
Vuoi sapere qual è il modo più veloce per scoprire quali indici hai in una collezione o crearne facilmente di nuovi? Prova indice Manager , dove puoi nascondere e visualizzare gli indici con un semplice clic, eliminando l'attesa per la loro ricostruzione. Visualizza a colpo d'occhio la frequenza di utilizzo degli indici. Puoi persino ottenere un confronto affiancato degli indici su database diversi.

Cosa sono gli indici in MongoDB e perché ne abbiamo bisogno?
Gli indici rendono più efficiente l'interrogazione dei dati. Senza indici, MongoDB esegue una scansione della collezione che legge tutti i documenti della collezione per determinare se i dati corrispondono alle condizioni specificate nella query. Gli indici limitano il numero di documenti che MongoDB legge e con gli indici giusti è possibile migliorare le prestazioni. Gli indici memorizzano il valore di un campo o di un insieme di campi, ordinati in base al valore del campo.
Visualizzazione del indice Manager
Per visualizzare gli indici di una raccolta, individua la raccolta nell'albero delle connessioni ed espandila. Puoi espandere la sezione Indici per visualizzare indice nomi:
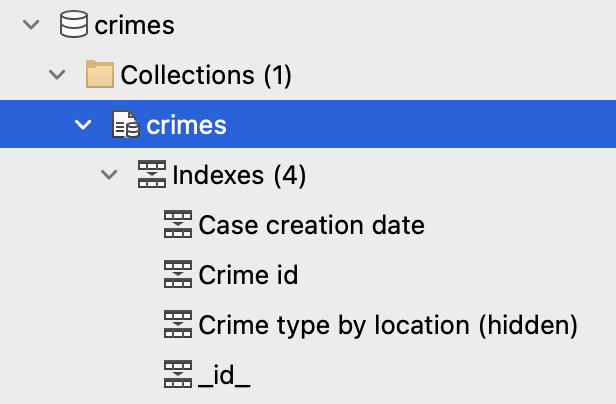
Per visualizzare il indice Manager, fare doppio clic sulla voce Indici nella parte superiore della sezione indici.
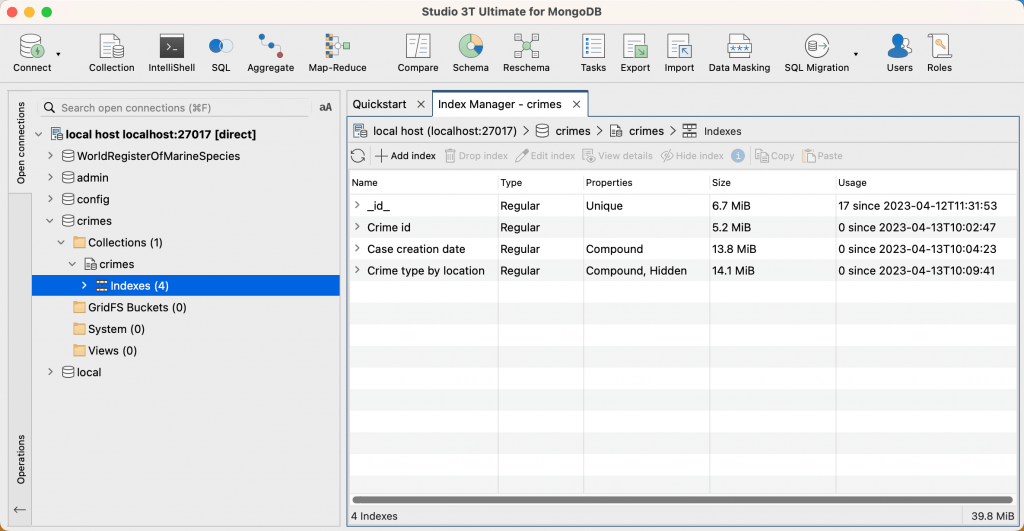
IL indice Il gestore visualizza un elenco di tutti gli indici per la raccolta:
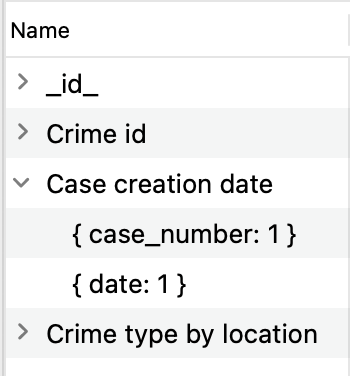
Per visualizzare i campi di 인덱싱된 e il loro ordine, fare clic sulla freccia nel campo Nome:
indice misurare
Per prestazioni ottimali, assicurati che tutti gli indici di tutte le tue collezioni siano presenti nella RAM del server MongoDB per evitare di leggerli dal disco. In alcuni casi, gli indici memorizzano solo i valori recenti nella RAM; per ulteriori informazioni, consulta la documentazione di MongoDB . Il campo Dimensione mostra la dimensione di ciascun indici. indice nella raccolta selezionata. Il totale indice la dimensione (somma di tutti gli indici) della raccolta è mostrata nell'angolo in basso a destra dell' indice Manager.
indice utilizzo
L'utilizzo ti mostra quante volte un indice è stato utilizzato fin dal indice è stato creato o dall'ultimo riavvio del server.
indice Il gestore visualizza le informazioni sull'utilizzo solo se l'utente dispone dei privilegi per il comando MongoDB $indexStats. Per ulteriori informazioni su indice statistiche, vedere la documentazione di MongoDB .
Se un indice non viene utilizzato, dovresti abbandonarlo, per eliminare le spese generali associate alla manutenzione del indice quando i valori dei campi vengono aggiornati e lo spazio su disco.
Aggiungere un indice
Nell'albero delle connessioni, fare clic con il pulsante destro del mouse su una raccolta, quindi selezionare Aggiungi indice .
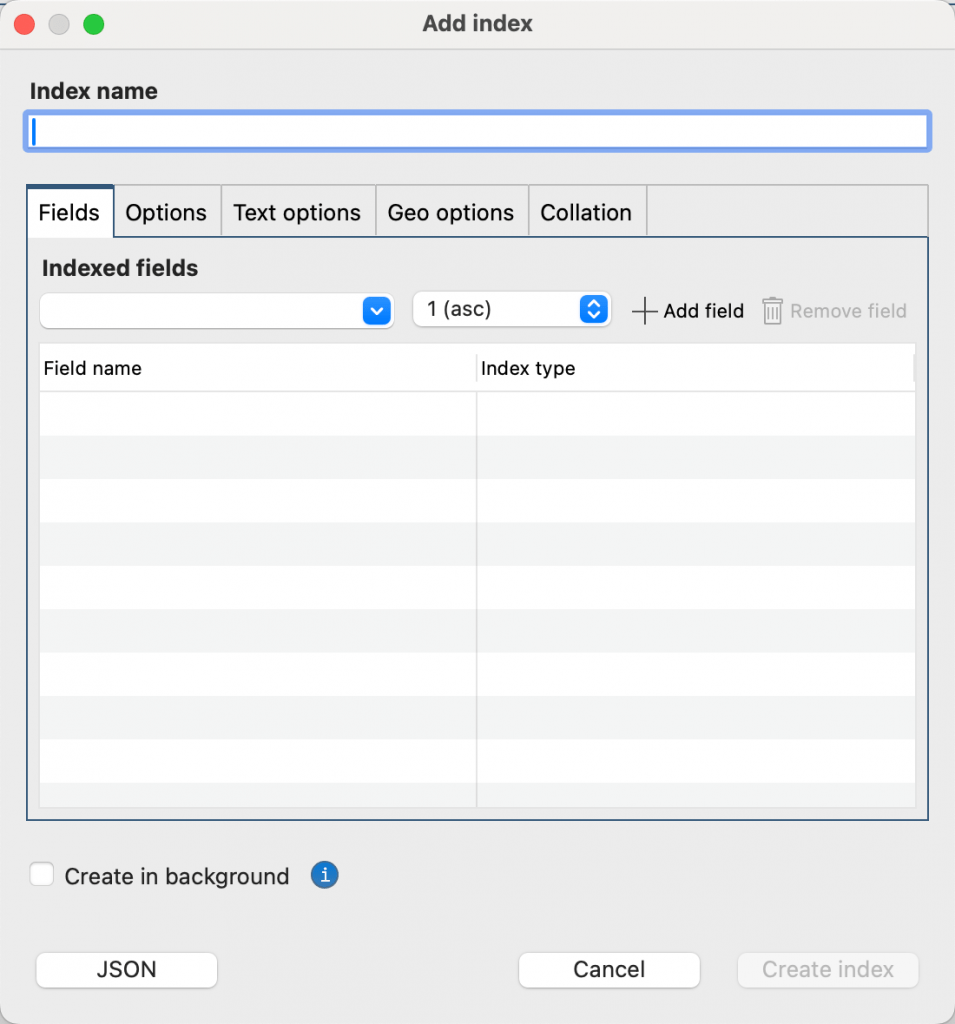
Nella finestra di dialogo Aggiungi indice , digita il nome del tuo indice nella casella del nome indice . Se si lascia vuota la casella del nome indice , Studio 3T crea un nome predefinito indice nome per te, in base ai nomi dei campi che selezioni e al indice tipo.
Aggiungi i campi richiesti al tuo indice Per fare ciò, seleziona il campo dall'elenco Campi indicizzati , quindi seleziona l'ordinamento (1 asc o -1 desc) o il tipo di indice Per saperne di più su indice Per tipi e proprietà, vedere Tipi indice MongoDB e Proprietà indice MongoDB . Fare clic su Aggiungi campo .
Per impostazione predefinita, MongoDB crea indici in primo piano, il che impedisce tutte le operazioni di lettura e scrittura sul database mentre indice costruisce. Ciò si traduce in compatto indice dimensioni e richiede meno tempo per la compilazione. Per consentire alle operazioni di lettura e scrittura di continuare durante la compilazione del indice , seleziona la casella di controllo Crea in background . Questo si traduce in un file meno compatto indice dimensioni e richiede più tempo per essere costruito.
Tuttavia, col tempo le dimensioni convergeranno come se avessi costruito l' indice in primo piano. Per ulteriori informazioni sulla creazione di indici, consultare la documentazione di MongoDB .
Dopo aver terminato di aggiungere campi al tuo indice fare clic su Crea indice .
MongoDB indice tipi
Indici a campo singolo
Quando si specificano campi indicizzati, si applica un ordinamento per ogni campo. In un singolo campo indice , l'ordinamento non è importante perché MongoDB può analizzare i dati in entrambe le direzioni.
Indici composti
Gli indici composti specificano più campi 인덱싱된 . L'ordine in cui si specificano i campi è importante. MongoDB consiglia di seguire la regola ESR (Equality, Search, Range):
- Per prima cosa, aggiungere i campi contro i quali vengono eseguite le query di uguaglianza, ovvero le corrispondenze esatte su un singolo valore
- Successivamente, aggiungere i campi che riflettono l'ordine di ordinamento della query
- Infine, aggiungere i campi per i filtri di intervallo
Indici a più chiavi
Gli indici multichiave vengono utilizzati per i campi che contengono array. È sufficiente specificare il campo che contiene l'array e MongoDB crea automaticamente un indice chiave per ogni elemento dell'array.
Indici di testo
Gli indici di testo supportano ricerche su campi che sono stringhe o array di elementi stringa. È possibile creare un solo testo. indice per collezione. Un testo indice può contenere più campi.
indice versione : ci sono tre versioni, ma la 3 è quella predefinita.
Lingua predefinita: la lingua predefinita è l'inglese. La lingua selezionata determina le regole utilizzate per analizzare le radici delle parole (suffissazione) e definisce le stop words che vengono filtrate. In inglese, ad esempio, le radici dei suffissi includono -ing e -ed, mentre le stop words includono the e a.
Sostituzione della lingua: specificare un nome di campo diverso per sostituire il campo della lingua.
Pesi dei campi: per ogni campo di 인덱싱된 , MongoDB moltiplica il numero di corrispondenze per il peso e somma i risultati. MongoDB utilizza questa somma per calcolare un punteggio per il documento. Selezionare un campo dall'elenco, specificarne il peso nella casella e fare clic su Aggiungi campo. Il peso predefinito del campo è 1.
Indici jolly
Gli indici con caratteri jolly supportano query in cui i nomi dei campi sono sconosciuti, ad esempio in strutture dati arbitrarie definite dall'utente in cui lo schema è dinamico. Un indici senza caratteri jolly indice Supporta solo query sui valori di strutture dati definite dall'utente. Gli indici jolly filtrano tutti i campi corrispondenti.
Per aggiungere un carattere jolly indice su tutti i campi per ogni documento in una raccolta, seleziona $** (tutti i campi) nell'elenco Campi indicizzati :

Indici geospaziali
Indici 2d
Gli indici 2d sono utilizzati per i dati memorizzati come punti su un piano bidimensionale. Gli indici 2d sono destinati alle coppie di coordinate legacy in MongoDB 2.2 e precedenti. Limite inferiore e limite superiore consentono di specificare un intervallo di posizione, invece delle impostazioni predefinite di -180 (incluso) per la longitudine e 180 (non incluso) per la latitudine. Precisione in bit consente di impostare la dimensione in bit dei valori di posizione, fino a 32 bit di precisione. L'impostazione predefinita è di 26 bit, pari a circa 60 centimetri di precisione, quando si utilizza l'intervallo di posizione predefinito.
Sfera 2d
Gli indici 2d sphere supportano le query che calcolano le geometrie su una sfera simile alla terra.
Geo pagliaio
Gli indici geoHaystack migliorano le prestazioni nelle query che utilizzano geometrie piatte. Gli indici geoHaystack sono stati deprecati in MongoDB 4.4 e rimossi in MongoDB 5.0. Gli indici geoHaystack creano bucket di documenti dalla stessa area geografica. È necessario specificare la dimensione del bucket . Ad esempio, una dimensione del bucket pari a 5 crea un indice che raggruppa i valori di posizione che rientrano in 5 unità di longitudine e latitudine specificate. La dimensione del bucket determina anche la granularità del indice .
MongoDB indice proprietà
Indici unici
Gli indici univoci impediscono l'inserimento di documenti se esiste già un documento che contiene quel valore per il campo 인덱싱된 .
Indici sparsi
Gli indici sparsi saltano i documenti che non contengono il campo 인덱싱된 , a meno che il valore del campo non sia nullo. Gli indici sparsi non contengono tutti i documenti dell'insieme.
Indici nascosti
Gli indici nascosti sono nascosti dal piano di query. Questa opzione imposta indice come nascosto al momento della creazione. È possibile impostare indice come non nascosto nel indice Manager, per ulteriori informazioni vedere Nascondere un indice .
Indici TTL
Gli indici TTL sono indici a campo singolo che fanno scadere i documenti e indicano a MongoDB di eliminare i documenti dal database dopo un determinato periodo di tempo. Il campo 인덱싱된 deve essere di tipo data. Inserire il tempo di scadenza in secondi.
Indici parziali
Gli indici parziali includono solo i documenti che soddisfano un'espressione di filtro.
Indici senza distinzione tra maiuscole e minuscole
Gli indici senza distinzione tra maiuscole e minuscole supportano query che ignorano la distinzione tra maiuscole e minuscole durante il confronto di stringhe. L'utilizzo di un indici senza distinzione tra maiuscole e minuscole indice non influisce sui risultati di una query. Per utilizzare il indice , le query devono specificare la stessa collazione.
Per definire indici senza distinzione tra maiuscole e minuscole, è possibile utilizzare la collazione. La collazione consente di specificare regole specifiche della lingua per il confronto delle stringhe, come le regole per gli accenti. È possibile specificare la collazione al momento della raccolta o indice livello. Se una raccolta ha una collazione definita, tutti gli indici ereditano quella raccolta, a meno che non si specifichi una collazione personalizzata.
Per specificare una collazione a indice livello, seleziona la casella Usa collazione personalizzata . L'impostazione Locale è obbligatoria e determina le regole della lingua. Imposta Strength su 1 o 2 per una collazione senza distinzione tra maiuscole e minuscole. Tutte le altre impostazioni sono facoltative e i loro valori predefiniti variano a seconda delle impostazioni locali specificate. Per ulteriori informazioni sulle impostazioni di collazione, consulta la documentazione di MongoDB .
Lasciando cadere un indice
Gli indici non utilizzati influiscono sulle prestazioni di un database perché MongoDB deve mantenerli indice ogni volta che i documenti vengono inseriti o aggiornati. La colonna Utilizzo nel indice Il gestore ti mostra quante volte un indice è stato utilizzato.
Prima di lasciar cadere un indice , dovresti testare quanto bene il indice supporta le query nascondendolo . Se si osserva un calo delle prestazioni, visualizzare il indice , in modo che le query possano utilizzarlo nuovamente.
Non è possibile eliminare l'_id predefinito indice che MongoDB crea quando aggiungi una nuova raccolta.
Per far cadere un indice , esegui una delle seguenti operazioni:
- nell'albero delle connessioni, fare clic con il pulsante destro del mouse su indice e seleziona Elimina indice .
- nell'albero delle connessioni, seleziona indice e premi Ctrl + Backspace (Windows) o fn + Canc (Mac)
- seleziona il indice nel indice Gestore e fare clic sul pulsante Rilascia indice .
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Rimuovi indice .
Per lasciarne cadere più di uno indice , selezionare gli indici richiesti nell'albero delle connessioni, fare clic con il pulsante destro del mouse e selezionare Elimina indici .
Modifica di un indice
Modifica di un indice consente di modificare un esistente indice , ad esempio per modificare i campi indicizzati. Il indice Il manager lascia cadere il indice per te e ricrea il indice con le modifiche da te specificate.
Per modificare un indice , esegui una delle seguenti operazioni per aprire la finestra di dialogo Modifica indice :
- nell'albero delle connessioni, fare clic con il pulsante destro del mouse su indice e seleziona Modifica indice .
- nell'albero delle connessioni, seleziona indice e premere il tasto Invio.
- seleziona il indice nel indice Gestore e fare clic sul pulsante Modifica indice .
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Modifica indice .
Apporta le modifiche desiderate e fai clic su Elimina e ricrea indice .
Nota che se l'unica modifica apportata al indice è nascondere o mostrare il indice , IL indice Il gestore non ha bisogno di eliminare e ricreare il indice , quindi fai clic su Applica modifiche per apportare questa modifica.
Visualizzazione indice dettagli
È possibile visualizzare una versione di sola lettura del indice dettagli in modo da non modificare accidentalmente nessuna delle impostazioni.
Per visualizzare i dettagli di un indice , esegui una delle seguenti operazioni:
- seleziona il indice nel indice Gestore e fare clic sul pulsante Visualizza dettagli .
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Visualizza dettagli .
Nascondere un indice
Puoi nascondere un indice dal piano di query. Nascondere un indice consente di valutare l'impatto dell'abbandono di un indice Nascondere un indice ti evita di dover abbandonare il indice e quindi ricrearlo. È possibile confrontare le prestazioni delle query con e senza l' indice eseguendo la query con indice e poi nascondendo il indice ed eseguendo nuovamente la query.
Quando nascondi un indice , le sue caratteristiche sono ancora valide, ad esempio, gli indici univoci applicano ancora vincoli univoci ai documenti e gli indici TTL fanno ancora scadere i documenti. L'indizio nascosto indice continua a consumare spazio su disco e memoria, quindi se non migliora le prestazioni, dovresti prendere in considerazione l'eliminazione indice .
Gli indici nascosti sono supportati da MongoDB 4.4 o superiore. Assicurarsi che featureCompatibilityVersion sia impostato su 4.4 o superiore.
Per nascondere un indice , esegui una delle seguenti operazioni:
- nell'albero delle connessioni, fare clic con il pulsante destro del mouse su indice e seleziona Nascondi indice . Il indice è contrassegnato come nascosto.
- seleziona il indice nel indice Manager e fare clic sul pulsante Nascondi indice . La colonna Proprietà nella indice Il gestore dimostra che il indice è nascosto.
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Nascondi indice .
Per scoprire un indice , esegui una delle seguenti operazioni:
- nell'albero delle connessioni, fare clic con il pulsante destro del mouse su indice e seleziona Scopri indice .
- seleziona il indice nel indice Gestore e fare clic sul pulsante Nascondi indice .
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Mostra indice .
Copia di un indice
Puoi copiare un indice da un database e incollarne le proprietà in un altro database.
Per copiare un indice , esegui una delle seguenti operazioni:
- nell'albero delle connessioni, fare clic con il pulsante destro del mouse su indice e seleziona Copia indice .
- seleziona il indice nel indice Manager e fare clic sul pulsante Copia .
- fare clic con il pulsante destro del mouse su indice nel indice Gestore e seleziona Copia indice .
Per incollare il indice , nell'albero delle connessioni, fare clic con il pulsante destro del mouse sulla raccolta di destinazione e selezionare Incolla indice .
Per copiare più di uno indice , seleziona gli indici desiderati nell'albero delle connessioni, fai clic con il pulsante destro del mouse e seleziona Copia indici . Nell'albero delle connessioni, fai clic con il pulsante destro del mouse sulla raccolta di destinazione e seleziona Incolla indici .
Usare gli indici di MongoDB (esercitazione)
Sebbene sia possibile memorizzare una grande quantità di informazioni in un database MongoDB, è necessaria una strategia di indicizzazione efficace per ottenere in modo rapido ed efficiente le informazioni necessarie.
In questo tutorial, illustrerò alcune delle basi dell'uso degli indici di MongoDB con semplici query, tralasciando gli aggiornamenti e gli inserimenti.
Questo vuole essere un approccio pratico, con solo la teoria sufficiente per consentire di provare gli esempi. L'intenzione è quella di permettere al lettore di usare solo la shell, anche se è molto più facile usare la GUI di MongoDB che ho usato, Studio 3T.
Un'introduzione agli indici di MongoDB
Quando MongoDB importa i tuoi dati in una raccolta, creerà una chiave primaria che viene applicata da un indice .
Ma non può indovinare gli altri indici necessari, perché non è in grado di prevedere il tipo di ricerche, ordinamenti e aggregazioni che si vorranno fare su questi dati.
Fornisce solo un identificatore unico per ogni documento della collezione, che viene mantenuto in tutti gli indici successivi. MongoDB non consente gli heap. - dati non indicizzati legati tra loro solo da puntatori avanti e indietro.
MongoDB consente di creare indici aggiuntivi simili a quelli presenti nei database relazionali, che richiedono una certa dose di amministrazione.
Come per altri sistemi di database, esistono indici speciali per i dati sparsi, per la ricerca nel testo o per la selezione di informazioni spaziali.
Ogni query o aggiornamento utilizzerà generalmente solo un singolo indice se ce n'è uno adatto disponibile. Un indice può solitamente migliorare l'esecuzione di qualsiasi operazione sui dati, ma non è sempre così.
Potresti essere tentato di provare l'approccio "a raffica", ovvero creare molti indici diversi, in modo da garantire che ce ne sia uno che sia probabilmente adatto, ma lo svantaggio è che ognuno indice utilizza risorse e deve essere gestito dal sistema ogni volta che i dati cambiano.
Se si esagera con gli indici, questi arriveranno a dominare le pagine di memoria e a causare un eccessivo I/O su disco. La cosa migliore è un numero ridotto di indici altamente efficaci.
È probabile che una raccolta di dimensioni ridotte si inserisca nella cache, quindi il lavoro di fornitura degli indici e di messa a punto delle query non sembra avere molta influenza sulle prestazioni complessive.
Tuttavia, quando le dimensioni dei documenti aumentano e il numero di documenti cresce, il lavoro si fa sentire. Il vostro database scalerà bene.
Creare un database di prova
Per illustrare alcuni dei indice In pratica, caricheremo 70.000 clienti in MongoDB da un file JSON . Ogni documento registra il nome, l'indirizzo, il numero di telefono, i dettagli della carta di credito e le note del file dei clienti. Questi sono stati generati da numeri casuali.
Questo caricamento può essere fatto da mongoimport o da uno strumento come Studio 3T.
Specificare la collazione nelle raccolte di MongoDB
Prima di creare una raccolta, è necessario considerare la fascicolazione, il modo in cui vengono eseguite le ricerche e gli ordinamenti (la fascicolazione non è supportata prima di MongoDB 3.4).
Quando vedete le stringhe in ordine, volete vedere le minuscole ordinate dopo le maiuscole o l'ordinamento deve ignorare le maiuscole? Un valore rappresentato da una stringa viene considerato diverso a seconda dei caratteri in maiuscolo? Come ci si comporta con i caratteri accentati? Per impostazione predefinita, le raccolte hanno un ordinamento binario, che probabilmente non è quello richiesto nel mondo del commercio.
Per scoprire l'eventuale collation utilizzata per la propria raccolta, è possibile utilizzare questo comando (qui per la collezione "Clienti").
db.getCollectionInfos({name: 'Customers'})

Questo mostra che ho impostato la collezione Customers con la collazione 'en'.
Se scorro l'output della shell, vedo che tutti gli indici di MongoDB hanno la stessa collation, il che è positivo.
Purtroppo, non è possibile modificare la collation di una raccolta esistente. È necessario creare la collezione prima di aggiungere i dati.
Ecco come creare una raccolta 'Clienti' con una collazione inglese. In Studio 3T, è possibile definire la collazione sia tramite l'interfaccia utente che tramite IntelliShell.
Ecco la scheda di fascicolazione della finestra "Aggiungi nuova fascicolazione", raggiungibile facendo clic con il tasto destro del mouse sul nome del database e facendo clic su "Aggiungi nuova fascicolazione ...".

È possibile ottenere la stessa cosa in IntelliShell utilizzando il comando:
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

In alternativa, è possibile aggiungere informazioni sulla collazione a qualsiasi ricerca, ordinamento o confronto di stringhe.
Nella mia esperienza, è più ordinato, più sicuro e più facile da modificare se lo si fa a livello di raccolta. Se la raccolta di un indice non corrisponde alla collazione della ricerca o all'ordinamento che esegui, quindi MongoDB non può utilizzare indice .
Se si importa un documento, è preferibile che il suo ordine naturale sia preordinato in base alla collazione specificata, in base all'attributo più comunemente indicizzato. Questo rende la chiave primaria "clusterizzata" in quanto indice potrebbe avere meno blocchi di pagina da visitare per ogni indice ricerca chiave e il sistema otterrà un tasso di successo molto più elevato.
Comprendere lo schema
Una volta caricati i dati del mock di esempio, è possibile visualizzarne lo schema semplicemente esaminando il primo documento
db.Customers.find({}).limit(1);
In Studio 3T, è possibile visualizzarlo nella scheda Collezione:

Indici MongoDB per query semplici
Velocizzare una query molto semplice
Ora eseguiamo una semplice query sul nostro database appena creato per trovare tutti i clienti il cui cognome è "Johnston".
Vogliamo eseguire una proiezione o selezionare 'Nome' e 'Cognome', ordinati per 'Cognome'. La riga "_id" : NumberInt(0), significa semplicemente "non restituire l'ID".
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

Una volta accertato che la query restituisce il risultato corretto, possiamo modificarla per restituire le statistiche di esecuzione.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
Secondo le statistiche di esecuzione di "Explain", questo richiede 59 ms sulla mia macchina (ExecutionTimeMillis). Ciò comporta un COLLSCAN, il che significa che non c'è indice disponibile, quindi mongo deve scansionare l'intera collezione.
Questo non è necessariamente un male con una collezione ragionevolmente piccola, ma quando le dimensioni aumentano e più utenti accedono ai dati, è meno probabile che l'insieme entri nella memoria paginata e l'attività su disco aumenterà.
Il database non scalerà bene se è costretto a eseguire una grande percentuale di COLLSCAN. È una buona idea ridurre al minimo le risorse utilizzate dalle query eseguite di frequente.
Bene, è ovvio che se un indice per ridurre il tempo impiegato, è probabile che riguardi Nome.Cognome.
Cominciamo quindi con questo, rendendolo ascendente indice poiché vogliamo che l'ordinamento sia ascendente:
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
Ora ci vogliono 4 Ms sulla mia macchina (ExecutionTimeMillis). Ciò comporta un IXSCAN (un indice scansiona per ottenere le chiavi) seguito da un FETCH (per recuperare i documenti).
Possiamo migliorare questo aspetto perché la query deve ottenere il nome.
Se aggiungiamo il Nome.Nome nel indice , quindi il motore del database può utilizzare il valore in indice anziché dover effettuare il passaggio aggiuntivo di estrarlo dal database.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
Con questo sistema, l'interrogazione richiede meno di 2 Ms.
Poiché il indice 'coperta' la query, MongoDB è stato in grado di abbinare le condizioni della query e restituire i risultati utilizzando solo il indice chiavi; senza nemmeno dover esaminare i documenti dalla raccolta per restituire i risultati. (Se vedi una fase IXSCAN che non è figlia di una fase FETCH, nel piano di esecuzione allora il indice 'copre' la query.)
Si noterà che il nostro ordinamento era l'ovvio ordinamento crescente, A-Z. Lo abbiamo specificato con un 1 come valore per l'ordinamento. Cosa succede se il risultato finale deve essere da Z-A (discendente), specificato da -1? Non c'è alcuna differenza rilevabile con questo breve set di risultati.
Sembra un progresso. Ma cosa succederebbe se avessi... indice sbagliato? Questo può causare problemi.
Se si modifica l'ordine dei due campi nel indice in modo che Nome.Nome venga prima di Nome.Cognome, il tempo di esecuzione sale a 140 Ms, un aumento enorme.
Ciò sembra bizzarro perché il indice ha effettivamente rallentato l'esecuzione in modo che impieghi più del doppio del tempo impiegato con il solo primario predefinito indice (tra 40 e 60 Ms). MongoDB controlla sicuramente le possibili strategie di esecuzione per una buona strategia, ma a meno che tu non abbia fornito un'adeguata indice , è difficile per lui selezionare quello giusto.
Cosa abbiamo imparato finora?
Sembrerebbe che le query semplici traggano il massimo vantaggio dagli indici che sono coinvolti nei criteri di selezione e con la stessa collazione.
Nel nostro esempio precedente, abbiamo illustrato una verità generale sugli indici MongoDB: se il primo campo dell' indice non fa parte dei criteri di selezione, non è utile eseguire la query.
Velocizzare le interrogazioni non SARGable
Cosa succede se abbiamo due criteri, uno dei quali prevede una corrispondenza di stringhe all'interno del valore?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
Vogliamo trovare un cliente di nome Wiggins che vive a Rutland. Ci vogliono 50 ms senza alcun supporto. indice .
Se escludiamo il nome dalla ricerca, il tempo di esecuzione raddoppia.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
Se ora introduciamo un composto indice che inizia con il nome e poi aggiunge l'indirizzo, scopriamo che la query è stata così veloce che sono stati registrati 0 Ms.
Questo perché l'indice ha permesso a MongoDB di trovare solo quei 52 Wiggins nel database e di effettuare la ricerca solo attraverso quegli indirizzi. Questo è abbastanza buono!
Cosa succede se invertiamo i due criteri? Sorprendentemente, il criterio "spiega" riporta 72 Ms.
Sono entrambi criteri validi specificati nella query, ma se si utilizza quello sbagliato la query è inutile, con una perdita di 20 Ms.
Il motivo della differenza è ovvio. indice potrebbe impedire la scansione di tutti i dati ma non può in alcun modo agevolare la ricerca poiché coinvolge un'espressione regolare.
I principi generali sono due.
Una ricerca complessa deve ridurre il più possibile i candidati alla selezione con il primo elemento dell'elenco degli indici. Il termine "cardinalità" indica questo tipo di selettività. Un campo a bassa cardinalità, come il sesso, è molto meno selettivo del cognome.
Nel nostro esempio, il cognome è abbastanza selettivo da essere la scelta ovvia per il primo campo elencato in un indice , ma non ci sono molte domande così ovvie.
La ricerca offerta dal primo campo in modo utilizzabile indice dovrebbe essere SARGable. Questa è una scorciatoia per dire che il indice il campo deve essere S earch ARG umentable.
Nel caso della ricerca della parola "rutland", il termine di ricerca non era direttamente correlato a ciò che era contenuto nel indice e l'ordine di ordinamento del indice .
Siamo stati in grado di utilizzarlo in modo efficace solo perché abbiamo utilizzato il indice per convincere MongoDB ad adottare la strategia migliore per trovare i venti probabili 'Wiggins' nel database e quindi utilizzare la copia dell'indirizzo completo nel indice piuttosto che il documento stesso.
Potrebbe quindi cercare quei venti indirizzi completi molto rapidamente senza nemmeno dover recuperare i dati dai venti documenti. Infine, con la chiave primaria che era nel indice , potrebbe recuperare molto rapidamente il documento corretto dalla raccolta.
Includere un array incorporato in una ricerca
Proviamo a eseguire una query leggermente più complessa.
Vogliamo effettuare una ricerca sul cognome e sull'indirizzo e-mail del cliente.
La nostra raccolta di documenti consente al nostro "cliente" di avere uno o più indirizzi e-mail. Questi si trovano in un array incorporato.
Vogliamo solo trovare una persona con un determinato cognome, "Barker" nel nostro esempio, e un determinato indirizzo e-mail, "[email protected]" nel nostro esempio.
Vogliamo restituire solo l'indirizzo e-mail corrispondente e i suoi dettagli (quando è stato registrato e quando è diventato non valido). Eseguiamo questa operazione dalla shell ed esaminiamo le statistiche di esecuzione.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Che dà:
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
Questo ci dice che Cassie Barker aveva l'indirizzo email [email protected] dall'11 gennaio 2016 al 25 gennaio 2018. Quando abbiamo eseguito la query, ci sono voluti 240 ms perché non c'era alcun indirizzo utile indice (ha esaminato tutti i 40000 documenti in un COLLSCAN).
Possiamo creare un indice per aiutare questo:
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
Questo indice ridotto il tempo di esecuzione a 6 ms.
Il Nad indice l'unica informazione disponibile nella raccolta era nel campo Nome.Cognome .
Per la fase di input è stata utilizzata la strategia IXSCAN, che ha restituito molto rapidamente 33 documenti corrispondenti, andando avanti.
Quindi ha filtrato i documenti corrispondenti per recuperare l'array EmailAddresses per l'indirizzo che è stato poi restituito nella fase di proiezione. In totale sono stati utilizzati 3 Ms, a fronte dei 70 Ms necessari.
L'aggiunta di altri campi nel indice non ha avuto alcun effetto percettibile. Quel primo indice è il campo che determina il successo.
E se volessimo solo sapere chi utilizza un determinato indirizzo e-mail?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Qui, un indice nel campo emailAddress funziona a meraviglia. Senza un indice , esegue un COLLSCAN che impiega circa 70 Ms sul mio server di sviluppo.
Con un indice …
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
... il tempo impiegato è già troppo rapido per essere misurato.
Avrete notato che, per indice un campo che contiene un valore array, MongoDB crea un indice chiave per ogni elemento dell'array.
Potremmo renderlo ancora più veloce se assumessimo che gli indirizzi e-mail sono unici (in questi dati di spoof non lo sono, e nella vita reale è un'ipotesi pericolosa!).
Possiamo anche usare il indice per 'coprire' il recupero del campo 'Nome completo', in modo che MongoDB possa recuperare questo valore da indice anziché recuperarlo dal database, ma la percentuale di tempo risparmiata sarà minima.
Un motivo per cui indice I recuperi funzionano così bene che tendono a ottenere percentuali di successo molto migliori nella cache rispetto alle scansioni di una collezione completa. Tuttavia, se l'intera collezione può essere contenuta nella cache, una scansione di una collezione avrà prestazioni più vicine a indice velocità.
Utilizzo delle aggregazioni
Vediamo quali sono i nomi più popolari nella nostra lista clienti, utilizzando un'aggregazione. Forniremo un indice su “Nome.Cognome”.
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
Quindi, nella nostra top ten, abbiamo molti membri della famiglia Snyder:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
Questo ha richiesto solo 8 Ms nonostante l'esecuzione di un COLLSCAN, perché l'intero database poteva essere conservato nella memoria cache.
Utilizza lo stesso piano di query anche se si esegue l'aggregazione su un campo non indicizzato. (Elisha, Eric, Kim e Lee sono i nomi di battesimo più diffusi).
Mi chiedo quali siano i nomi di battesimo che tendono ad attirare il maggior numero di note sulla loro scheda.
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
Nei miei dati di spoof, sono le persone chiamate Charisse a ricevere il maggior numero di note. In questo caso sappiamo che un COLLSCAN è inevitabile, poiché il numero di note cambierà in un sistema attivo. Alcuni database consentono indici sulle colonne calcolate, ma in questo caso non sarebbero utili.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
Le prestazioni delle aggregazioni possono essere migliorate con un indice perché possono coprire l'aggregazione. Solo gli operatori della pipeline $match e $sort possono sfruttare direttamente un indice, e solo se si trovano all'inizio della pipeline.
Per generare i dati di prova in questa esercitazione è stato utilizzato SQL Data Generator.
Conclusioni
- Quando si sviluppa una strategia di indicizzazione per MongoDB, si scopre che ci sono diversi fattori da prendere in considerazione, come la struttura dei dati, il modello di utilizzo e la configurazione dei server del database.
- MongoDB generalmente ne usa solo uno indice quando esegue una query, sia per la ricerca che per l'ordinamento; e se ottiene una scelta di strategia, campionerà i migliori indici candidati.
- La maggior parte delle raccolte di dati ha alcuni candidati abbastanza buoni per gli indici, che probabilmente differenziano chiaramente tra i documenti della raccolta e che probabilmente sono popolari nell'esecuzione delle ricerche.
- È una buona idea essere parsimoniosi con gli indici, perché hanno un costo minore in termini di risorse. Il pericolo maggiore è quello di dimenticare ciò che è già presente, anche se fortunatamente non è possibile creare indici duplicati in MongoDB.
- È ancora possibile creare diversi indici composti che siano molto simili nella loro costituzione. Se un indice non viene utilizzato, è meglio eliminarlo.
- Gli indici composti sono molto utili per supportare le query. Utilizzano il primo campo per effettuare la ricerca e poi usano i valori degli altri campi per restituire i risultati, invece di doverli ricavare dai documenti. Supportano anche ordinamenti che utilizzano più di un campo, purché nell'ordine giusto.
- Affinché gli indici siano efficaci per i confronti tra stringhe, devono utilizzare la stessa collazione.
- Vale la pena tenere d'occhio le prestazioni delle query. Oltre a utilizzare i valori restituiti da explain() , è utile cronometrare le query e verificare la presenza di query a esecuzione prolungata abilitando la profilazione ed esaminando quelle lente. Spesso è sorprendentemente facile modificare la velocità di tali query fornendo il giusto indice .
Domande frequenti sugli indici di MongoDB
Gli indici non rallentano le query di MongoDB. Tuttavia, quando un documento viene creato, aggiornato o cancellato, anche gli indici associati devono essere aggiornati e ciò influisce sulle prestazioni di scrittura.
Si dovrebbe evitare l'indicizzazione in MongoDB quando si ha una raccolta di piccole dimensioni o quando si ha una raccolta che non viene interrogata frequentemente.
Poiché MongoDB crea un file per ogni indice , troppi indici possono influire sulle prestazioni. All'avvio, il motore di archiviazione di MongoDB apre tutti i file, quindi le prestazioni diminuiscono se il numero di indici è eccessivo.
Fare doppio clic sulla sezione Indici nell'albero delle connessioni per le raccolte che si desidera confrontare, in modo da visualizzare due schede di Gestione indice . Fare clic con il pulsante destro del mouse sulla parte superiore di una delle schede e selezionare Dividi verticalmente . Le schede vengono visualizzate affiancate in modo da poter confrontare gli indici dei due database.
Esegui la query nella scheda "Collections" e apri la scheda "Explain" per visualizzare una rappresentazione visiva di come MongoDB ha elaborato la query. Se la query ha utilizzato un indice , verrà visualizzata una fase di scansione indice , altrimenti una fase di scansione Collection . Per informazioni sull'utilizzo della scheda "Explain", consulta l'articolo della Knowledge Base " Visual Explain | MongoDB Explain, Visualized" .
Trova la raccolta nell'albero delle connessioni e fai doppio clic sulla sezione Indici per aprire la indice Direttore. Il indice Il gestore visualizza le informazioni sulle dimensioni per ciascuna indice sulla collezione.
Trova la raccolta nell'albero delle connessioni. Gli indici sono elencati nella sezione Indici sotto il nome della raccolta. Fai doppio clic su un indice per visualizzare una versione di sola lettura dei suoi dettagli. I dettagli su dimensioni e utilizzo sono visualizzati in indice Scheda Gestore nella scheda Raccolte.
Quando MongoDB crea un indice , blocca temporaneamente la collezione, impedendo tutte le operazioni di lettura e scrittura sui dati in essa contenuti. MongoDB crea metadati indice , una tabella temporanea delle chiavi e una tabella temporanea delle violazioni dei vincoli. Il blocco sulla collezione viene quindi declassato e le operazioni di lettura e scrittura vengono consentite periodicamente. MongoDB analizza i documenti nella collezione e scrive nelle tabelle temporanee. Mentre MongoDB crea l' indice , ci sono diversi passaggi nel processo in cui la collezione viene bloccata in modo esclusivo. Per i dettagli completi del processo di build, consultare la documentazione di MongoDB . Quando l' indice viene creato, MongoDB aggiorna i metadati indice e rilascia il blocco.
In un ambiente di produzione, se la tua raccolta ha un carico di scrittura pesante, dovresti prendere in considerazione la creazione del tuo indice durante i periodi di riduzione delle operazioni, ad esempio durante i periodi di manutenzione, in modo che le prestazioni non vengano influenzate e indice il tempo di costruzione è più breve.
Quando crei un indice in MongoDB, la cifra 1 specifica che si desidera creare il indice in ordine crescente. Per creare un indice in ordine decrescente, si usa -1.
Per saperne di più sugli indici di MongoDB
Siete interessati a saperne di più sugli indici di MongoDB? Consultate questi articoli della knowledge base correlati:
Come ottimizzare le query di MongoDB con find() e gli indici
Come usare MongoDB Profiler e explain() per trovare le query lente
Spiegazione visiva | Spiegazione di MongoDB, visualizzata
Questo articolo è stato pubblicato originariamente da Phil Factor ed è stato successivamente aggiornato.







