si la collation d'un site 인덱스 ne correspond pas à la collation de la recherche ou du tri que vous effectuez, MongoDB ne peut pas utiliser le site 인덱스.
Si vous importez un document, il est préférable que son ordre naturel soit pré-trié selon votre collation spécifiée dans l'ordre de l'attribut le plus courant 인덱싱된 . La clé primaire est ainsi "groupée", c'est-à-dire que 인덱스 peut avoir moins de blocs de pages à visiter pour chaque consultation de la clé 인덱스 , et le système obtiendra un taux de réponse beaucoup plus élevé.
Comprendre le schéma
Une fois que nous avons chargé l'échantillon de données fictives, nous pouvons visualiser son schéma en examinant simplement le premier document
db.Customers.find({}).limit(1);
Dans Studio 3T, vous pouvez voir cela dans l'onglet Collection:

Index MongoDB pour les requêtes simples
Accélérer une requête très simple
Nous allons maintenant exécuter une simple requête dans notre base de données nouvellement créée afin de trouver tous les clients dont le nom de famille est "Johnston".
Nous souhaitons effectuer une projection sur, ou sélectionner, 'Prénom' et 'Nom de famille', triés par 'Nom de famille'. La ligne "_id" : NumberInt(0), signifie simplement "veuillez ne pas renvoyer l'ID".
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

Une fois que nous nous sommes assurés que la requête fournit le bon résultat, nous pouvons la modifier pour qu'elle fournisse les statistiques d'exécution.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
D'après les statistiques d'exécution de 'Explain', cela prend 59 Ms sur ma machine (ExecutionTimeMillis). Il s'agit d'un COLLSCAN, ce qui signifie qu'il n'y a pas d'index disponible et que Mongo doit donc parcourir toute la collection.
Ce n'est pas nécessairement une mauvaise chose dans le cas d'une collection raisonnablement petite, mais lorsque la taille augmente et que davantage d'utilisateurs accèdent aux données, la collection a moins de chances de tenir dans la mémoire paginée, et l'activité du disque s'accroît.
La base de données ne s'adaptera pas bien si elle est obligée d'effectuer un pourcentage élevé de COLLSCAN. C'est une bonne idée de minimiser les ressources utilisées par les requêtes fréquemment exécutées.
Il est évident que si un index permet de réduire le temps de traitement, il est probable qu'il s'agisse de Nom.Nom de famille.
Commençons donc par cela, en le transformant en index croissant, car nous voulons que le tri soit croissant :
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
Il faut maintenant 4 Ms sur ma machine (ExecutionTimeMillis). Il s'agit d'un IXSCAN (un balayage d'index pour obtenir les clés) suivi d'un FETCH (pour récupérer les documents).
Nous pouvons améliorer ce point car la requête doit obtenir le prénom.
Si nous ajoutons Name.First Name dans la page 인덱스, le moteur de base de données peut utiliser la valeur figurant dans la page 인덱스 plutôt que d'avoir à franchir l'étape supplémentaire consistant à extraire cette valeur de la base de données.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
Grâce à ce système, la requête prend moins de 2 Ms.
Parce que l'index "couvre" la requête, MongoDB a pu faire correspondre les conditions de la requête et renvoyer les résultats en utilisant uniquement les clés de l'index, sans même avoir besoin d'examiner les documents de la collection pour renvoyer les résultats. (Si vous voyez une étape IXSCAN qui n'est pas un enfant d'une étape FETCH, dans le plan d'exécution, c'est que l'index "couvrait" la requête).
Vous remarquerez que notre tri était le type de tri ascendant le plus évident, de A à Z. Nous l'avons spécifié avec un 1 comme valeur pour le tri. Qu'en est-il si le résultat final doit être de Z à A (décroissant), spécifié par -1 ? Aucune différence n'est détectable avec ce petit ensemble de résultats.
Cela semble être un progrès. Mais que se passe-t-il si vous vous trompez d'index ? Cela peut poser des problèmes.
Si vous modifiez l'ordre des deux champs dans le site 인덱스 de manière à ce que Name.First Name précède Name.Last Name, le temps d'exécution passe à 140 Ms, ce qui représente une augmentation considérable.
Cela semble bizarre parce que le 인덱스 a en fait ralenti l'exécution de sorte qu'elle prend plus du double du temps qu'elle a pris avec seulement le 인덱스 primaire par défaut (entre 40 et 60 Ms). MongoDB vérifie certainement les stratégies d'exécution possibles pour en trouver une bonne, mais à moins que vous n'ayez fourni une 인덱스 appropriée, il lui est difficile de sélectionner la bonne.
Qu'avons-nous appris jusqu'à présent ?
Il semblerait que les requêtes simples bénéficient le plus des index qui sont impliqués dans les critères de sélection, et avec la même collation.
Dans notre exemple précédent, nous avons illustré une vérité générale sur les index MongoDB : si le premier champ du site 인덱스 ne fait pas partie des critères de sélection, il n'est pas utile d'exécuter la requête.
Accélérer les requêtes non-SARGables
Que se passe-t-il si nous avons deux critères, dont l'un implique une chaîne de caractères dans la valeur ?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
Nous voulons trouver un client appelé Wiggins qui habite à Rutland. Il faut 50 Ms sans aucun indice à l'appui.
Si nous excluons le nom de la recherche, le temps d'exécution double.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
Si nous introduisons maintenant un composé 인덱스 qui commence par le nom et ajoute ensuite l'adresse, nous constatons que la requête était si rapide que 0 Ms a été enregistré.
En effet, le site 인덱스 a permis à MongoDB de trouver uniquement les 52 Wiggins dans la base de données et d'effectuer la recherche à partir de ces seules adresses. Cela semble suffisant !
Que se passe-t-il si nous inversons les deux critères ? De manière surprenante, le rapport "explain" fait état de 72 Ms.
Il s'agit de deux critères valables spécifiés dans la requête, mais si le mauvais critère est utilisé, la requête est plus qu'inutile, à hauteur de 20 Ms.
La raison de cette différence est évidente. L'index peut empêcher un balayage de toutes les données, mais il ne peut pas améliorer la recherche puisqu'il s'agit d'une expression régulière.
Il existe deux principes généraux.
Une recherche complexe doit réduire autant que possible les candidats à la sélection avec le premier élément de la liste d'index. La "cardinalité" est le terme utilisé pour ce type de sélectivité. Un champ à faible cardinalité, tel que le sexe, est beaucoup moins sélectif que le nom de famille.
Dans notre exemple, le nom de famille est suffisamment sélectif pour être le choix évident du premier champ répertorié sur le site 인덱스, mais peu de requêtes sont aussi évidentes.
La recherche proposée par le premier champ d'un index utilisable doit être SARGable. Il s'agit d'un raccourci pour dire que le champ de l'index doit être SearchARGumentable.
Dans le cas de la recherche du mot "rutland", le terme de recherche n'était pas directement lié au contenu de l'index et à l'ordre de tri de l'index.
Nous avons pu l'utiliser efficacement uniquement parce que nous avons utilisé l'ordre de l'index pour persuader MongoDB d'adopter la meilleure stratégie pour trouver les vingt "Wiggins" potentiels dans la base de données, puis en utilisant la copie de l'adresse complète dans l'index plutôt que le document lui-même.
Il peut alors rechercher ces vingt adresses complètes très rapidement sans même avoir à extraire les données des vingt documents. Enfin, grâce à la clé primaire contenue dans l'index, il peut très rapidement extraire le bon document de la collection.
Inclure un tableau intégré dans une recherche
Essayons une requête un peu plus complexe.
Nous voulons effectuer une recherche à partir du nom de famille et de l'adresse électronique du client.
Notre collection de documents permet à notre "client" d'avoir une ou plusieurs adresses électroniques. Celles-ci se trouvent dans un tableau intégré.
Nous voulons simplement trouver une personne portant un nom de famille particulier, "Barker" dans notre exemple, et une certaine adresse électronique, "[email protected]" dans notre exemple.
Nous voulons renvoyer uniquement l'adresse électronique correspondante et les détails qui vont avec (quand elle a été enregistrée et quand elle est devenue invalide). Nous allons exécuter cette commande à partir du shell et examiner les statistiques d'exécution.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Ce qui donne :
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
Cela nous indique que Cassie Barker a eu l'adresse électronique [email protected] du 11 janvier 2016 au 25 janvier 2018. L'exécution de la requête a pris 240 ms car il n'y avait pas d'index utile (les 40000 documents ont été examinés dans un COLLSCAN).
Nous pouvons créer un index pour faciliter cette tâche :
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
Ce site 인덱스 a permis de réduire le temps d'exécution à 6 ms.
La Nad 인덱스 qui était la seule disponible pour la collection était juste sur le champ Name.Last Name.
Pour l'étape d'entrée, la stratégie IXSCAN a été utilisée et a permis d'obtenir très rapidement 33 documents correspondants, en avançant dans le processus.
Il a ensuite filtré les documents correspondants pour récupérer le tableau EmailAddresses pour l'adresse qui a ensuite été renvoyée dans l'étape de projection. Au total, 3 Ms ont été utilisés, alors que 70 Ms ont été nécessaires.
L'ajout d'autres champs dans l'index n'a pas eu d'effet perceptible. C'est le premier champ de l'index qui détermine le succès.
Et si nous voulions simplement savoir qui utilise une adresse électronique particulière ?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Ici, un index sur le champ emailAddress fait des merveilles. Sans index approprié, il effectue un COLLSCAN qui prend environ 70 Ms sur mon serveur de développement.
Avec un index...
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
... le délai est déjà trop court pour être mesuré.
Vous aurez remarqué que, pour indexer un champ contenant un tableau, MongoDB crée une clé d'indexation pour chaque élément du tableau.
Nous pourrions être encore plus rapides si nous supposions que les adresses électroniques sont uniques (ce n'est pas le cas dans ces données fabriquées; et dans la vie réelle, c'est une supposition dangereuse).
Nous pouvons également utiliser le site 인덱스 pour "couvrir" la récupération du champ "Full Name", de sorte que MongoDB puisse récupérer cette valeur à partir du site 인덱스 plutôt que de la récupérer à partir de la base de données, mais le gain de temps sera minime.
L'une des raisons pour lesquelles les récupérations d'index fonctionnent si bien est qu'elles ont tendance à obtenir de bien meilleurs taux de réussite dans le cache que les balayages de collections complètes. Toutefois, si l'ensemble de la collection peut tenir dans le cache, l'analyse de la collection aura des performances plus proches de celles de l'index.
Utiliser les agrégations
Voyons quels sont les noms les plus populaires dans notre liste de clients, en utilisant une agrégation. Nous allons créer un index à partir de "Nom.Nom de famille".
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
Nous avons donc beaucoup de membres de la famille Snyder dans notre top 10:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
Cela n'a pris que 8 Ms malgré un COLLSCAN, car toute la base de données a pu être conservée dans la mémoire cache.
Il utilise le même plan de requête même si vous effectuez l'agrégation sur un champ non indexé. (Elisha, Eric, Kim et Lee sont les prénoms les plus populaires !)
Je me demande quels sont les prénoms qui ont tendance à attirer le plus de notes sur leur dossier ?
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
Dans mes données fictives, ce sont les personnes appelées Charisse qui obtiennent le plus de notes. Ici, nous savons qu'un COLLSCAN est inévitable car le nombre de notes changera dans un système réel. Certaines bases de données permettent d'indexer les colonnes calculées, mais cela n'est pas utile dans le cas présent.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
Les performances des agrégations peuvent être améliorées par un index car elles peuvent couvrir l'agrégation. Seuls les opérateurs de pipeline $match et $sort peuvent tirer parti d'un index directement, et uniquement s'ils interviennent au début du pipeline.
Le générateur de données SQL a été utilisé pour générer les données de test dans ce tutoriel.
Conclusions
- Lorsqu'on élabore une stratégie d'indexation pour MongoDB, on constate qu'un certain nombre de facteurs doivent être pris en compte, tels que la structure des données, le modèle d'utilisation et la configuration des serveurs de base de données.
- MongoDB n'utilise généralement qu'un seul index lors de l'exécution d'une requête, à la fois pour la recherche et le tri ; et s'il a le choix de la stratégie, il échantillonne les meilleurs index candidats.
- La plupart des collections de données ont des candidats assez performants pour les index, susceptibles de différencier clairement les documents de la collection, et susceptibles d'être fréquents dans les recherches.
- C'est une bonne idée d'être parcimonieux avec les index parce qu'ils constituent un petit coût en termes de ressources. Un autre danger est d'oublier ce qui existe déjà, bien qu'il ne soit heureusement pas possible de créer des index en double dans MongoDB.
- Il est toujours possible de créer plusieurs index composés très proches dans leur constitution. Si un indice n'est pas utilisé, il est préférable de l'abandonner.
- Les index composés sont très efficaces pour soutenir les requêtes. Ils utilisent le premier champ pour effectuer la recherche et utilisent ensuite les valeurs des autres champs pour renvoyer les résultats, plutôt que de devoir récupérer les valeurs dans les documents. Ils prennent également en charge les tris qui utilisent plus d'un champ, à condition qu'ils soient effectués dans le bon ordre.
- Pour que les index soient efficaces pour les comparaisons de chaînes de caractères, ils doivent utiliser la même collation.
- Il est utile de surveiller les performances des requêtes. En plus d'utiliser les valeurs renvoyées par explain(), il est utile de chronométrer les requêtes et de vérifier les requêtes de longue durée en activant le profilage et en examinant les requêtes les plus lentes. Il est en fait étonnamment facile de modifier la vitesse de ces requêtes en fournissant le bon index.
FAQ sur les index MongoDB
Les index ne ralentissent pas les requêtes MongoDB. Cependant, lorsqu'un document est créé, mis à jour ou supprimé, les index associés doivent également être mis à jour, ce qui a un impact sur les performances d'écriture.
Vous devriez éviter l'indexation dans MongoDB lorsque vous avez une petite collection ou lorsque vous avez une collection qui n'est pas fréquemment interrogée.
Étant donné que MongoDB crée un fichier pour chaque 인덱스, un trop grand nombre d'index peut avoir un impact sur les performances. Lorsque le moteur de stockage MongoDB démarre, il ouvre tous les fichiers, de sorte que les performances diminuent s'il y a un nombre excessif d'index.
Double-cliquez sur l'onglet Indexes dans l'arborescence des connexions pour les collections que vous souhaitez comparer, afin d'obtenir deux onglets 인덱스 Manager. Cliquez avec le bouton droit de la souris en haut de l'un des onglets et sélectionnez Diviser verticalement. Les onglets sont affichés côte à côte, ce qui vous permet de comparer les index des deux bases de données.
Exécutez votre requête dans l'onglet Collections et ouvrez l'onglet Expliquer pour voir une représentation visuelle du traitement de la requête par MongoDB. Si la requête a utilisé un 인덱스, vous verrez une fenêtre 인덱스 scan sinon vous verrez une étape Analyse de la collection de la collection. Pour plus d'informations sur l'utilisation de l'onglet Expliquer, voir l'article de la base de connaissances Visual Explain | MongoDB Explain, Visualized (Explication visuelle de MongoDB).
Recherchez la collection dans l'arborescence des connexions et double-cliquez sur la section Indexes pour ouvrir le gestionnaire 인덱스 . Le gestionnaire 인덱스 affiche les informations relatives à la taille de chaque 인덱스 de la collection.
Recherchez la collection dans l'arborescence des connexions. Les index sont répertoriés dans la section Index sous le nom de la collection. Double-cliquez sur un index 인덱스 pour afficher une version en lecture seule de ses détails. Les détails relatifs à la taille et à l'utilisation sont affichés dans l'onglet 인덱스 Manager de l'onglet Collections.
Lorsque MongoDB crée une 인덱스, il verrouille temporairement la collection, ce qui empêche toutes les opérations de lecture et d'écriture sur les données de cette collection. MongoDB crée les métadonnées 인덱스 , une table temporaire de clés et une table temporaire de violations de contraintes. Le verrou sur la collection est ensuite rétrogradé et les opérations de lecture et d'écriture sont autorisées périodiquement. MongoDB analyse les documents de la collection et écrit dans les tables temporaires. Pendant que MongoDB construit le site 인덱스, il y a plusieurs étapes dans le processus où la collection est exclusivement verrouillée. Pour plus de détails sur le processus de construction, voir la page d'accueil de MongoDB pour plus de détails sur le processus de construction. Lorsque le site 인덱스 est construit, MongoDB met à jour les métadonnées du site 인덱스 et libère le verrou.
Dans un environnement de production, si votre collection a une charge d'écriture importante, vous devriez envisager de construire votre 인덱스 pendant les périodes d'opérations réduites, par exemple pendant les périodes de maintenance, afin que les performances ne soient pas affectées et que le temps de construction de 인덱스 soit plus court.
Lorsque vous créez un 인덱스 dans MongoDB, le chiffre 1 indique que vous souhaitez créer le 인덱스 dans l'ordre croissant. Pour créer un 인덱스 dans l'ordre décroissant, vous utilisez -1.
En savoir plus sur les index MongoDB
Vous souhaitez en savoir plus sur les index MongoDB ? Consultez ces articles de la base de connaissances :
Comment optimiser les requêtes MongoDB en utilisant find() et les index
Comment utiliser le profileur MongoDB et explain() pour trouver les requêtes lentes
Visual Explain | MongoDB Explain, Visualized
Article mis à jour par Kirsty Burgess le 03/05/2023
Kirsty est notre rédactrice en chef. Lorsqu'elle ne travaille pas chez 3T, vous pouvez trouver Kirsty en train d'essayer de faire des choses stupides comme la pose du triangle avec des chaussures de ski, ou de mettre le bazar dans la cuisine avec tous les bocaux du placard à épices, ou encore sur la colline derrière sa maison en train de marcher et de regarder les grands bâtiments qui se profilent à l'horizon.






