Want to know the fastest way to find out what indexes you have on a collection or easily create new ones? Try the Index Manager where you can hide and unhide indexes at the click of a button, eliminating the wait for your indexes to rebuild. See at a glance how often your indexes are being used. You can even get a side-by-side comparison of indexes on different databases.
What are indexes in MongoDB and why do we need them?
Indexes make querying data more efficient. Without indexes, MongoDB performs a collection scan that reads all the documents in the collection to determine if the data matches the conditions specified in the query. Indexes limit the number of documents that MongoDB reads and with the right indexes you can improve performance. Indexes store the value of a field or a set of fields, ordered by the value of the field.
Displaying the Index Manager
To view the indexes on a collection, locate the collection in the connection tree and expand it. You can expand the Indexes section to see the index names:
To display the Index Manager, double-click the Indexes entry at the top of the indexes section.
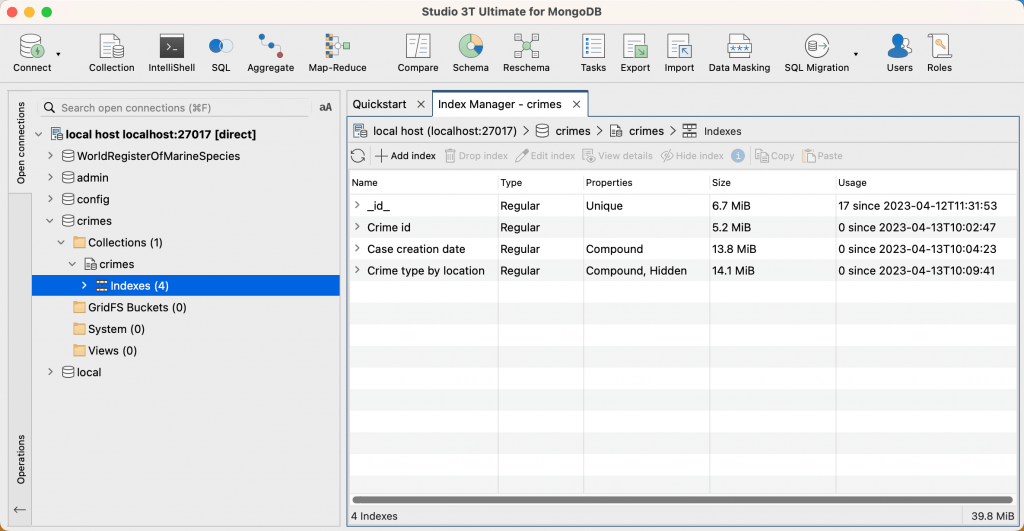
The Index Manager displays a list of all the indexes for the collection:
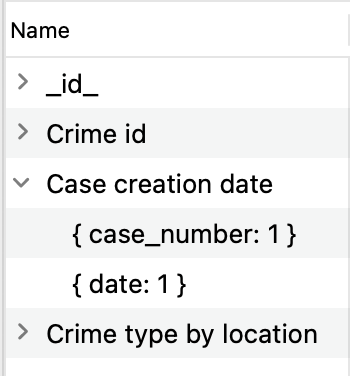
To view the indexed fields and their sort order, click the arrow in the Name field:
Index size
For the best performance, ensure that all your indexes on all your collections fit in RAM on your MongoDB server to avoid reading indexes from disk. In some cases, indexes store only recent values in RAM, for more information see the MongoDB documentation. The Size field shows the size of each index in the selected collection. The total index size (sum of all the indexes) for the collection is shown in the bottom right corner of the Index Manager.
Index usage
Usage shows you how many times an index has been used since the index was created or since the last time the server was restarted.
Index Manager displays usage information only if your user has privileges for the MongoDB $indexStats command. For more information about index statistics, see the MongoDB documentation.
If an index is not being used, you should drop it, to eliminate the overheads associated with maintaining the index when field values are updated and disk space.
Adding an index
In the connection tree, right-click a collection, and then select Add Index.
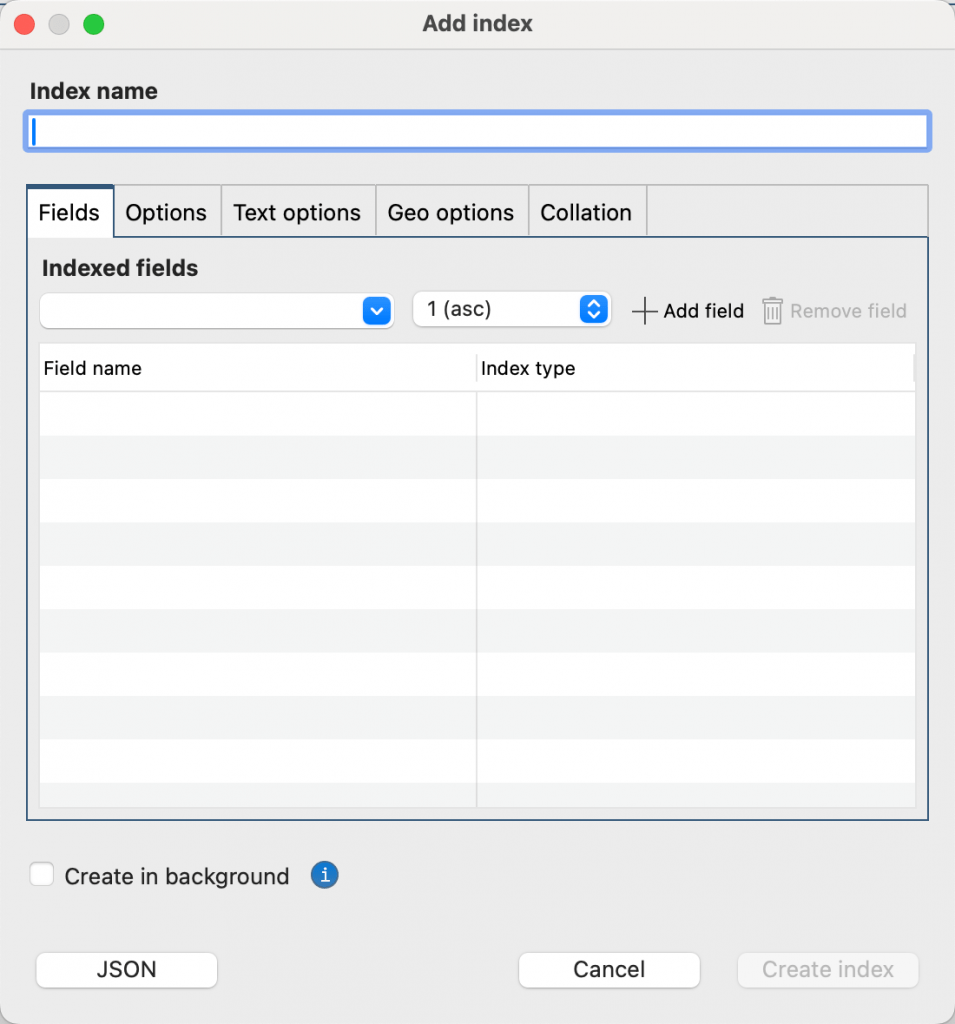
In the Add Index dialog, type the name of your index in the Index name box. If you leave the Index name box empty, Studio 3T creates a default index name for you, based on the names of the fields that you select and the index type.
Add the required fields to your index. To do this, select the field from the Indexed fields list, then select the sort order (1 asc or -1 desc) or the type of index. To find out more about index types and properties, see MongoDB index types and MongoDB index properties. Click Add field.
By default, MongoDB builds indexes in the foreground, which prevents all read and write operations to the database while the index builds. This results in compact index sizes and takes less time to build.To enable read and write operations to continue while building the index, select the Create in background checkbox. This results in less compact index sizes and takes longer to build.
However, over time the size will converge as though you had built the index in the foreground. For more information about building indexes, see the MongoDB documentation.
When you have finished adding fields to your index click Create index.
MongoDB index types
Single field indexes
When you specify indexed fields, you apply a sort order for each field. In a single field index, sort order is not important because MongoDB can traverse the data in both directions.
Compound indexes
Compound indexes specify multiple indexed fields. The order in which you specify the fields is important. MongoDB recommends following the ESR (Equality, Search, Range) rule:
- first, add the fields against which equality queries are run, that is exact matches on a single value
- next, add fields that reflect the sort order of the query
- finally, add fields for range filters
Multikey indexes
Multikey indexes are used for fields that contain arrays. You need only specify the field that contains the array and MongoDB automatically creates an index key for each element in the array.
Text indexes
Text indexes support searches on fields that are strings or an array of string elements. You can create one text index per collection. A text index can contain multiple fields.
Index version: there are three versions with 3 being the default.
Default language: the default language is English. The language you select determines the rules that are used to parse the roots of words (suffix-stemming) and defines the stop words that are filtered out. For example in English, suffix stems include -ing and -ed, and stop words include the and a.
Language override: specify a different field name to override the language field
Field weights: for each indexed field, MongoDB multiplies the number of matches by the weight and sums the results. MongoDB uses this sum to calculate a score for the document. Select a field from the list, specify its weight in the box, and click Add field. The default field weight is 1.
Wildcard indexes
Wildcard indexes support queries where the field names are unknown, for example in arbitrary user-defined data structures where the schema is dynamic. A non-wildcard index supports only queries on the values of user-defined data structures. Wildcard indexes filter all matching fields.
To add a wildcard index on all fields for each document in a collection, select $** (all fields) in the Indexed fields list:

Geospatial indexes
2d indexes
2d indexes are used for data that is stored as points on a two-dimensional plane. 2d indexes are intended for legacy coordinate pairs in MongoDB 2.2 and earlier. Lower bound and Upper bound enables you to specify a location range, instead of the default settings of -180 (inclusive) for longitude and 180 (non-inclusive) for latitude. Bit precision enables you to set the size in bits of the location values, up to 32 bits of precision. The default is 26 bits, which is approximately 60 centimeters of precision, when using the default location range.
2d sphere
2d sphere indexes support queries that calculate geometries on an earth-like sphere.
Geo haystack
geoHaystack indexes improve performance on queries that use flat geometry. geoHaystack indexes were deprecated in MongoDB 4.4 and removed in MongoDB 5.0. geoHaystack indexes create buckets of documents from the same geographic area. You must specify the Bucket size. For example, a bucket size of 5 creates an index that groups location values that are within 5 units of the given longitude and latitude. The bucket size also determines the granularity of the index.
MongoDB index properties
Unique indexes
Unique indexes prevent documents from being inserted if there is already a document which contains that value for the indexed field.
Sparse indexes
Sparse indexes skip over documents that do not contain the indexed field, unless the value of the field is null. Sparse indexes do not contain all the documents in the collection.
Hidden indexes
Hidden indexes are hidden from the query plan. This option sets the index as hidden when it is created. You can set the index as unhidden in the Index Manager, see Hiding an index for more information.
TTL indexes
TTL indexes are single field indexes that expire documents and instruct MongoDB to delete documents from the database after a set period of time. The indexed field must be a date type. Enter the expiry time in seconds.
Partial indexes
Partial indexes include only the documents that meet a filter expression.
Case insensitive indexes
Case-insensitive indexes support queries that ignore case when comparing strings. Using a case insensitive index does not affect the results of a query. To use the index, queries must specify the same collation.
You define case-insensitive indexes using collation. Collation allows you to specify language-specific rules for string comparison, such as rules for accents. You can specify collation at collection or index level. If a collection has a defined collation, all indexes inherit that collection unless you specify a custom collation.
To specify a collation at index level, select the Use custom collation box. The Locale setting is mandatory and determines language rules. Set Strength to 1 or 2 for a case-insensitive collation. All other settings are optional and their defaults vary depending on the locale you specify. For more information about collation settings, see the MongoDB documentation.
Dropping an index
Unused indexes impact the performance of a database because MongoDB has to maintain the index whenever documents are inserted or updated. The Usage column in the Index Manager shows you how many times an index has been used.
Before you drop an index, you should test how well the index is supporting queries by hiding it. If you observe a decrease in performance, unhide the index, so that queries can use it again.
You cannot drop the default _id index that MongoDB creates when you add a new collection.
To drop an index, do one of the following:
- in the connection tree, right-click the index and select Drop Index.
- in the connection tree, select the index and press Ctrl + Backspace (Windows) or fn + Delete (Mac)
- select the index in the Index Manager and click the Drop index button.
- right-click the index in the Index Manager and select Drop index.
To drop more than one index, select the required indexes in the connection tree, right-click and select Drop Indexes.
Editing an index
Editing an index allows you to modify an existing index, for example to change the indexed fields. The Index Manager drops the index for you and recreates the index with the changes that you specified.
To edit an index, do one of the following to open the Edit index dialog:
- in the connection tree, right-click the index and select Edit Index.
- in the connection tree, select the index and press the Enter key.
- select the index in the Index Manager and click the Edit index button.
- right-click the index in the Index Manager and select Edit index.
Make the required changes and click Drop and recreate index.
Note that if the only modification you make to the index is to hide or unhide the index, the Index Manager does not need to drop and recreate the index, so you click Apply changes to make this modification.
Viewing index details
You can view a read-only version of the index details so that you don’t accidentally change any of the settings.
To view the details for an index, do one of the following:
- select the index in the Index Manager and click the View details button.
- right-click the index in the Index Manager and select View details.
Hiding an index
You can hide an index from the query plan. Hiding an index allows you to evaluate the impact of dropping an index. Hiding an index saves you from having to drop the index and then creating it again. You can compare the performance of queries with and without the index by running the query with the index and then hiding the index and running the query again.
When you hide an index, its features still apply, for example, unique indexes still apply unique constraints to documents and TTL indexes still expire documents. The hidden index continues to consume disk space and memory, so if it does not improve performance, you should consider dropping the index.
Hidden indexes are supported from MongoDB 4.4 or greater. Ensure featureCompatibilityVersion is set to 4.4 or greater.
To hide an index, do one of the following:
- in the connection tree, right-click the index and select Hide Index. The index is marked as hidden.
- select the index in the Index Manager and click the Hide index button. The Properties column in the Index Manager shows that the index is hidden.
- right-click the index in the Index Manager and select Hide index.
To unhide an index, do one of the following:
- in the connection tree, right-click the index and select Unhide Index.
- select the index in the Index Manager and click the Hide Index button.
- right-click the index in the Index Manager and select Unhide index.
Copying an index
You can copy an index from one database and paste its properties into another database.
To copy an index, do one of the following:
- in the connection tree, right-click the index and select Copy Index.
- select the index in the Index Manager and click the Copy button.
- right-click the index in the Index Manager and select Copy index.
To paste the index, in the connection tree, right-click the target collection, and select Paste Index.
To copy more than one index, select the required indexes in the connection tree, right-click and select Copy Indexes. In the connection tree, right-click the target collection, and select Paste Indexes.
Using MongoDB Indexes (Tutorial)
Although it is possible to store a great deal of information in a MongoDB database, you need an effective indexing strategy to quickly and efficiently get the information you need from it.
In this tutorial, I’ll run through some of the basics of using MongoDB indexes with simple queries, leaving aside updates and inserts.
This is intended to be a practical approach with only enough theory to allow you to try out the examples. The intention is to allow the reader to use just the shell, though it is all a lot easier in the MongoDB GUI that I used, Studio 3T.
A primer on MongoDB indexes
When MongoDB imports your data into a collection, it will create a primary key that is enforced by an index.
But it can’t guess the other indexes you’d need because there is no way that it can predict the sort of searches, sorting and aggregations that you’ll want to do on this data.
It just provides a unique identifier for each document in your collection, which is retained in all further indexes. MongoDB doesn’t allow heaps. – unindexed data tied together merely by forward and backward pointers.
MongoDB allows you to create additional indexes that are similar to the design of those found in relational databases, and these need a certain amount of administration.
As with other database systems, there are special indexes for sparse data, for searching through text or for selecting spatial information.
Any one query or update will generally use only a single index if there is a suitable one available. An index can usually help the performance of any data operation, but this isn’t always the case.
You may be tempted to try the ‘scattergun’ approach – creating many different indexes, so as to ensure that there will be one that is likely to be suitable – but the downside is that each index uses resources and needs to be maintained by the system whenever the data changes.
If you overdo indexes, they will come to dominate the memory pages and lead to excessive disk I/O. A small number of highly-effective indexes are best.
A small collection is likely to fit in cache so the work of providing indexes and tuning queries will seem to have much influence on overall performance.
However, as document size increases, and the number of documents grow, that work kicks in. Your database will scale well.
Creating a test database
To illustrate some of the index basics, we will load 70,000 customers into MongoDB from a JSON file. Each document records the customers’ name, addresses, phone numbers, credit card details, and ‘file notes’. These have been generated from random numbers.
This loading can be done either from mongoimport, or from a tool such as Studio 3T.
Specifying collation in MongoDB collections
Before you create a collection, you need to consider collation, the way that searching and sorting is performed (collation is not supported before MongoDB 3.4).
When you see strings in order, do you want to see lower-case sorted after uppercase, or should your sorting ignore case? Do you consider a value represented by a string to be different according to the characters that are in capitals? How do you deal with accented characters? By default, collections have a binary collation which is probably not what is required in the world of commerce.
To find out what collation, if any, is used for your collection, you can use this command (here for our ‘Customers’ collection.)
db.getCollectionInfos({name: 'Customers'})

This shows that I’ve set the Customers collection with the ‘en’ collation.
If I scroll down the shell output, I’ll see that all the MongoDB indexes have the same collation, which is good.
Unfortunately, you can’t change the collation of an existing collection. You need to create the collection before adding the data.
Here is how you create a ‘Customers’ collection with an English collation. In Studio 3T, you can define the collation via the UI as well as the built-in IntelliShell.
Here is the collation tab of the ‘Add New Collation’ window that is reached by right-clicking the database name, and clicking ‘Add New Collation …’

You can achieve the same thing in IntelliShell using the command:
db.createCollection("Customers", {collation:{locale:"en",strength:1}})

As an alternative, you can add collation information to any search, sort or string comparison you do.
In my experience, it is neater, safer and easier to change if you do it at the Collection level. If the collation of an index doesn’t match the collation of the search or sort that you do, then MongoDB can’t use the index.
If you are importing a document, it is best if their natural order is pre-sorted to your specified collation in the order of the most commonly indexed attribute. This makes the primary key ‘clustered’ in that the index may have fewer page blocks to visit for every index key lookup, and the system will get a much higher hit rate.
Understanding the schema
Once we have loaded the sample mock data, we can view its schema simply by examining the first document
db.Customers.find({}).limit(1);
In Studio 3T, you can view this within the Collection Tab:

MongoDB indexes for simple queries
Speeding up a very simple query
We will now execute a simple query against our newly-created database to find all customers whose surname is ‘Johnston’.
We wish to perform a projection over, or select, ‘First Name‘ and ‘Last Name’, sorted by ‘Last Name’. The “_id” : NumberInt(0), line just means ‘please don’t return the ID’.
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
});

Once we are happy that the query is returning the correct result, we can modify it to return the execution stats.
use customers;
use customers;
db.Customers.find({
"Name.Last Name" : "Johnston"
}, {
"_id" : NumberInt(0),
"Name.First Name" : NumberInt(1),
"Name.Last Name" : NumberInt(1)
}).sort({
"Name.Last Name" : NumberInt(1)
}).explain("executionStats");
According to the execution stats of ‘Explain’, this takes 59 Ms on my machine (ExecutionTimeMillis). This involves a COLLSCAN, meaning that there is no index available, so mongo must scan the entire collection.
This isn’t necessarily a bad thing with a reasonably small collection, but as the size increases and more users access the data, the collection is less likely to fit in paged memory, and disk activity will increase.
The database won’t scale well if it is forced to do a large percentage of COLLSCANs. It is a good idea to minimize the resources used by frequently-run queries.
Well, it is obvious that if an index is going to reduce the time taken, it is likely to involve Name.Last Name.
Let’s start with that then, making it an ascending index as we want the sort to be ascending:
db.Customers.createIndex( {"Name.Last Name" : 1 },{ name: "LastNameIndex"} )
It now takes 4 Ms on my machine (ExecutionTimeMillis). This involves an IXSCAN (an index scan to get keys) followed by a FETCH (for retrieving the documents).
We can improve on this because the query has to get the first name.
If we add the Name.First Name into the index, then the database engine can use the value in the index rather than having the extra step of taking it from the database.
db.Customers.dropIndex("LastNameIndex")
db.Customers.createIndex( { "Name.Last Name" : 1,"Name.First Name" : 1 },
{ name: "LastNameCompoundIndex"} )
With this in place, the query takes less than 2 Ms.
Because the index ‘covered’ the query, MongoDB was able to match the query conditions and return the results using only the index keys; without even needing to examine documents from the collection to return the results. (If you see an IXSCAN stage that is not a child of a FETCH stage, in the execution plan then the index ‘covered’ the query.)
You’ll notice that our sort was the obvious ascending sort, A-Z. We specified that with a 1 as the value for the sort. What if the final result needs to be from Z-A (descending) specified by -1? No detectable difference with this short result set.
This seems like progress. But what if you got the index wrong? That can cause problems.
If you change the order of the two fields in the index so that the Name.First Name comes before Name.Last Name, the execution time shoots up to 140 Ms, a huge increase.
This seems bizarre because the index has actually slowed the execution down so that it takes over double the time it took with just the default primary index (between 40 and 60 Ms). MongoDB certainly checks the possible execution strategies for a good one, but unless you have provided a suitable index, it is difficult for it to select the right one.
So what have we learned so far?
It would seem that simple queries benefit most from indexes that are involved in the selection criteria, and with the same collation.
In our previous example, we illustrated a general truth about MongoDB indexes: if the first field of the index isn’t part of the selection criteria, it isn’t useful to execute the query.
Speeding up unSARGable queries
What happens if we have two criteria, one of which involves a string match within the value?
use customers;
db.Customers.find({
"Name.Last Name" : "Wiggins",
"Addresses.Full Address" : /.*rutland.*/i
});
We want to find a customer called Wiggins who lives in Rutland. It takes 50 Ms without any supporting index.
If we exclude the name from the search, the execution time actually doubles.
use customers;
db.Customers.find({
"Addresses.Full Address" : /.*rutland.*/i
});
If we now introduce a compound index that leads with the name and then adds the address, we find that the query was so quick that 0 Ms was recorded.
This is because the index allowed MongoDB to find just those 52 Wiggins in the database and do the search through just those addresses. This seems good enough!
What happens if we then switch the two criteria around? Surprisingly, the ‘explain’ reports 72 Ms.
They are both valid criteria specified in the query, but if the wrong one is used the query is worse than useless to the tune of 20 Ms.
The reason for the difference is obvious. The index might prevent a scan through all the data but cannot possibly help the search since it involves a regular expression.
There are two general principles here.
A complex search should reduce the selection candidates as much as possible with the first item in the list of indexes. ‘Cardinality’ is the term used for this sort of selectivity. A field with low cardinality, such as gender is far less selective than surname.
In our example, the surname is selective enough to be the obvious choice for the first field that is listed in an index, but not many queries are that obvious.
The search offered by the first field in a usable index should be SARGable. This is shorthand for saying that the index field must be Search ARGumentable.
In the case of the search for the word ‘rutland’, the search term did not relate directly to what was in the index and the sort order of the index.
We were able to use it effectively only because we used the index order to persuade MongoDB into the best strategy of finding the twenty likely ‘Wiggins’s in the database and then using the copy of the full address in the index rather than the document itself.
It could then search those twenty full addresses very rapidly without even having to fetch the data from the twenty documents. Finally, with the primary key that was in the index, it could very rapidly fetch the correct document from the collection.
Including an embedded array in a search
Let’s try a query that is very slightly more complex.
We want to search on customer’s last name and email address.
Our collection of documents allows our ‘customer’ to have one or more email addresses. These are in an embedded array.
We just want to find someone with a particular last name, ‘Barker’ in our example, and a certain email address, ‘[email protected] in our example.
We want to return just the matching email address and its details (when it was registered and when it became invalid). We’ll execute this from the shell and examine the execution stats.
db.Customers.find({
"Name.Last Name" : "Barker",
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Which gives:
{ "Full Name" : "Mr Cassie Gena Barker J.D.",
"EmailAddresses" : [ { "EmailAddress" : "[email protected]",
"StartDate" : "2016-05-02", "EndDate" : "2018-01-25" } ] }
This tells us that Cassie Barker had the email address [email protected] from 11th Jan 2016 to the 25th January 2018. When we ran the query, it took 240 ms because there was no useful index (it examined all 40000 documents in a COLLSCAN).
We can create an index to help this:
db.Customers.createIndex( { "Name.Last Name" : 1 },{ name: "Nad"} );
This index reduced the execution time to 6ms.
The Nad index that was the only one available to the collection was just on the Name.Last Name field.
For the Input stage, the IXSCAN strategy was used and very rapidly returned 33 matching documents, moving forwards.
It then filtered those matching documents to fetch the EmailAddresses array for the address which was then returned in the projection stage. A total of 3 Ms was used, in contrast to the 70 Ms that it took.
The addition of other fields in the index had no perceptible effect. That first index field is the one that determines success.
What if we just wanted to know who was using a particular email address?
db.Customers.find({
"EmailAddresses.EmailAddress" : "[email protected]"
}, {
"_id" : NumberInt(0),
"EmailAddresses.$.EmailAddress" : NumberInt(1),
"Full Name" : NumberInt(1)
});
Here, an index on the emailAddress field works wonders. Without a suitable index, it does a COLLSCAN which takes around 70 Ms on my dev server.
With an index…
db.Customers.createIndex( { "EmailAddresses.EmailAddress" : 1 },{ name: "AddressIndex"} )
… the time taken is already too quick to measure.
You’ll have noticed that, to index a field that holds an array value, MongoDB creates an index key for each element in the array.
We could make it even quicker if we assume that email addresses are unique (in this spoof data they aren’t, and in real life it is a dangerous assumption!).
We can also use the index to ‘cover’ the retrieval of the ‘Full Name’ field, so that MongoDB can retrieve this value from the index rather than to retrieve it from the database, but the proportion of time saved will be slight.
One reason that index retrievals work so well is that they tend to get much better hit rates in cache than full collection scans. However, if all of the collection can fit in cache then a collection scan will perform closer to index speeds.
Using aggregations
Let’s see what are the most popular names in our customer list, using an aggregation. We’ll provide an index on “Name.Last Name”.
db.Customers.aggregate({$project :{"Name.Last Name": 1}},
{$group :{_id: "$Name.Last Name", count : {$sum: 1}}},
{$sort : {count : -1}},
{$limit:10}
);
So in our top ten, we have a lot of the Snyder family:
{ "_id" : "Snyder", "count" : 83 }
{ "_id" : "Baird", "count" : 81 }
{ "_id" : "Evans", "count" : 81 }
{ "_id" : "Andrade", "count" : 81 }
{ "_id" : "Woods", "count" : 80 }
{ "_id" : "Burton", "count" : 79 }
{ "_id" : "Ellis", "count" : 77 }
{ "_id" : "Lutz", "count" : 77 }
{ "_id" : "Wolfe", "count" : 77 }
{ "_id" : "Knox", "count" : 77 }
This took only 8 Ms despite doing a COLLSCAN because the entire database could be held in cached memory.
It uses the same query plan even if you do the aggregation on an unindexed field. (Elisha, Eric, Kim, and Lee are the popular first names!)
I wonder which first names tend to attract the most notes on their file?
db.Customers.aggregate(
{$group: {_id: "$Name.First Name", NoOfNotes: {$avg: {$size: "$Notes"}}}},
{$sort : {NoOfNotes : -1}},
{$limit:10}
);
In my spoof data, it is people called Charisse that get the most notes. Here we know that a COLLSCAN is inevitable as the number of notes will change in a live system. Some databases allow indexes on computed columns but this wouldn’t help here.
{ "_id" : "Charisse", "NoOfNotes" : 1.793103448275862 }
{ "_id" : "Marian", "NoOfNotes" : 1.72 }
{ "_id" : "Consuelo", "NoOfNotes" : 1.696969696969697 }
{ "_id" : "Lilia", "NoOfNotes" : 1.6666666666666667 }
{ "_id" : "Josephine", "NoOfNotes" : 1.65625 }
{ "_id" : "Willie", "NoOfNotes" : 1.6486486486486487 }
{ "_id" : "Charlton", "NoOfNotes" : 1.6458333333333333 }
{ "_id" : "Kristi", "NoOfNotes" : 1.6451612903225807 }
{ "_id" : "Cora", "NoOfNotes" : 1.64 }
{ "_id" : "Dominic", "NoOfNotes" : 1.6363636363636365 }
The performance of aggregations can be improved by an index because they can cover the aggregation. Only the $match and $sort pipeline operators can take advantage of an index directly, and then only if they occur at the beginning of the pipeline.
SQL Data Generator was used to generate the test data in this tutorial.
Conclusions
- When you are developing an indexing strategy for MongoDB, you’ll find that there are a number of factors to take into account, such as the structure of the data, the pattern of usage, and the configuration of the database servers.
- MongoDB generally uses just one index when executing a query, for both searching and sorting; and if it gets a choice of strategy, it will sample the best candidate indexes.
- Most collection of data have some fairly good candidates for indexes, which are likely to differentiate clearly between documents in the collection, and which are likely to be popular in performing searches.
- It is a good idea to be parsimonious with indexes because they come at a minor cost in terms of resources. A bigger danger is to forget what is already there, though thankfully it isn’t possible to create duplicate indexes in MongoDB.
- It is still possible to create several compound indexes that are very close in their constitution. If an index isn’t used, it is best to drop it.
- Compound indexes are very good at supporting queries. These use the first field to do the search and then use the values in the other fields to return the results, rather than having to get the values from the documents. They also support sorts that use more than one field, as long as that are in the right order.
- For indexes to be effective for string comparisons, they need to use the same collation.
- It is worth keeping an eye on the performance of queries. As well as using the values returned from explain(), it pays to time queries, and check for long-running queries by enabling profiling and examining the slow queries. It is often surprisingly easy to transform the speed of such queries by providing the right index.
FAQs About MongoDB Indexes
Explore more about MongoDB Indexes
Interested in learning more about MongoDB indexes? Check out these related knowledge base articles:
How to Optimize MongoDB Queries Using find() & Indexes
How to Use the MongoDB Profiler and explain() to Find Slow Queries
Visual Explain | MongoDB Explain, Visualized
This article was originally published by Phil Factor and has since been updated.