
컬렉션에 어떤 인덱스가 있는지 가장 빠르게 찾거나 새 인덱스를 쉽게 만드는 방법을 알고 싶으신가요? 버튼 클릭 한 번으로 인덱스를 숨김 숨김 해제 수 있는 Index 관리자를 사용하면 인덱스가 다시 빌드될 때까지 기다릴 필요가 없습니다. 인덱스가 얼마나 자주 사용되는지 한 눈에 확인하세요. 다른 데이터베이스의 인덱스를 나란히 비교하는 것도 가능합니다.

MongoDB 에서 인덱스란 무엇이며 왜 필요한가요?
인덱스를 사용하면 데이터를 더 효율적으로 쿼리할 수 있습니다. 인덱스가 없을 경우, MongoDB는 컬렉션의 모든 문서를 읽는 컬렉션 스캔을 수행하여 데이터가 쿼리에 지정된 조건과 일치하는지 확인합니다. 인덱스는 MongoDB 에서 읽는 문서의 수를 제한하며, 올바른 인덱스를 사용하면 성능을 향상 시킬 수 있습니다. 인덱스는 필드 또는 필드 집합의 값을 필드 값에 따라 정렬하여 저장합니다.
Index 관리자 표시
컬렉션의 인덱스를 보려면 연결 트리에서 컬렉션을 찾아서 펼칩니다. 인덱스 섹션을 확장하여 인덱스 이름을 볼 수 있습니다:
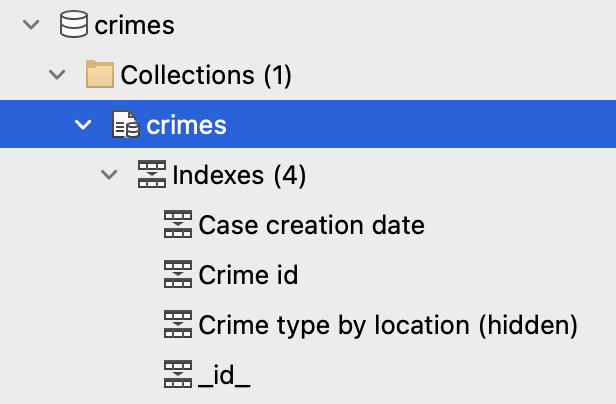
Index 관리자를 표시하려면 인덱스 섹션 상단에 있는 인덱스 항목을 두 번 클릭합니다.
Index 관리자는 컬렉션의 모든 인덱스 목록을 표시합니다:
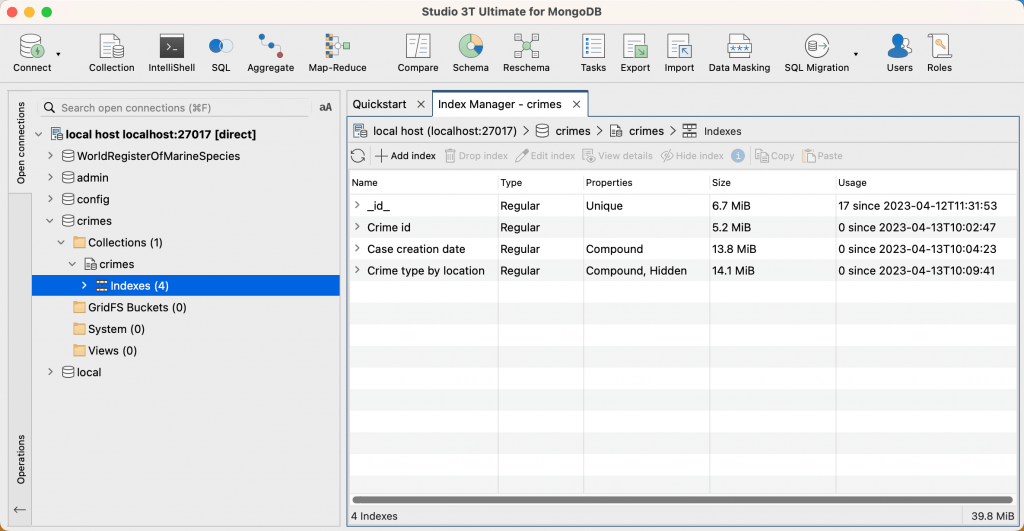
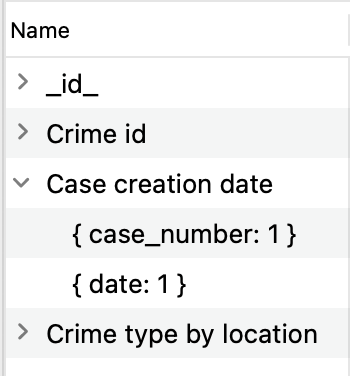
인덱싱된 필드와 정렬 순서를 보려면 이름 필드에서 화살표를 클릭합니다:
Index 크기
최상의 성능을 얻으려면 디스크에서 인덱스를 읽지 않도록 모든 컬렉션의 모든 인덱스가 MongoDB 서버의 RAM에 맞는지 확인하세요. 경우에 따라 인덱스가 RAM에 최근 값만 저장하는 경우가 있습니다. 자세한 내용은 MongoDB 문서를 참조하세요. 크기 필드에는 선택한 컬렉션에 있는 각 인덱스의 크기가 표시됩니다. 컬렉션의 총 인덱스 크기(모든 인덱스의 합계)는 인덱스 관리자의 오른쪽 하단에 표시됩니다.
Index 사용
사용량은 index 생성된 이후 또는 서버가 마지막으로 다시 시작된 이후 index 사용된 횟수를 표시합니다.
Index 관리자는 사용자에게 MongoDB $indexStats 명령에 대한 권한이 있는 경우에만 사용량 정보를 표시합니다. index 통계에 대한 자세한 내용은 MongoDB 문서를 참조하세요.
사용하지 않는 인덱스는 삭제해야, 필드 값이 업데이트될 때 인덱스와 디스크 공간의 유지 관리와 관련된 오버헤드를 없앨 수 있습니다.
인덱스 추가
연결 트리 컬렉션을 마우스 오른쪽 버튼으로 클릭한 다음 Index 추가를 선택합니다.
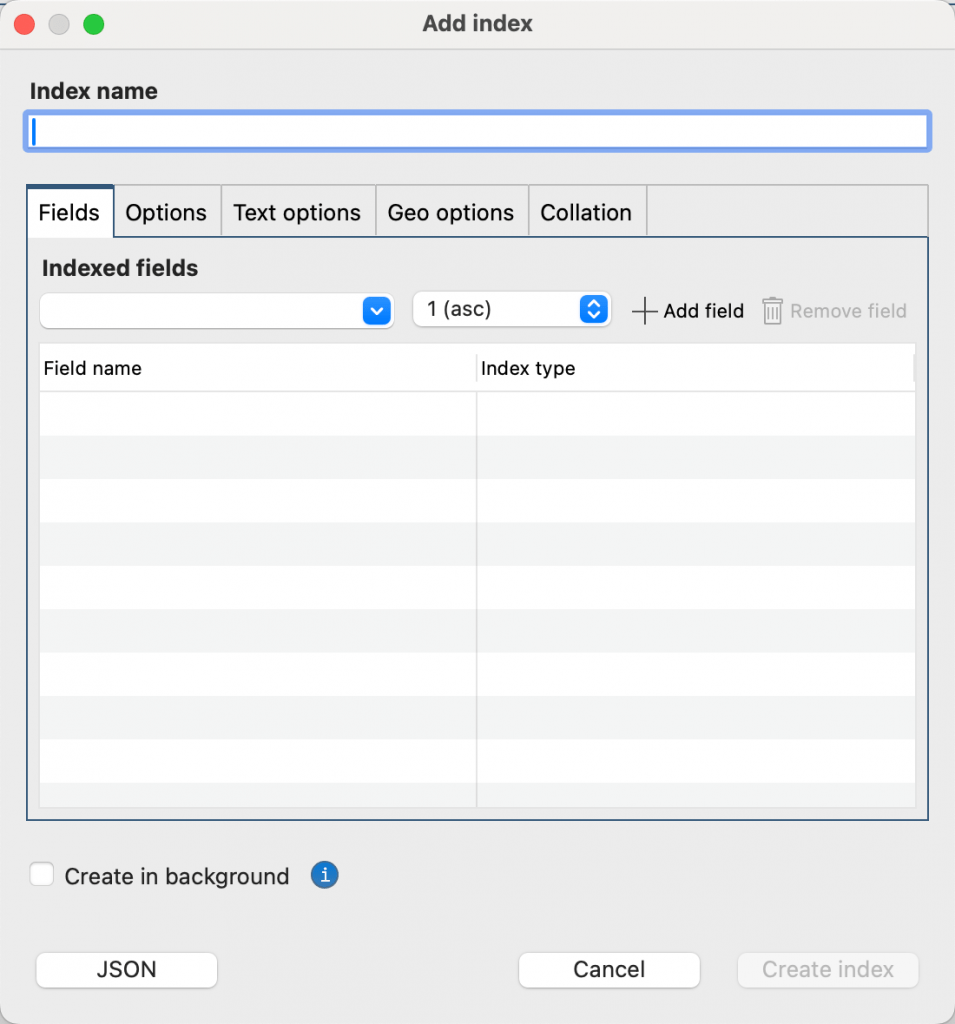
Index 추가 대화 상자의 Index 이름 상자에 index 이름을 입력합니다. Index 이름 상자를 비워 두면 선택한 필드 이름과 index 유형에 따라 Studio 3T 기본 index 이름을 생성합니다.
인덱스에 필수 필드를 추가합니다. 이렇게 하려면 인덱싱된 필드 목록에서 필드를 선택한 다음 정렬 순서(1 asc 또는 -1 desc) 또는 인덱스 유형을 선택합니다. 인덱스 유형 및 속성에 대해 자세히 알아보려면 MongoDB 인덱스 유형 및 MongoDB 인덱스 속성 을 참조하세요. 필드 추가 를 클릭합니다.
기본적으로 MongoDB 인덱스를 포그라운드에서 작성하므로 index 작성되는 동안 데이터베이스에 대한 모든 읽기 및 쓰기 작업이 차단됩니다. 따라서 index 크기가 작아지고 빌드 시간이 단축되며, index 빌드하는 동안 읽기 및 쓰기 작업을 계속하려면 백그라운드에서 만들기 확인란을 선택합니다. 이렇게 하면 index 크기가 작아지고 빌드하는 데 시간이 더 오래 걸립니다.
그러나 시간이 지나면 전경에 index 구축한 것처럼 크기가 수렴됩니다. 인덱스 구축에 대한 자세한 내용은 MongoDB 문서를 참조하세요.
index 필드 추가를 마쳤으면 index 만들기를 클릭합니다.
MongoDB index 유형
단일 필드 인덱스
인덱싱된 필드를 지정할 때 각 필드에 정렬 순서를 적용합니다. 단일 필드 index 정렬 순서는 중요하지 않습니다. MongoDB 양방향으로 데이터를 탐색할 수 있기 때문입니다.
복합 인덱스
복합 인덱스는 여러 인덱싱된 필드를 지정합니다. 필드를 지정하는 순서가 중요합니다. MongoDB는 ESR(동일, 검색, 범위) 규칙을 따르는 것을 권고합니다:
- 먼저, 동일성 쿼리가 실행되는 필드, 즉 단일 값에 대해 정확히 일치하는 필드를 추가합니다.
- 다음으로 쿼리의 정렬 순서를 반영하는 필드를 추가합니다.
- 마지막으로 범위 필터용 필드를 추가합니다.
멀티키 인덱스
멀티키 인덱스는 배열을 포함하는 필드에 사용됩니다. 배열이 포함된 필드만 지정하면 MongoDB 배열의 각 요소에 대한 index 키를 자동으로 생성합니다.
텍스트 인덱스
텍스트 인덱스는 문자열 또는 문자열 요소의 배열인 필드에 대한 검색을 지원합니다. 컬렉션당 하나의 텍스트 index 만들 수 있습니다. 텍스트 index 여러 필드가 포함될 수 있습니다.
Index 버전: 세 가지 버전이 있으며 기본값은 3입니다.
기본 언어: 기본 언어는 영어입니다. 선택한 언어에 따라 단어의 어근(접미사 어간)을 구문 분석하는 데 사용되는 규칙이 결정되고 필터링되는 중지 단어가 정의됩니다. 예를 들어 영어의 경우 접미사 어간에는 -ing 및 -ed가 포함되며, 중지 단어에는 the 및 a가 포함됩니다.
언어 재정의: 언어 필드를 재정의할 다른 필드 이름을 지정합니다.
필드 가중치: 인덱싱된 각 필드에 대해 MongoDB 에서는 일치하는 항목 수에 가중치를 곱하여 결과를 합산합니다. MongoDB 에서는 이 합계를 사용하여 문서에 대한 점수를 계산합니다. 목록에서 필드를 선택하고 상자에 가중치를 지정한 다음 필드 추가 를 클릭합니다. 기본 필드 가중치는 1입니다.
와일드카드 인덱스
와일드카드 인덱스는 스키마가 동적인 임의의 사용자 정의 데이터 구조와 같이 필드 이름을 알 수 없는 경우의 쿼리를 지원합니다. 비와일드카드 index 사용자 정의 데이터 구조의 값에 대한 쿼리만 지원합니다. 와일드카드 인덱스는 일치하는 모든 필드를 필터링합니다.
컬렉션의 각 문서에 대한 모든 필드에 와일드카드 인덱스를 추가하려면 $** (모든 필드) 를 인덱싱된 필드 목록에서 선택합니다.

지리공간 인덱스
2D 인덱스
2차원 인덱스는 2차원 평면에 점으로 저장되는 데이터에 사용됩니다. 2d 인덱스는 MongoDB 2.2 이하의 레거시 좌표 쌍을 위한 것입니다. 하한 및 상한을 사용하면 경도의 경우 기본 설정인 -180(포함), 위도의 경우 180(비포함) 대신 위치 범위를 지정할 수 있습니다. 비트 정밀도를 사용하면 위치 값의 크기를 비트 단위로 설정할 수 있으며, 최대 32비트 정밀도까지 설정할 수 있습니다. 기본 위치 범위를 사용할 때 기본값은 26비트이며, 이는 약 60센티미터의 정밀도입니다.
2D 구체
2D 구 인덱스는 지구와 같은 구에서 기하학을 계산하는 쿼리를 지원합니다.
지리적 건초 더미
geoHaystack 인덱스는 플랫 지오메트리를 사용하는 쿼리의 성능을 개선합니다. geoHaystack 인덱스는 MongoDB 4.4에서 더 이상 사용되지 않으며 MongoDB 5.0에서 제거되었습니다. geoHaystack 인덱스는 동일한 지리적 영역에서 문서의 버킷을 만듭니다. 반드시 버킷 크기를 지정해야 합니다. 예를 들어, 버킷 크기가 5이면 주어진 경도와 위도의 5단위 이내의 위치 값을 그룹화하는 인덱스가 생성됩니다. 버킷 크기에 따라 인덱스 의 세분성도 결정됩니다.
MongoDB index 속성
고유 인덱스
고유 인덱스는 인덱싱된 필드에 해당 값이 포함된 문서가 이미 있는 경우 문서가 삽입되지 않도록 합니다.
희소 인덱스
스파스 인덱스는, 해당 필드 값이 null이 아닌 한, 인덱싱된 필드를 포함하지 않은 문서를 건너뜁니다. 스파스 인덱스가 컬렉션에 있는 모든 문서를 포함하지는 않습니다.
숨겨진 인덱스
숨겨진 인덱스는 쿼리 계획에서 숨겨집니다. 이 옵션은 인덱스 인덱스가 생성될 때 숨김으로 설정합니다. 인덱스 관리자에서 인덱스를 숨김으로 설정할 수 있으며, 자세한 내용은 인덱스 숨김 을 참조하세요.
TTL 인덱스
TTL 인덱스는 문서를 만료하고 설정된 기간이 지나면 MongoDB 에 데이터베이스에서 문서를 삭제하도록 지시하는 단일 필드 인덱스입니다. 인덱싱된 필드는 날짜 유형이어야 합니다. 만료 시간을 초 단위로 입력합니다.
부분 인덱스
부분 인덱스에는 필터 표현식을 충족하는 문서만 포함됩니다.
대소문자를 구분하지 않는 인덱스
대소문자를 구분하지 않는 인덱스는 문자열을 비교할 때 대소문자를 무시하는 쿼리를 지원합니다. 대소문자를 구분하지 않는 index 사용해도 쿼리 결과에는 영향을 주지 않습니다. 이 index 사용하려면 쿼리에서 동일한 콜레이션 지정해야 합니다.
콜레이션 사용하여 대소문자를 구분하지 않는 인덱스를 정의합니다 콜레이션 콜레이션 사용하면 악센트에 대한 규칙과 같은 문자열 비교에 대한 언어별 규칙을 지정할 수 있습니다. 컬렉션 또는 index 수준에서 콜레이션 지정할 수 있습니다. 컬렉션에 정의된 콜레이션 있는 경우 사용자 지정 콜레이션 지정하지 않는 한 모든 인덱스는 해당 콜렉션을 상속합니다 콜레이션
index 수준에서 콜레이션 지정하려면 사용자 지정 콜레이션 사용 상자를 선택합니다. 로캘 설정은 필수이며 언어 규칙을 결정합니다. 대소문자를 구분하지 않는 콜레이션 경우 강도를 1 또는 2로 설정합니다 콜레이션 다른 모든 설정은 선택 사항이며 기본값은 지정한 로캘에 따라 달라집니다. 콜레이션 설정에 대한 자세한 내용은 MongoDB 문서를 참조하세요.
인덱스 드롭하기
사용하지 않는 인덱스는 문서가 삽입되거나 업데이트될 때마다 index 유지해야 하므로 데이터베이스의 성능에 영향을 미칩니다. Index 관리자의 사용 열에는 index 사용된 횟수가 표시됩니다.
index 삭제하기 전에 index 숨겨서 인덱스가 쿼리를 얼마나 잘 지원하는지 테스트해야 합니다. 성능 저하가 관찰되면 index 숨김 해제 쿼리가 다시 사용할 수 있도록 하세요.
새 컬렉션을 추가할 때 MongoDB 생성하는 기본 _id index 삭제할 수 없습니다.
index 삭제하려면 다음 중 하나를 수행합니다:
- 연결 트리 index 마우스 오른쪽 버튼으로 클릭하고 Index 드롭을 선택합니다.
- 연결 트리 index 선택하고 Ctrl + 백스페이스윈도우 또는 fn + 삭제(Mac)를 누릅니다.
- Index 관리자에서 index 선택하고 index 삭제 버튼합니다 버튼
- Index 관리자에서 index 마우스 오른쪽 버튼으로 클릭하고 index 드롭을 선택합니다.
둘 이상의 index 삭제하려면 연결 트리 필요한 인덱스를 선택하고 마우스 오른쪽 버튼을 클릭한 다음 인덱스 삭제를 선택합니다.
인덱스 편집
인덱스를 편집하면 기존 인덱스를 수정할 수 있습니다(예: 인덱싱된 필드 변경). 인덱스 관리자는 인덱스를 삭제하고 지정한 변경 사항이 포함된 인덱스를 다시 생성합니다.
index 편집하려면 다음 중 하나를 수행하여 index 편집 대화 상자를 엽니다:
- 연결 트리 index 마우스 오른쪽 버튼으로 클릭하고 Index 편집을 선택합니다.
- 연결 트리 index 선택하고 Enter 키를 누릅니다.
- 인덱스 관리자에서 인덱스 를 선택하고 인덱스 편집 버튼을 클릭합니다.
- Index 관리자에서 index 마우스 오른쪽 버튼으로 클릭하고 index 편집을 선택합니다.
필요한 사항을 변경하고 삭제 및 index 다시 만들기를 클릭합니다.
index 숨김 또는 숨김 해제 것만 수정하는 경우 Index 관리자는 index 삭제하고 다시 만들 필요가 없으므로 변경 사항 적용을 클릭하여 이 수정 작업을 수행합니다.
index 세부 정보 보기
인덱스 세부 정보를 읽기 전용 버전으로 볼 수 있어 실수로 설정을 변경하는 일이 없도록 합니다.
인덱스에 대한 세부 정보를 확인하려면 다음 중 하나를 수행합니다:
- Index 관리자에서 index 선택하고 세부 정보 보기 버튼합니다.
- 인덱스 관리자에서 인덱스를 마우스 오른쪽 버튼으로 클릭하고 보기 세부 정보 를 선택합니다.
인덱스 숨기기
쿼리 계획에서 index 숨김 수 있습니다. index 숨기면 index 삭제할 때의 영향을 평가할 수 있습니다. index 숨기면 index 삭제한 다음 다시 만들 필요가 없습니다. index 사용하여 쿼리를 실행한 다음 index 숨기고 쿼리를 다시 실행하여 index 있는 경우와 없는 경우의 쿼리 성능을 비교할 수 있습니다.
index 숨김 고유 인덱스는 여전히 문서에 고유한 제약 조건을 적용하고 TTL 인덱스는 여전히 문서를 만료시키는 등, index 기능은 계속 적용됩니다. 숨겨진 index 디스크 공간과 메모리를 계속 소모하므로 성능이 개선되지 않으면 index 삭제를 고려해야 합니다.
숨겨진 인덱스는 MongoDB 4.4 이상부터 지원됩니다. 기능 호환성 버전이 4.4 이상으로 설정되어 있는지 확인합니다.
인덱스를 숨기려면 다음 중 하나를 수행합니다:
- 연결 트리 index 마우스 오른쪽 버튼으로 클릭하고 숨김 Index. index 숨김으로 표시됩니다.
- Index 관리자에서 index 선택하고 숨김 index 버튼 Index 관리자의 속성 열에 index 숨겨져 있음을 표시합니다.
- Index 관리자에서 index 마우스 오른쪽 버튼으로 클릭하고 숨김 index.
index 숨김 해제 다음 중 하나를 수행합니다:
- 연결 트리 index 마우스 오른쪽 버튼으로 클릭하고 숨김 해제 Index.
- Index 관리자에서 index 선택하고 숨김 Index 버튼
- Index 관리자에서 index 마우스 오른쪽 버튼으로 클릭하고 숨김 해제 index.
index 복사하기
한 데이터베이스에서 index 복사하여 다른 데이터베이스에 해당 속성을 붙여넣을 수 있습니다.
index 복사하려면 다음 중 하나를 수행합니다:
- 연결 트리 index 마우스 오른쪽 버튼으로 클릭하고 Index 복사를 선택합니다.
- Index 관리자에서 index 선택하고 복사 버튼합니다.
- Index 관리자에서 index 마우스 오른쪽 버튼으로 클릭하고 index 복사를 선택합니다.
index 붙여넣으려면 연결 트리 대상 컬렉션을 마우스 오른쪽 버튼으로 클릭하고 Index 붙여넣기를 선택합니다.
index 두 개 이상 복사하려면 연결 트리 필요한 인덱스를 선택하고 마우스 오른쪽 단추를 클릭한 다음 인덱스 복사를 선택합니다. 연결 트리 대상 컬렉션을 마우스 오른쪽 버튼으로 클릭하고 인덱스 붙여넣기를 선택합니다.
MongoDB 인덱스 사용(자습서)
MongoDB 데이터베이스에 많은 정보를 저장할 수 있지만, 필요한 정보를 빠르고 효율적으로 얻으려면 효과적인 인덱싱 전략이 필요합니다.
이 튜토리얼에서는 업데이트 및 삽입을 제외하고 간단한 쿼리를 사용하여 MongoDB 인덱스를 사용하는 몇 가지 기본 사항을 살펴보겠습니다.
이 글은 예제를 사용해 볼 수 있을 정도의 이론만 소개하는 실용적인 접근 방식입니다. 의도는 독자가 쉘 만 사용할 수 있도록 하는 것이지만, 제가 사용한 MongoDB GUI에서는 모든 것이 훨씬 더 쉽습니다, Studio 3T.
MongoDB 인덱스에 대한 입문서
MongoDB가 데이터를 컬렉션으로 가져올 때 인덱스에 의해 적용되는 기본 키를 생성합니다.
그러나 이 데이터에 대해 수행하려는 검색, 정렬 및 집계 유형을 예측할 수 있는 방법이 없기 때문에 필요한 다른 인덱스를 추측할 수 없습니다.
컬렉션의 각 문서에 고유 식별자만 제공하며, 이 식별자는 모든 추가 인덱스에 유지됩니다. MongoDB는 힙 을 허용하지 않습니다. - 인덱싱되지 않은 데이터는 앞뒤 포인터로 묶여 있습니다.
MongoDB를 사용하면 관계형 데이터베이스에서 볼 수 있는 디자인과 유사한 추가 인덱스를 만들 수 있는데, 이러한 인덱스는 어느 정도 관리가 필요합니다.
다른 데이터베이스 시스템과 마찬가지로 희소 데이터, 텍스트 검색 또는 공간 정보 선택을 위한 특수 인덱스가 있습니다.
하나의 쿼리 또는 업데이트는 일반적으로 사용 가능한 적절한 index 있는 경우 단일 index 사용합니다. index 일반적으로 모든 데이터 작업의 성능에 도움이 될 수 있지만, 항상 그런 것은 아닙니다.
적합한 인덱스가 있는지 확인하기 위해 다양한 인덱스를 만드는 '산발적' 접근 방식을 시도하고 싶을 수도 있지만, 각 index 리소스를 사용하고 데이터가 변경될 때마다 시스템에서 유지 관리해야 한다는 단점이 있습니다.
인덱스를 과도하게 사용하면 인덱스가 메모리 페이지를 장악하여 과도한 디스크 I/O를 유발하게 됩니다. 소수의 고효율 인덱스가 가장 좋습니다.
작은 컬렉션은 캐시에 들어갈 수 있어 인덱스를 제공하고 쿼리를 튜닝하는 작업이 전체 성능에 많은 영향을 미치는 것으로 보입니다.
그러나 문서 크기가 커지고 문서 수가 증가하면 이 작업이 시작됩니다. 데이터베이스가 잘 확장됩니다.
테스트 데이터베이스 만들기
index 기본 사항을 설명하기 위해 JSON 파일에서 70,000명의 고객을 MongoDB 로드해 보겠습니다. 각 문서에는 고객의 이름, 주소, 전화번호, 신용카드 정보, '파일 메모'가 기록됩니다. 이러한 정보는 난수로 생성되었습니다.
이 로딩은 몽고임포트 또는 Studio 3T 와 같은 도구에서 수행할 수 있습니다.
MongoDB 컬렉션에서 콜레이션 지정하기
컬렉션을 만들기 전에, 검색 및 정렬이 수행되는 방식인 콜레이션 을 고려해야 합니다(콜레이션은 MongoDB 3.4 이전에는 지원되지 않습니다).
문자열을 순서대로 표시할 때 대문자 다음에 소문자가 정렬되기를 원하시나요, 아니면 대소문자를 무시하고 정렬해야 하나요? 문자열로 표시되는 값이 대문자로 된 문자에 따라 달라진다고 생각하시나요? 악센트가 있는 문자는 어떻게 처리하나요? 기본적으로 컬렉션에는 바이너리 콜레이션이 있는데, 이는 상거래에서는 필요하지 않을 수도 있습니다.
컬렉션에 사용되는 콜레이션, 있는 경우 이 명령을 사용하여 확인할 수 있습니다(여기서는 '고객' 컬렉션에 대해).
db.getCollectionInfos({name: 'Customers'})

이것은 'en' 콜레이션으로 Customers 컬렉션을 설정했음을 보여줍니다.
셸 출력을 아래로 스크롤하면 모든 MongoDB 인덱스의 콜레이션이 동일하다는 것을 알 수 있습니다.
안타깝게도 기존 컬렉션의 콜레이션 주소는 변경할 수 없습니다. 데이터를 추가하기 전에 컬렉션을 만들어야 합니다.
다음은 영어 콜레이션이 포함된 '고객' 컬렉션을 만드는 방법입니다. Studio 3T에서는 UI 및 기본 제공 IntelliShell 를 통해 콜레이션을 정의할 수 있습니다.
데이터베이스 이름을 마우스 오른쪽 버튼으로 클릭하면 나타나는 'Add New Collation' 창에 콜레이션 탭이 있습니다.

IntelliShell 에서 다음 명령을 사용하여 동일한 작업을 수행할 수 있습니다:
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

또는 검색, 정렬 또는 문자열 비교에 콜레이션 정보를 추가할 수 있습니다.
제 경험상 컬렉션 수준에서 하는 것이 더 깔끔하고 안전하며 변경하기 쉽습니다. 인덱스의 콜레이션이 검색 또는 정렬의 콜레이션과 일치하지 않는 경우, MongoDB는 인덱스를 사용할 수 없습니다.
문서를 가져오는 경우, 자연스러운 순서가, 지정한 콜레이션에 가장 흔하게 인덱싱된 속성의 순서대로 미리 정렬되어 있다면 가장 좋습니다. 이렇게 하면 인덱스가 모든 인덱스 키를 조회할 때마다 방문해야 하는 페이지 블록 수가 줄어들고 시스템에서 훨씬 더 높은 적중률을 얻을 수 있다는 점에서 기본 키가 '클러스터링'됩니다.
스키마 이해하기
샘플 모의 데이터를 로드한 후 첫 번째 문서만 검토하면 스키마를 확인할 수 있습니다.
db.Customers.find({}).limit(1);
Studio 3T에서는 Colleciton 탭 에서 이를 확인할 수 있습니다:

간단한 쿼리를 위한 MongoDB 인덱스
매우 간단한 쿼리 속도 향상
이제 새로 만든 데이터베이스에 대해 간단한 쿼리를 실행하여 성이 'Johnston'인 모든 고객을 찾겠습니다.
프로젝션을 수행하거나, '성'을 기준으로 정렬된 '이름'과 '성'을 선택하고자 합니다. "_id" : NumberInt(0)는 'ID를 반환하지 마세요'라는 의미입니다.
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

쿼리가 올바른 결과를 반환하는 것이 만족스럽다면 실행 통계를 반환하도록 쿼리를 수정할 수 있습니다.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
'Explain'의 실행 통계에 따르면, 제 컴퓨터에서 이 작업은 59ms가 걸립니다(ExecutionTimeMillis). 여기에는 COLLSCAN이 포함되는데, 이는 사용 가능한 인덱스가 없으므로 MongoDB가 전체 컬렉션을 스캔해야 한다는 것을 의미합니다.
컬렉션이 적당히 작은 경우에는 이것이 반드시 나쁜 것은 아니지만, 크기가 커지고 더 많은 사용자가 데이터에 액세스하면 컬렉션이 페이징 메모리에 들어갈 가능성이 줄어들고 디스크 활동이 증가합니다.
데이터베이스가 많은 비율의 COLLSCAN을 강제로 수행해야 하는 경우 데이터베이스가 제대로 확장되지 않습니다. 자주 실행되는 쿼리가 사용하는 리소스를 최소화하는 것이 좋습니다.
인덱스가 소요 시간을 줄이려면 Name.Last Name을 포함해야 할 것 같습니다.
그런 다음 정렬이 오름차순이 되기를 원하므로 오름차순 index 만들어 보겠습니다:
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
이제 제 컴퓨터에서 4ms가 걸립니다(ExecutionTimeMillis). 여기에는 IXSCAN(키를 가져오기 위한 인덱스 스캔)과 FETCH(문서 검색을 위한)가 포함됩니다.
쿼리에서 이름을 가져와야 하므로 이 문제를 개선할 수 있습니다.
Name.First Name을 index 추가하면 데이터베이스 엔진은 데이터베이스에서 값을 가져오는 추가 단계를 거치지 않고 index 값을 사용할 수 있습니다.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
이 기능을 사용하면 쿼리 시간이 2ms 미만으로 단축됩니다.
인덱스가 쿼리를 '커버'하기 때문에 MongoDB는 결과를 반환하기 위해 컬렉션의 문서를 검사할 필요 없이 인덱스 키만을 사용하여 쿼리 조건을 일치시키고 결과를 반환할 수 있었습니다. (실행 계획에서 FETCH 단계의 하위 항목이 아닌 IXSCAN 단계가 표시되는 경우 인덱스가 쿼리를 '커버'한 것입니다.)
정렬이 명백한 오름차순 정렬인 A-Z라는 것을 알 수 있습니다. 정렬 값으로 1을 지정했습니다. 최종 결과가 -1로 지정된 Z-A(내림차순)의 결과여야 한다면 어떻게 될까요? 이 짧은 결과 집합에서는 감지할 수 있는 차이가 없습니다.
진전된 것처럼 보입니다. 하지만 색인을 잘못 입력했다면 어떻게 될까요? 문제가 발생할 수 있습니다.
index 두 필드의 순서를 변경하여 Name.First Name이 Name.Last Name 앞에 오도록 하면 실행 시간이 최대 140ms로 크게 늘어납니다.
이 index 인해 실제로 실행 속도가 느려져 기본 기본 index (40~60ms)만 사용할 때보다 두 배 이상의 시간이 걸리기 때문에 이상하게 보입니다. MongoDB 좋은 실행 전략을 위해 가능한 실행 전략을 확실히 확인하지만, 사용자가 적절한 index 제공하지 않으면 올바른 인덱스를 선택하기 어렵습니다.
지금까지 배운 것은 무엇일까요?
간단한 쿼리는 선택 기준에 포함되고 동일한 집계가 있는 인덱스에서 가장 많은 이점을 얻을 수 있는 것으로 보입니다.
이전 예제에서는 index 첫 번째 필드가 선택 기준의 일부가 아닌 경우 쿼리를 실행하는 것이 유용하지 않다는 MongoDB 인덱스에 대한 일반적인 진리를 설명했습니다.
non-SARGable 쿼리 속도 향상
두 개의 기준이 있고 그 중 하나가 값 내에 문자열 일치가 있을 경우 어떻게 될까요?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
Rutland에 사는 Wiggins라는 고객을 찾고 싶습니다. 지원 인덱스 없이 50ms가 걸립니다.
검색에서 이름을 제외하면 실제로 실행 시간이 두 배로 늘어납니다.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
이제 이름으로 이어진 다음 주소를 추가하는 복합 index 도입하면 쿼리 시간이 0ms가 기록될 정도로 매우 빠르다는 것을 알 수 있습니다.
인덱스를 통해 MongoDB가 데이터베이스에서 52개의 위긴스만 찾아서 해당 주소로만 검색할 수 있었기 때문입니다. 이 정도면 충분해 보입니다!
두 기준을 바꿔보면 어떤 결과가 나올까요? 놀랍게도 '설명'은 72ms를 보고합니다.
둘 다 쿼리에 지정된 유효한 기준이지만 잘못된 기준을 사용하면 쿼리가 20ms만큼 쓸모없이 느려지게 됩니다.
그 차이는 분명합니다. index 모든 데이터를 스캔하는 것을 막을 수 있지만 정규식을 포함하기 때문에 검색에 도움이 되지 않을 수 있습니다.
일반적으로 두 가지 원칙이 있습니다.
복잡한 검색은 인덱스 목록의 첫 번째 항목으로 선택 후보를 최대한 줄여야 합니다. '카디널리티'는 이러한 종류의 선택성을 나타내는 용어입니다. 성별과 같이 카디널리티가 낮은 필드는 성보다 선택성이 훨씬 떨어집니다.
이 예에서 성은 index 나열되는 첫 번째 필드에 대한 선택이 분명할 정도로 선택적이지만, 그렇게 분명한 쿼리는 많지 않습니다.
사용 가능한 인덱스의 첫 번째 필드에서 제공하는 검색은 SARGable이어야 합니다. 이는 인덱스 필드가 SARG (Search ARGgument able) 이어야한다는 것을 줄여서 말합니다.
'루틀랜드'라는 단어에 대한 검색의 경우, 검색어는 색인에 포함된 내용 및 색인의 정렬 순서와 직접적으로 관련이 없었습니다.
인덱스 순서를 사용하여 데이터베이스에서 20개의 '위긴스'를 찾은 다음 문서 자체가 아닌 인덱스에 있는 전체 주소의 사본을 사용하는 최선의 전략을 사용하도록 MongoDB를 설득했기 때문에 효과적으로 사용할 수 있었습니다.
그러면 20개의 문서에서 데이터를 가져올 필요도 없이 20개의 전체 주소를 매우 빠르게 검색할 수 있습니다. 마지막으로 index 있던 기본 키를 사용하면 컬렉션에서 올바른 문서를 매우 빠르게 가져올 수 있습니다.
검색에 임베디드 배열 포함
조금 더 복잡한 쿼리를 시도해 보겠습니다.
고객의 성 및 이메일 주소로 검색하려고 합니다.
당사의 문서 수집을 통해 '고객'은 하나 이상의 이메일 주소를 가질 수 있습니다. 이러한 이메일 주소는 임베디드 배열로 되어 있습니다.
이 예제에서는 특정 성(예: 'Barker')과 특정 이메일 주소(예: [email protected])를 가진 사람을 찾고자 합니다.
일치하는 이메일 주소와 해당 세부 정보(등록 시점과 무효화된 시점)를 반환하고 싶습니다. 셸에서 이를 실행하고 실행 통계를 조사해 보겠습니다.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
결과
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
이것은 캐시 바커가 2016년 1월 11일부터 2018년 1월 25일까지 [email protected] 이메일 주소를 가지고 있었다는 것을 알려줍니다. 쿼리를 실행했을 때 유용한 인덱스가 없었기 때문에 240ms가 걸렸습니다(COLLSCAN에 있는 4만 개의 문서를 모두 검사했습니다).
이를 돕기 위해 index 만들 수 있습니다:
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
이 index 실행 시간을 6ms로 단축했습니다.
컬렉션에서 사용할 수 있는 유일한 index Name.Last Name 필드에 있는 Nad index .
입력 단계의 경우 IXSCAN 전략을 사용하여 매우 빠르게 33개의 일치하는 문서를 반환하고 앞으로 나아갔습니다.
그런 다음 일치하는 문서를 필터링하여 해당 주소에 대한 EmailAddresses 배열을 가져온 다음 투영 단계에서 반환했습니다. 이전 70ms가 소요된 것과 달리 총 3ms가 사용되었습니다.
인덱스에 다른 필드를 추가해도 눈에 띄는 효과는 없습니다. 첫 번째 인덱스 필드가 성공을 결정짓는 필드입니다.
특정 이메일 주소를 누가 사용하는지 알고 싶다면 어떻게 해야 할까요?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
여기서 emailAddress 필드의 인덱스는 놀라운 효과를 발휘합니다. 적절한 인덱스가 없으면 개발 서버에서 약 70ms가 걸리는 COLLSCAN을 수행합니다.
index...
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
... 이미 소요 시간을 측정하기에는 너무 빠릅니다.
배열 값을 담고 있는 필드를 index 위해 MongoDB 배열의 각 요소에 대해 index 키를 생성한다는 것을 눈치챘을 것입니다.
이메일 주소가 고유하다고 가정하면 더 빠르게 처리할 수 있습니다(이 스푸핑 데이터에서는 고유하지 않으며, 실제 상황에서는 위험한 가정입니다!).
또한 index 사용하여 '전체 이름' 필드의 검색을 '커버'할 수 있으므로 MongoDB 데이터베이스에서 이 값을 검색하는 대신 index 이 값을 검색할 수 있지만 절약되는 시간의 비율은 미미합니다.
인덱스 검색이 잘 작동하는 이유 중 하나는 전체 컬렉션 스캔보다 캐시에서 적중률이 훨씬 더 높기 때문입니다. 그러나 모든 컬렉션이 캐시에 들어갈 수 있으면 컬렉션 스캔이 인덱스 속도와 더 가깝게 수행됩니다.
집계 사용
고객 목록에서 가장 인기 있는 이름이 무엇인지 집계 통해 확인해 보겠습니다 집계"Name.Last Name"에 대한 index 제공하겠습니다.
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
그래서 상위 10위권에는 Snyder 가족이 많이 포함되어 있습니다:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
전체 데이터베이스를 캐시 메모리에 보관할 수 있기 때문에 COLLSCAN을 수행했음에도 불구하고 8ms밖에 걸리지 않았습니다.
인덱스되지 않은 필드에 집계를 수행하더라도 동일한 쿼리 계획을 사용합니다. (Elisha, Eric, Kim과 Lee가 인기 있는 이름입니다!)
어떤 이름이 파일에 가장 많은 메모를 남기는 경향이 있는지 궁금합니다.
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
제 스푸핑 데이터에서 가장 많은 노트를 받은 사람은 Charisse라는 사람입니다. 여기서는 실제 시스템에서 노트 수가 변경되므로 COLLSCAN이 불가피하다는 것을 알고 있습니다. 일부 데이터베이스에서는 계산된 열에 대한 인덱스를 허용하지만 여기서는 도움이 되지 않습니다.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
인덱스는 집계를 포함할 수 있기 때문에 집계의 성능을 개선할 수 있습니다. $match 및 $sort 파이프라인 연산자만 인덱스를 직접 활용할 수 있으며, 파이프라인의 시작 부분에서 발생하는 경우에만 인덱스를 활용할 수 있습니다.
이 튜토리얼에서는 SQL 데이터 생성 기를 사용하여 테스트 데이터를 생성했습니다.
결론
- MongoDB에 대한 인덱싱 전략을 개발할 때 데이터 구조, 사용 패턴, 데이터베이스 서버 구성 등 고려해야 할 여러 가지 요소가 있다는 것을 알게 됩니다.
- MongoDB는 일반적으로 쿼리를 실행할 때 검색과 정렬 모두에 하나의 인덱스만 사용하며, 전략을 선택할 수 있는 경우 최상의 후보 인덱스를 샘플링합니다.
- 대부분의 데이터 컬렉션에는 컬렉션의 문서를 명확하게 구분할 수 있고 검색을 수행할 때 인기가 있을 가능성이 높은 색인 후보가 몇 가지 있습니다.
- 인덱스는 리소스 측면에서 약간의 비용이 들기 때문에 간소하게 사용하는 것이 좋습니다. 더 큰 위험은 이미 있는 인덱스를 잊어버리는 것이지만, 다행히도 MongoDB에서는 중복 인덱스를 생성할 수 없습니다.
- 구성이 매우 유사한 복합 인덱스를 여러 개 만들 수 있습니다. index 사용되지 않는다면 삭제하는 것이 가장 좋습니다.
- 복합 인덱스는 쿼리 지원에 매우 효과적입니다. 복합 인덱스는 문서에서 값을 가져올 필요 없이 첫 번째 필드를 사용하여 검색을 수행한 다음 다른 필드의 값을 사용하여 결과를 반환합니다. 또한 올바른 순서만 맞으면 둘 이상의 필드를 사용하는 정렬도 지원합니다.
- 인덱스가 문자열 비교에 효과적이려면 동일한 콜레이션을 사용해야 합니다.
- 쿼리 성능을 계속 주시할 가치가 있습니다. explain()에서 반환된 값을 사용할 뿐만 아니라, 쿼리 시간을 측정하고, 느린 쿼리를 프로파일링하고 검사하여 장기간 실행되는 쿼리를 확인합니다. 올바른 인덱스를 제공함으로써 이러한 쿼리의 속도를 향상시키는 것은 의외로 쉬운 경우가 많습니다.
MongoDB 인덱스에 대해 자주 묻는 질문
인덱스는 MongoDB 쿼리 속도를 늦추지 않습니다. 하지만 문서가 생성, 업데이트 또는 삭제되면 관련 인덱스도 업데이트되어야 하므로 쓰기 성능에 영향을 미칩니다.
컬렉션이 작거나 자주 조회되지 않는 컬렉션이 있는 경우 MongoDB 에 인덱스를 생성하지 않는 것이 좋습니다.
MongoDB 각 index 대해 파일을 생성하기 때문에 인덱스가 너무 많으면 성능에 영향을 미칠 수 있습니다. MongoDB 스토리지 엔진이 시작되면 모든 파일이 열리므로 인덱스 수가 지나치게 많으면 성능이 저하됩니다.
인덱스를 두 번 클릭합니다. 인덱스 섹션을 두 번 클릭하여 비교하려는 컬렉션의 연결 트리에서 인덱스 관리자 탭이 두 개가 되도록 합니다. 탭 중 하나의 상단을 마우스 오른쪽 버튼으로 클릭하고 세로로 분할. 두 데이터베이스의 인덱스를 비교할 수 있도록 탭이 나란히 표시됩니다.
컬렉션 탭에서 쿼리를 실행하고 설명 탭을 열면 MongoDB 에서 쿼리를 처리한 방법을 시각적으로 확인할 수 있습니다. 쿼리에서 인덱스를 사용한 경우에는 인덱스 스캔 단계 가 표시되며, 그렇지 않으면 컬렉션 스캔이 표시됩니다. 설명 탭 사용에 대한 자세한 내용은 다음 기술 자료 문서를 참조하세요. 시각적 설명 | MongoDB 설명, 시각화됨
연결 트리에서 컬렉션을 찾고 인덱스 섹션을 두 번 클릭하여 인덱스 관리자를 엽니다. 인덱스 관리자는 컬렉션의 각 인덱스에 대한 크기 정보를 표시합니다.
연결 트리에서 컬렉션을 찾습니다 트리. 인덱스는 컬렉션 이름 아래에 있는 인덱스 섹션에 나열됩니다. 인덱스를 두 번 클릭하여 읽기 전용 버전의 세부 정보를 봅니다. 크기 및 사용량 세부 정보는 컬렉션 탭의 인덱스 관리자 탭에 표시됩니다.
MongoDB가 인덱스를 작성할 때 컬렉션을 일시적으로 잠그고 해당 컬렉션의 데이터에 대한 모든 읽기 및 쓰기 작업을 방지합니다. MongoDB가 인덱스 메타데이터, 임시 테이블 키, 제약 조건 위반의 임시 테이블 제약을 생성합니다. 그런 다음 컬렉션의 잠금이 다운그레이드되고 읽기 및 쓰기 작업이 주기적으로 허용됩니다. MongoDB가 컬렉션의 문서를 스캔하고 임시 테이블에 씁니다. MongoDB가 인덱스를 작성하는 동안 컬렉션이 배타적으로 잠기는 몇 가지 단계가 있습니다. 작성 프로세스에 대한 자세한 내용은 MongoDB 문서를 참조하세요. 인덱스가 작성되면 MongoDB 에서 인덱스 메타데이터를 업데이트하고 잠금을 해제합니다.
프로덕션 환경에서 컬렉션에 쓰기 부하가 많은 경우, 유지 관리 기간과 같이, 운영이 줄어드는 시간에 인덱스 작성하는 것을 고려해야 합니다. 그러면 성능에 영향을 주지 않고 인덱스 작성 시간도 단축할 수 있습니다.
MongoDB에서 인덱스를 생성하는 경우 숫자 1은 인덱스를 오름차순으로 생성할 것을 지정합니다. 인덱스를 내림차순으로 만들려면 -1을 사용합니다.
MongoDB 인덱스에 대해 자세히 알아보기
MongoDB 인덱스에 대해 더 자세히 알고 싶으신가요? 관련 기술 자료 문서를 확인해 보세요:
find() 및 인덱스를 사용하여 MongoDB 쿼리를 최적화하는 방법
MongoDB 프로파일러와 explain()을 사용하여 느린 쿼리를 찾는 방법
이 글은 원래 필 팩터에 의해 게시되었으며 이후 업데이트되었습니다.







